Цели обучения
В предыдущей теме мы рассматривали только дискретные случайные величины. В данной главе рассматривается понятие непрерывной случайной величины , а также несколько конкретных распределений. Нормальное — непрерывное распределение и два дискретных — биномиальное и распределение Пуассона. Приведем некоторые свойства и примеры применения. В результате освоения материала данной темы вы сможете:
, а также несколько конкретных распределений. Нормальное — непрерывное распределение и два дискретных — биномиальное и распределение Пуассона. Приведем некоторые свойства и примеры применения. В результате освоения материала данной темы вы сможете:
-
понимать технику работы с непрерывными случайными величинами;
-
идентифицировать ситуации, адекватно моделируемые данными тремя распределениями или их комбинациями;
-
познакомитесь с возможностями Excel для работы с этими распределениями.
Это непрерывное симметричное распределение, которое определяется двумя параметрами — математическим ожиданием (положение вершины) и дисперсией (высота пика).
Непрерывные распределения и функции плотности распределения вероятностей
Для непрерывных распределений вводится понятие функции плотности распределения вероятностей, которое основывается на той же идее, что и гистограмма, а именно чем выше проходит функция, тем плотнее распределяются значения случайной величины на данном участке.
Теперь мы не можем приписать положительную вероятность каждой точке (их континуум), а можем говорить лишь о вероятности того, что случайная величина принимает значение из некоторого диапазона. Пример функции плотности распределения приведен на рис. 67 . Наиболее вероятны значения в районе 70. Высота функции отображает относительную вероятность. Вероятность попадания в интервал — площадь под графиком. Для вычисления вероятности попадания в интервал необходимо вычислять определенный интеграл, однако для многих распределений есть специальные таблицы и вычислительные возможности Excel. Смысл понятий математического ожидания и дисперсии для непрерывных случайных величин такой же, как и для дискретных, однако, для их вычислений необходимо использование понятия определенного интеграла.
. Наиболее вероятны значения в районе 70. Высота функции отображает относительную вероятность. Вероятность попадания в интервал — площадь под графиком. Для вычисления вероятности попадания в интервал необходимо вычислять определенный интеграл, однако для многих распределений есть специальные таблицы и вычислительные возможности Excel. Смысл понятий математического ожидания и дисперсии для непрерывных случайных величин такой же, как и для дискретных, однако, для их вычислений необходимо использование понятия определенного интеграла.
Функция плотности распределения вероятностей для нормального распределения
Для случайной величины, имеющей нормальное распределение, возможны все значения. Приведем вид функции плотности распределения.
Обычно нормальное распределение с заданными параметрами μ и σ обозначается как N(μ, σ). Примеры приведены на рис. 68.
Стандартизация: Z-значения
Стандартным нормальным распределением называют распределение N(0;1). Если мы имеем случайную величину X, нормально распределенную с параметрами μ и σ, то построим новую случайную величину Z:
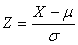
Эта операция называется стандартизацией (нормализацией). Иногда эта операция играет роль приведения величин к одному масштабу измерения. Смысл величины Z — это удаленность значения от среднеожидаемого, выраженная в стандартных отклонениях. Существует специальная функция для проведения операции стандартизации — НОРМАЛИЗАЦИЯ (STANDARDIZE).
Пример
Годовые доходности для 30 фондов приведены в файле ФОНДЫ.XLS (шаблон и решение). Вычислите Z-значения для этих доходностей и дайте им интерпретацию.
и решение). Вычислите Z-значения для этих доходностей и дайте им интерпретацию.
Решение
Результаты представлены на рис. 69. Оценки математического ожидания и стандартного отклонения вычисляются в ячейках С4 и С5 с помощью функций СРЗНАЧ и СТАНДОТКЛОН. Соответствующие Z-значения вычисляются в столбце С путем введения в ячейку С8 формулы =(В8-$C$4)/$C$5 и копированием ее в колонке С.
Альтернативным является способ ввести в ячейку D8 формулу =НОРМАЛИЗАЦИЯ(B8;$C$4;$C$5) и скопировать ее по столбцу D.
Хотя мы знаем, что Z имеет распределение N(0,1), мы проверим это в ячейках D4 и D5 с помощью функций СРЗНАЧ и СТАНДОТКЛОН, применив их к полученным результатам.
Таблицы нормального распределения и Z-значения
Практически во всех учебниках по статистике имеются специальные таблицы для стандартизованного нормального распределения. Ниже приводится фрагмент такой таблицы (рис. 70). Каждый элемент данной таблицы показывает вероятность того, что стандартизованная случайная величина не будет превосходить соответствующего значения (элементу в строке «1,3» и столбце «0,05» соответствует значение 1,35 = 1,3 + 0,05).
Например, пользуясь таблицей, можно найти вероятность того, что стандартизованная случайная величина имеет значение меньшее, чем 1,35. Согласно таблице данная вероятность равна 0,9115.
Можно решать и обратную задачу — по заданному значению вероятности попадания находить границы соответствующего интервала. Эта таблица позволяет решать подобные задачи и для не стандартизованных нормальных распределений, поскольку границы вероятностных интервалов легко вычисляются исходя из формулы стандартизации.
Недостаток таблиц в том, что они имеют шаг, а значит, требуют экстраполяции. Таблицы могут несколько отличаться по структуре.
Вычисления с нормальным распределением в Excel
Как правило, решается две задачи — поиск вероятностей по заданным границам и поиск границ вероятностных интервалов по заданным вероятностям. Первая задача решается с помощью функций НОРМРАСП (NORMDIST) (для произвольных нормальных распределений) и НОРМСТРАСП (NORMSDIST) (для стандартизованного нормального распределения). Вторая (обратная) задача решается с помощью функций НОРМОБР (NORMINV) и НОРМСТОБР (NORMNSINV). Функции =НОРМРАСП(x; μ; σ; 1) и =НОРМСТРАСП(x) возвращают вероятности того, что значение меньше x. Функции =НОРМОБР(p; μ; σ) и =НОРМСТОБР(p), где р — заданная вероятность, возвращают правые границы бесконечных (от -∞) интервалов, вероятность попадания в которые равна р.
Пример
Используя функции Excel, вычислим следующие вероятности и границы сначала для стандартизованного, а потом для общего нормального распределения.
Для N(0,1) (стандартизованное нормальное распределение) вычислим:
-
Р(Z < -2);
-
P(Z > 1);
-
P(-0,4 < Z < 1,6);
-
5%-ю границу;
-
75%-ю границу;
-
99%-ю границу.
Для N(75,8) вычислим:
-
P(X < 70);
-
P(X > 73);
-
P(75 < X < 85);
-
5%-ю границу;
-
60%-ю границу;
-
97%-ю границу.
Решение
См. файл НОРМАЛЬНОЕ.XLS (шаблон и решение) и рис. 71.
Замечания:
-
для вычисления вероятностей «более чем» используется вычитание из 1;
-
для вычисления вероятностей «между» используется вычитание значений, выдаваемых функциями;
-
для вычислений границ с вероятностями попадания «справа» используется дополнительная вероятность до единицы.
Вероятности стандартизованных диапазонов
Мы уже сталкивались в нашем курсе с диапазонами, построенными на стандартном отклонении (в примере с индексом Доу-Джонса из темы 2). Теперь становится понятным, что они связаны с нормальным распределением.
Вероятности Р (μ — kσ < X < μ + kσ) можно вычислить с помощью функций =НОРМСТРАСП(k) — НОРМСТРАСП(-k).
Подставляя вместо k последовательно 1, 2 и 3, получим P(-1 < Z < 1) = 0,6827; P(-2 < Z < 2) = 0,9545; P(-3 < Z < 3) = 0,9973.
Для нормального распределения практически все значения лежат в радиусе трех стандартных отклонений от математического ожидания (рис. 72).
Пример
Отдел по работе с персоналом крупной коммуникационной компании «Ростелеком» пересматривает свою стратегию найма. Каждый кандидат проходит экзамен, результаты которого учитываются при решении вопроса о найме. Обработка результатов показала, что количество баллов имеет приблизительно нормальное распределение с математическим ожиданием 525 и стандартным отклонением 55.
На первом шаге всех делят на три категории: автоматически зачисляемые (более 600 баллов), автоматически не зачисляемые (менее 425 баллов) и те, с кем проводится второй тур. Менеджер по персоналу хочет оценить процент по категориям. Он также хочет вычислить новые границы, при которых автоматически отсекалось бы 10% и принималось бы 15%.
Решение
См. файл ПЕРСОНАЛ.XLS (шаблон и решение) и рис. 73. Вероятность автоматического приема вычисляется в В10 по формуле =1-НОРМРАСП(B7;Среднее;СтОткл;1).
Вероятность автоматического отклонения вычисляется в В11 по формуле =НОРМРАСП(B8;Среднее;СтОткл;1).
Новые границы отсечений находим в ячейках В17 и В18 с помощью формул = НОРМОБР(1-B14;Среднее;СтОткл), = НОРМОБР(B15;Среднее;СтОткл).
Пример
Клиент инвестирует 10 000 руб. в определенные акции. Исследуя предысторию этих акций и посоветовавшись со своим брокером, он приходит к выводу, что доходность удовлетворяет нормальному закону с математическим ожиданием 10% и стандартным отклонением 4%. Доходы от акций будут обложены налогом по ставке 33%. Вычислим вероятность того, что в качестве налогов будет уплачено, по крайней мере, 400 руб. Вычислим 90%-ю верхнюю границу для чистого дохода.
Решение
Вид модели представлен на рис. 74.
См. файл НАЛОГИ.XLS (шаблон и решение). Налоги составляют 0,33(10000X)=3300X > 400 или X > 4/33, где Х — величина доходности.
Для вычисления вероятности данного события в ячейку D8 введем формулу =1 — НОРМРАСП(400/(Сумма*Ставка);Среднее;СтОткл;1).
Для ответа на второй вопрос необходимо найти x (чистый доход) из уравнения Р(X < x/6700) = 0,90, где 6700 = 10000 • (1 — 0,33).
Это второе (после нормального) по важности распределение в статистике. Оно представляет собой дискретное распределение и возникает, по крайней мере, в ситуациях двух типов:
-
делается выборка из совокупности, состоящей из элементов двух типов (например, мужчины и женщины);
-
рассматривается цепочка экспериментов, имеющие только два исхода.
Представим серию испытаний, каждое из которых имеет два возможных исхода (успех, неуспех). Вероятность успеха р, а вероятность неуспеха (1 — р) соответственно. Число испытаний — n. Пусть X — случайная величина равная количеству успешных испытаний в серии из n испытаний. Тогда X имеет биномиальное распределение с параметрами n и p.
Нас интересует вероятность каждого возможного значения случайной величины Х, то есть P(X = k). Эту вероятность можно вычислить с помощью функции БИНОМРАСП (BINOMDIST). Рассмотрим параметры функции = БИНОМРАСП(k;n;p;cum).
Если параметр cum равен 1, то получаем вероятность «не более k успехов», а если cum равен 0, то получаем вероятность «ровно k успехов».
Используется также функция КРИТБИНОМ, которая возвращает наименьшее значение «количества успехов», для которого вероятность события «не более данного количества успехов» больше или равна заданному значению.
Пример
Предположим, что 100 батареек вставлены в 100 фонариков по одной в каждый. После 8 ч. работы мы предполагаем, что батарейка работает с вероятностью 0,6 и не работает с вероятностью 0,4. Успех в данном случае — это работа батарейки после 8 ч. Найдем вероятности следующих событий:
1) успехов ровно 58;
2) не более 65 успехов;
3) менее 70 успехов;
4) по крайней мере, 59 успехов;
5) более 65 успехов;
6) между 55 и 65 успехов (включительно);
7) ровно 40 неуспехов;
8) по крайней мере, 35 неуспехов;
9) менее 42 неуспехов.
Во многих управленческих задачах распределение Пуассона играет важную роль. Например, вероятностные модели управления запасами, моделирование очередей, вероятностные модели надежности и т.д.
Найдем также наименьшее значение «количества успехов», для которого вероятность события «не более данного количества успехов» больше или равна 0,95.
Решение
Смотрите файл БИНОМИАЛЬНОЕ.XLS (шаблон и решение) и рис. 75.
Первые шесть вопрос решаются с использованием следующих вероятностей:
1) Р(X = 58);
2) P(X ≤ 65);
3) P(X < 70) = P(X ≤ 69);
4) P(X ≥ 59) = 1 — P(X < 59) = 1 — P(X ≤ 58);
5) P(X > 65) = 1 — P(X ≤ 65);
6) P(55 ≤ X ≤ 65) = P(X ≤ 65) — P(X ≤ 54).
Расчеты по этим формулам делаются в ячейках В7 — В12 с помощью функции БИНОМРАСП (рис. 75).
Для ответа на вопросы 7—9 достаточно иметь в виду, что количество «неудач» также имеет биномиальное распределение с параметрами n и (1-р).
Нахождение наименьшего значения «количества успехов» можно провести двумя способами — методом подбора (ячейки B21:B26), или с помощью функции КРИТБИНОМ (ячейка В28).
Математическое ожидание и стандартное отклонение для биномиального распределения
Математическое ожидание биномиального распределения вычисляется по формуле:
E(X) = np
Стандартное отклонение биномиального распределения вычисляется по формуле:
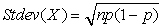
Биномиальное распределение в контексте выборок
Имеется некоторая совокупность, состоящая из N элементов двух типов, например, женщины и мужчины. Пусть А — количество мужчин, а В — количество женщин. Тогда А + В = N. Производится случайная выборка размера n. Будет ли количество выбранных мужчин подчиняться биномиальному закону распределения с параметрами n и p = A / N.
Ответ на этот вопрос зависит от способа проведения выборки.
Если выбираемый объект снова возвращается в совокупность и может быть выбран повторно, то такой способ организации выборки назовем выборка с возвратами. В этом случае распределение будет биномиальным.
Если же выбираемый объект не возвращается в совокупность и не может быть выбран повторно, то такой способ организации выборки назовем выборка без возвратов. В этом случае распределение не будет биномиальным. Такое распределение носит название гипергеометрического.
При малых значениях n по отношению к N (например, не более 10%) гипергеометрическое распределение близко к биномиальному.
Приближение биномиального распределения с помощью нормального
Если значение n достаточно велико, а значение р не очень близко к 0 или 1, то график плотности распределения биномиального распределения напоминает график для нормального. См. рис. 76 для значений n = 30 и p = 0,4.
Может быть предложено следующее правило. Если np > 5 и n(1 - p) > 5, то биномиальное распределение можно приблизить нормальным с математическим ожиданием np и стандартным отклонением 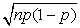 .
.
Практически это полезно с той точки зрения, что можно применять правила областей.
Биномиальное распределение часто применяется в бизнес-расчетах.
Пример
Покупатели супермаркета «Перекресток» тратят на покупки различные суммы. Анализ данных показал, что суммы покупок распределены по нормальному закону с математическим ожиданием 85 руб. и стандартным отклонением 30 руб. Если предположить, что в некоторый день магазин посещает 500 покупателей, то вычислите математическое ожидание и стандартное отклонение для количества покупателей, потративших по крайней мере 100 руб. Вычислите также вероятность, что по крайней мере 30% покупателей потратили не менее 100 руб.
Решение
Поскольку сумма покупки имеет нормальное распределение, вероятность того, что эта сумма будет не меньше 100 руб., вычисляется с помощью формулы =1-НОРМРАСП (100;НормСреднее;НормСтОткл;1), размещенной в ячейке В8. (См. файл ПЕРЕКРЕСТОК.XLS (шаблон и решение) и рис. 78).
Эта вероятность р используется далее как параметр в биномиальной модели. Математическое ожидание и стандартное отклонение вычисляются по известным формулам в ячейках В16 и В19.
Для ответа на второй вопрос заметим, что 30% от 500 составляет 150. Тогда искомая величина есть вероятность, что биномиальная величина с параметрами n = 500 и p = 0,309 принимает значение не меньшее 150. Эта вероятность вычисляется с помощью формулы =1-БИНОМРАСП (0,3*КолПокуп-1;КолПокуп;ВерНеМен100;1) в ячейке В23.
Пример
Этот пример в некотором упрощенном варианте показывает расчет стратегии продажи авиабилетов, применяемый авиакомпаниями. Понимая, что определенный процент пассажиров в последний момент откажется от полета, и стремясь избежать в этом случае пустых мест, авиакомпании продают несколько большее количество билетов. Мы предположим, что средняя доля отказавшихся от полета пассажиров составляет 5%. Другими словами, каждый пассажир независимо от других летит с вероятностью 0,95 и не летит с вероятностью 0,05. Предположим, что число посадочных мест составляет 200. Компания хочет исследовать, как зависят от числа проданных билетов некоторые вероятности. В частности, вероятность того, что полетят более 205 человек; вероятность того, что полетят более 200 человек; вероятность того, что по крайней мере 195 мест будет заполнено; вероятность того, что по крайней мере 190 мест будет заполнено и т.д.
Решение
Для решения данной задачи воспользуемся специальной встроенной функцией биномиального распределения БИНОМРАСП (см. файл СВЕРХПРОДАЖА.XLS (шаблон и решение). Построим таблицу с одним входным параметром — количеством проданных билетов (ячейка В6), в которой будут вычисляться все четыре искомые вероятности (рис. 79).
Вычислим искомые вероятности в ячейках ряда 10 с помощью формулы (для ячейки В10) =1-БИНОМРАСП (205;КолБилет;1-ВерНеявки;1).
Для того чтобы видеть вероятности для различных количеств проданных билетов, создадим таблицу для выбранных значений, например 206, 209, 212 и т.д.
Естественно, что с ростом количества проданных билетов растет вероятность отказа некоторым пассажирам, а с уменьшением — вероятность иметь пустые места. Для принятия конкретных решений необходимо привлекать дополнительные финансовые соображения. Можно было бы оценить положительный финансовый эффект от уменьшения числа среднеожидаемых свободных мест и отрицательный финансовый и нефинансовый эффект от возрастания числа пассажиров, оставшихся без места. Далее возможно рассмотрение модели нахождения оптимального баланса.
Во многих управленческих задачах распределение Пуассона играет важную роль. Например, вероятностные модели управления запасами, моделирование очередей, вероятностные модели надежности и т.д.
Распределение Пуассона — это дискретное распределение, принимающее значение 0, 1, 2, …и т.д.
Распределение задается одним положительным параметром λ, который является одновременно и математическим ожиданием, и дисперсией. Примерный вид распределения показан на рис. 80.
В основном это распределение возникает при оценке количества событий, происходящих за определенный промежуток времени. Вот серия типичных примеров.
-
Менеджер банка изучает времена прихода клиентов. Количество клиентов, пришедших в течение часа, имеет распределение Пуассона, где λ — среднее ожидаемое количество клиентов в час.
-
Устройство использует батарейки. Если батарейка выходит из строя, ее сразу заменяют другой (устройство работает непрерывно). Количество батареек, вышедших из строя за месяц, имеет распределение Пуассона, где λ — среднее ожидаемое количество батареек, вышедших из строя за месяц.
-
Мастера интересует количество запчастей определенного типа, потребляемых в течение недели. Количество запросов на эту деталь имеет распределение Пуассона, где λ — среднее ожидаемое количество запрашиваемых деталей.
-
Распределение Пуассона часто используется для описания количества дефектов на некоторой площади. Например, количество дефектов покраски на капоте автомобиля.
Для расчета вероятностей распределения Пуассона в Excel используется функция ПУАССОН (POISSON). Рассмотрим параметры функции =ПУАССОН(k;λ;cum).
Если последний параметр данной функции равен 0, то вычисляется Р(Х = k), а если он равен 1, то вычисляется Р(Х ≤ k).
Пример
Компания «ТВ-СБЫТ» является региональной базой по продаже телевизоров различных марок. Одна из самых сложных менеджерских задач — это определить величину запаса по каждому типу. С одной стороны, хочется иметь много, чтобы удовлетворить запрос любого покупателя. С другой, излишние запасы — это замороженные деньги и занимаемые складские площади.
Основная трудность возникает из-за неопределенности спроса, который меняется случайным образом из месяца в месяц. Известен только среднемесячный спрос — 17 телевизоров. Приглашенный консультант предполагает использовать вероятностную модель. Как он мог бы действовать?
Решение
Исходные данные и решение задачи представлены на рис. 81.
Пусть Х — это спрос за месяц. Консультант, анализируя данные, построил гистограмму спроса за предыдущие месяцы. Она выглядела приблизительно так, как на рис. 80. Консультант предполагает использовать распределение Пуассона с λ = 17. Далее нужно сравнить вероятности, полученные из реальных данных, и вероятности, полученные из распределения Пуассона (см. файл ТВ-СБЫТ.XLS (шаблон и решение). Если нет хорошего соответствия, то нужно подбирать другой параметр или другое распределение.
Нормальное, биномиальное и распределение Пуассона являются наиболее важными в статистических методах обработки данных, однако существует много других: экспоненциальное, Эрланга, логарифмически нормальное, логистическое и т.д. Как выбрать наиболее подходящее?
В общем случае строим гистограмму и выбираем теоретическое распределение, функция плотности распределения вероятностей которого наиболее приближается к данной гистограмме. Для этого применяем, например, программный инструмент BestFit (Decision Tools).
Пример
Супермаркет собрал времена обслуживания более 100 покупателей (см. файл ВРЕМЯ ОБСЛУЖИВАНИЯ.XLS (шаблон и решение). Это время изменяется от 40 сек. до 279 сек. со средним значением и медианой около 2,5 мин.
Менеджер хочет определить, соответствуют ли эти данные нормальному распределению, или есть более подходящие распределения?
Решение
Войдем в расширение BestFit через панель Пуск. Далее зайдем в Excel, в файл ВРЕМЯ ОБСЛУЖИВАНИЯ.XLS (шаблон и решение) и загрузим в буфер массив, содержащий время обслуживания. В табл. 22 представлен фрагмент данных, а также описательная статистика данной выборки.
Таблица 22.
Время обслуживания и обобщающие характеристики
Пос-ль |
Время |
|
|
1 |
131 |
|
|
2 |
101 |
|
|
3 |
178 |
|
Время |
4 |
246 |
|
|
5 |
207 |
Среднее |
159,24 |
6 |
155 |
Стандартная ошибка |
4,95 |
7 |
95 |
Медиана |
155,00 |
8 |
105 |
Мода |
155,00 |
9 |
168 |
Стандартное отклонение |
52,61 |
10 |
92 |
Дисперсия выборки |
2767,67 |
11 |
112 |
Эксцесс |
-0,67 |
12 |
163 |
Асимметричность |
0,09 |
13 |
197 |
Интервал |
239,00 |
14 |
97 |
Минимум |
40,00 |
15 |
144 |
Максимум |
279,00 |
16 |
100 |
Сумма |
17994,00 |
17 |
233 |
Счет |
113,00 |
18 |
146 |
|
|
19 |
220 |
|
|
20 |
214 |
|
|
21 |
138 |
|
|
22 |
40 |
|
|
Далее загрузим с помощью команды Edit/Paste этот массив в окно расширения.
Количество категорий изменим с 10 до 15. Вызовем BestFit's Wizard (Мастер приближений). Выберем опцию Continuous, что означает поиск в классе непрерывных распределений (рис. 82).
Далее программа производит ранжирование распределений в порядке качества приближения. Если мы выбрали опцию «открытой границы», то наилучшим приближением будет нормальное распределение. Выделив нормальное распределение и нажав на Graph, получим график приближения (рис. 83).
Если же в качестве нижней границы выбрать 0 (все времена обслуживания действительно неотрицательные), то наилучшим будет приближение Вейбула (рис. 84).
Через клавишу Stats на панели мастера приближений можно посмотреть количественные характеристики приближения (рис. 85).
Мы рассмотрели три основные распределения — нормальное, биномиальное и распределение Пуассона, а также примеры конкретных задач, связанных с данными распределениями. Мы также познакомились с инструментами работы в Excel с данными распределениями.
Кроме того, мы познакомились с техникой подбора наиболее адекватного закона распределения с помощью инструмента BestFit.
