Цели обучения
Статистика рассматривает следующие две основные задачи:
-
У нас есть некоторая оценка, построенная на выборочных данных, и мы хотим сделать некоторое вероятностное утверждение относительно того, где находится истинное значение оцениваемого параметра.
-
У нас есть конкретная гипотеза, которую необходимо проверить на основе выборочных данных.
В данной теме мы рассматриваем первую задачу. Введем также определение доверительного интервала.
Доверительный интервал — это интервал, который строится вокруг оценочного значения параметра и показывает, где находится истинное значение оцениваемого параметра с априори заданной вероятностью.
Изучив материал данной темы, Вы:
-
узнаете, что такое доверительный интервал оценки;
-
научитесь классифицировать статистические задачи;
-
освоите технику построения доверительных интервалов, как по статистическим формулам, так и с помощью программного инструментария;
-
научитесь определять необходимые размеры выборок для достижения определенных параметров точности статистических оценок.
Т-распределение
Как обсуждали выше распределение случайной величины 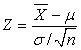 близко к стандартизованному нормальному распределению с параметрами 0 и 1. Поскольку нам не известна величина σ, мы заменяем ее на некоторую оценку s. Величина
близко к стандартизованному нормальному распределению с параметрами 0 и 1. Поскольку нам не известна величина σ, мы заменяем ее на некоторую оценку s. Величина 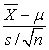 уже имеет другое распределение, а именно t-распределение
уже имеет другое распределение, а именно t-распределение или Распределение Стьюдента, которое определяется параметром n-1 (число степеней свободы). Это распределение близко к нормальному распределению (чем больше n, тем распределения ближе).
или Распределение Стьюдента, которое определяется параметром n-1 (число степеней свободы). Это распределение близко к нормальному распределению (чем больше n, тем распределения ближе).
На рис. 95 представлено распределение Стьюдента с 30 степенями свободы. Как видно, оно весьма близко к нормальному распределению.
представлено распределение Стьюдента с 30 степенями свободы. Как видно, оно весьма близко к нормальному распределению.
Иногда по выборочным данным требуется оценить не математическое ожидание, а общую сумму значений. Например, в ситуации с аудитором интерес может представлять оценка не средней величины счета, а суммы всех счетов.
Аналогично функциям для работы с нормальным распределением НОРМРАСП и НОРМОБР имеются функции для работы с t-распределением — СТЬЮДРАСП (TDIST) и СТЬЮДРАСПОБР (TINV). Пример использования этих функций можно посмотреть в файле СТЬЮДРАСП.XLS (шаблон и решение) и на рис. 96.
и решение) и на рис. 96.
Распределения других характеристик
Как мы уже знаем, для определения точности оценивания математического ожидания нам необходимо t-распределение. Для оценивания других параметров, например, дисперсии, требуются другие распределения. Два из них — это F-распределение и x2 -распределение.
Доверительный интервал — это интервал, который строится вокруг оценочного значения параметра и показывает, где находится истинное значение оцениваемого параметра с априори заданной вероятностью.
Построение доверительного интервала для среднего значения происходит следующим образом:
-
выбирается некоторый вероятностный уровень достоверности
— 90, 95, 99% или любой другой; -
определяется некоторый параметр α, который получается вычитанием из 1 уровня достоверности, записанного в десятичном виде;
-
определяются значения tα , которые являются границами отсечения «хвостов» с вероятностями α / 2 для t-распределения с n-1 степенью свободы;
-
вычисляются границы доверительного интервала по формуле:
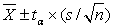 .
.Пример
В ресторане быстрого обслуживания планируется расширить ассортимент новым видом сэндвича. Для того чтобы оценить спрос на него, менеджер случайным образом планирует выбрать 40 посетителей из тех, кто уже попробовал его и предложить им оценить их отношение к новому продукту в баллах от 1 до 10. Менеджер хочет оценить ожидаемое количество баллов, которое получит новый продукт и построить 95%-й доверительный интервал этой оценки. Как это осуществить? (см. файл СЭНДВИЧ1.XLS (шаблон и решение).
Решение
Для решения данной задачи можно воспользоваться StatPro/Statistical Inference/One-Sample Analysis. Результаты представлены на рис. 97.
Иногда по выборочным данным требуется оценить не математическое ожидание, а общую сумму значений. Например, в ситуации с аудитором интерес может представлять оценка не средней величины счета, а суммы всех счетов.
Пусть N — общее количество элементов, n — размер выборки, T3
— сумма значений в выборке, T' — оценка для суммы по всей совокупности, тогда 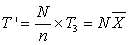 , а доверительный интервал вычисляется по формуле
, а доверительный интервал вычисляется по формуле 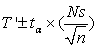 , где s — оценка стандартного отклонения для выборки,
, где s — оценка стандартного отклонения для выборки, 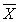 — оценка среднего для выборки.
— оценка среднего для выборки.
Пример
Допустим, некоторая налоговая служба хочет оценить размер суммарных налоговых возвратов для 10 000 налогоплательщиков. Налогоплательщик либо получает возврат, либо доплачивает налоги. Найдите 95%-й доверительный интервал для суммы возврата при условии, что размер выборки составляет 500 человек (см. файл СУММА ВОЗВРАТОВ.XLS (шаблон и решение).
Решение
В StatPro нет специальной процедуры для этого случая, однако можно заметить, что границы можно получить из границ для среднего исходя из вышеприведенных формул (рис. 98).
Пусть p — математическое ожидание доли клиентов, а рв
— оценка этой доли, полученная по выборке размера n. Можно показать, что для достаточно больших 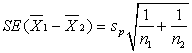 распределение оценки будет близко к нормальному с математическим ожиданием p и стандартным отклонением
распределение оценки будет близко к нормальному с математическим ожиданием p и стандартным отклонением 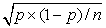 . Стандартная ошибка оценки в данном случае выражается как
. Стандартная ошибка оценки в данном случае выражается как 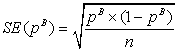 , а доверительный интервал как
, а доверительный интервал как 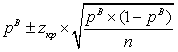 .
.
Пример
В ресторане быстрого обслуживания планируется расширить ассортимент новым видом сэндвича. Для того чтобы оценить спрос на него, менеджер случайным образом выбрал 40 посетителей из тех, кто уже попробовал его и предложил им оценить их отношение к новому продукту в баллах от 1 до 10. Менеджер хочет оценить ожидаемую долю клиентов, которые оценивают новый продукт не менее чем в 6 баллов (он ожидает, что именно эти клиенты и будут потребителями нового продукта).
Решение
Первоначально создаем новый столбец по признаку 1, если оценка клиента была больше 6 баллов и 0 иначе (см. файл СЭНДВИЧ2.XLS (шаблон и решение).
Способ 1
Подсчитывая количество 1, оцениваем долю, а далее используем формулы.
Значение zкр берется из специальных таблиц нормального распределения (например, 1,96 для 95%-го доверительного интервала).
Используя данный подход и конкретные данные для построения 95%-го интервала, получим следующие результаты (рис. 99). Критическое значение параметра zкр
равно 1,96. Стандартная ошибка оценки — 0,077. Нижняя граница доверительного интервала — 0,475. Верхняя граница доверительного интервала — 0,775. Таким образом, менеджер вправе полагать с 95%-й долей уверенности, что процент клиентов, оценивших новый продукт на 6 баллов и выше, будет между 47,5 и 77,5.
Способ 2
Данная задача допускает решение стандартными средствами StatPro. Для этого достаточно заметить, что доля в данном случае совпадает со средним значением столбца Тип. Далее применим StatPro/Statistical Inference/One-Sample Analysis для построения доверительного интервала среднего значения (оценки математического ожидания) для столбца Тип. Полученные в этом случае результат, будут весьма близок к результату 1-го способа (рис. 99).
В качестве оценки стандартного отклонения используется s (формула приведена в разделе 1). Функцией плотности распределения оценки s является функция хи-квадрат, которая, как и t-распределение, имеет n-1 степень свободы. Имеются специальные функции для работы с этим распределением ХИ2РАСП (CHIDIST) и ХИ2ОБР (CHIINV).
Доверительный интервал в этом случае уже будет не симметричным. Условная схема границ представлена на рис. 100.
Пример
Станок должен производить детали диаметром 10 см. Однако в силу различных обстоятельств происходят ошибки. Контролера по качеству волнуют два обстоятельства: во-первых, среднее значение должно равняться 10 см; во-вторых, даже в этом случае, если отклонения будут велики, то многие детали будут забракованы. Ежедневно он делает выборку из 50 деталей (см. файл КОНТРОЛЬ КАЧЕСТВА.XLS (шаблон и решение). Какие выводы может дать такая выборка?
Решение
Построим 95%-й доверительные интервалы для среднего и для стандартного отклонения с помощью StatPro/Statistical Inference/ One-Sample Analysis (рис. 101).
Далее, используя предположение о нормальном распределении диаметров, рассчитаем долю бракованных изделий, задавшись предельным отклонением 0,065. Используя возможности таблицы подстановки (случай двух параметров), построим зависимость доли брака от среднего значения и стандартного отклонения (рис. 102).
Это одно из наиболее важных применений статистических методов. Примеры ситуаций.
-
Менеджер магазина одежды хотел бы знать, на сколько больше или меньше тратит в магазине средняя женщина-покупатель, чем мужчина.
-
Две авиакомпании летают аналогичными маршрутами. Организация-потребитель хотела бы сравнить разницу между среднеожидаемыми временами задержек рейсов по обеим авиакомпаниям.
-
Компания рассылает купоны на отдельные виды товаров в одном городе и не рассылает в другом. Менеджеры хотят сравнить средние объемы покупок этих товаров в ближайшие два месяца.
-
Автомобильный дилер часто имеет дело на презентациях с замужними парами. Чтобы понять их персональную реакцию на презентацию, пары часто опрашивают отдельно. Менеджер хочет оценить разницу в рейтингах указываемых мужчинами и женщинами.
Случай независимых выборок
Разность средних значений будет иметь t-распределение с n1 + n2 — 2 степенями свободы. Доверительный интервал для μ1 — μ2 выражается соотношением:

Данная задача допускает решение не только по вышеприведенным формулам, но и стандартными средствами StatPro. Для этого достаточно применить StatPro/Statistical Inference/Two-Sample Analysis для построения доверительного интервала разности двух средних значений.
Пусть 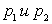 — математическое ожидание долей. Пусть
— математическое ожидание долей. Пусть 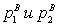 — их выборочные оценки, построенные по выборкам размера n1
и n2
соответственно. Тогда
— их выборочные оценки, построенные по выборкам размера n1
и n2
соответственно. Тогда 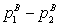 является оценкой для разности
является оценкой для разности 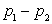 . Следовательно, доверительный интервал этой разности выражается как:
. Следовательно, доверительный интервал этой разности выражается как:
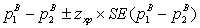
Здесь zкр является значением, полученным из нормального распределения по специальным таблицам (например, 1,96 для 95%-й доверительного интервала).
Стандартная ошибка оценки выражается в данном случае соотношением:
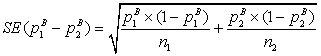 .
.Пример
Магазин, готовясь к большой распродаже, предпринял следующие маркетинговые исследования. Были выбраны 300 лучших покупателей, которые в свою очередь были случайным образом поделены на две группы по 150 членов в каждой. Всем из отобранных покупателей были разосланы приглашения для участия в распродаже, но только для членов первой группы был приложен купон, дающий право на скидку 5%. В ходе распродажи покупки всех 300 отобранных покупателей фиксировались. Каким образом менеджер может интерпретировать полученные результаты и сделать заключение об эффективности предоставления купонов? (см. файл КУПОНЫ.XLS (шаблон и решение)).
Решение
Для нашего конкретного случая из 150 покупателей, получивших купон на скидку, 55 сделали покупку на распродаже, а среди 150, не получивших купон, покупку сделали только 35 (рис. 103). Тогда значения выборочных пропорций соответственно 0,3667 и 0,2333. А выборочная разность между ними равна соответственно 0,1333. Полагая доверительный интервал 95%-м, находим по таблице нормального распределения zкр
= 1,96. Вычисление стандартной ошибки выборочной разности равно 0,0524. Окончательно получаем, что нижняя граница 95%-го доверительного интервала равна 0,0307, а верхняя граница 0,2359 соответственно. Полученные результаты можно интерпретировать таким образом, что на каждых 100 покупателей, получивших купон со скидкой, можно ожидать от 3 до 23 новых покупателей. Однако надо иметь в виду, что этот вывод сам по себе еще не означает эффективности применения купонов (поскольку, предоставляя скидку, мы теряем в прибыли!). Продемонстрируем это на конкретных данных. Предположим, что средний размер покупки равен 400 руб., из которых 50 руб. есть прибыль магазина. Тогда ожидаемая прибыль на 100 покупателях, не получивших купон, равна:
50 • 0,2333 • 100 = 1166,50 руб.
Аналогичные вычисления для 100 покупателей получивших купон, дают:
30 • 0,3667 • 100 = 1100,10 руб.
Уменьшение средней прибыли до 30 объясняется тем, что, используя скидку, покупатели, получившие купон, в среднем будут делать покупку на 380 руб.
Таким образом, итоговый вывод говорит о неэффективности использования таких купонов в данной конкретной ситуации.
Замечание. Данная задача допускает решение стандартными средствами StatPro. Для этого достаточно свести данную задачу к задаче оценки разности двух средних способом, а далее применить StatPro/Statistical Inference/Two-Sample Analysis для построения доверительного интервала разности двух средних значений.
Длина доверительного интервала зависит от следующих условий:
-
непосредственно данных (стандартное отклонение);
-
уровня значимости;
-
размера выборки.
Сначала рассмотрим задачу в общем случае. Обозначим данное нам значение половины длины доверительного интервала за В (рис. 104). Нам известно, что доверительный интервал для среднего значения некоторой случайной величины X выражается как 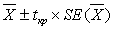 , где
, где 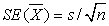 . Полагая:
. Полагая:
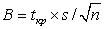 и выражая
и выражая 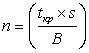 .
.К сожалению, точное значение дисперсии случайной величины X нам не известно. Кроме этого, нам неизвестно и значение tкр , так как оно зависит от n через количество степеней свободы. В данной ситуации мы можем поступить следующим образом. Вместо дисперсии s используем какую-либо оценку дисперсии, по каким-либо имеющимся реализациям исследуемой случайной величины. Вместо значения tкр используем значение zкр для нормального распределения. Это вполне допустимо, поскольку функции плотности распределений для нормального и t-распределения очень близки (за исключением случая малых n). Таким образом, искомая формула принимает вид:
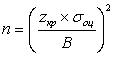 .
.Поскольку формула дает, вообще говоря, нецелочисленные результат, в качестве искомого размера выборки берется округление с избытком результата.
Пример
В ресторане быстрого обслуживания планируется расширить ассортимент новым видом сэндвича. Для того чтобы оценить спрос на него, менеджер случайным образом планирует выбрать некоторое количество посетителей из тех, кто уже попробовал его, и предложить им оценить их отношение к новому продукту в баллах от 1 до 10. Менеджер хочет оценить ожидаемое количество баллов, которое получит новый продукт и построить 95%-й доверительный интервал этой оценки. При этом он хочет, чтобы половина ширины доверительного интервала не превышала 0,3. Какое количество посетителей ему необходимо опросить?
Решение
В нашем конкретном примере мы можем воспользоваться данными по 40 посетителям из примера (см. файл СЭНДВИЧ1.XLS (шаблон и решение), стандартное отклонение для которых было оценено как 1,597. В качестве zкр
берем 1,96, а в качестве В подставляем 0,3. Получаем по формуле n = 108,86. Следовательно, искомый размер выборки составляет 109.
-
Формула для размера выборки при оценке доли выглядит следующим образом:
Здесь роц — оценка доли p, а В есть заданная половина длины доверительного интервала. Завышенное значение для n можно получить, используя значение роц = 0,5. В этом случае длина доверительного интервала не будет превосходить заданного значения В при любом истинном значении p.
Пример
Пусть менеджер из предыдущего примера планирует оценить долю клиентов, отдавших предпочтение новому виду продукции. Он хочет построить 90%-й доверительный интервал, половина длины которого не превосходила бы 0,05. Сколько клиентов должно войти в случайную выборку?
Решение
В нашем случае значение zкр = 1,645. Поэтому искомое количество вычисляется как
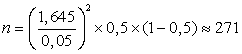 .
.Если бы менеджер имел основания полагать, что искомое значение p составляет, например, примерно 0,3, то, подставляя это значение в вышеприведенную формулу, мы получили бы меньшее значение величины случайной выборки, а именно 228.
-
Формула для определения размеров случайной выборки в случае разности между двумя средними значениями записывается как:
Когда делается оценка некоторых параметров совокупности по выборочным данным, полезно дать не только точечную оценку параметра, но и указать доверительный интервал, который показывает, где может находиться точное значение оцениваемого параметра.
Пример
Некоторая компьютерная компания имеет сервисный центр по обслуживанию клиентов. В последнее время увеличилось количество жалоб клиентов на плохое качество обслуживания. В сервисном центре в основном работают сотрудники двух типов: не имеющие большого опыта, но закончившие специальные подготовительные курсы, и имеющие большой практический опыт, но не закончившие специальных курсов. Компания хочет проанализировать нарекания клиентов за последние полгода и сравнить их средние количества, приходящиеся на каждую из двух групп сотрудников. Предполагается, что количества в выборках по обеим группам будут одинаковые. Какое количество сотрудников необходимо включить в выборку, чтобы получить 95%-й интервал с половиной длины не более 2?
Решение
Здесь σоц есть оценка стандартного отклонения обеих случайных переменных в предположении, что они близки. Таким образом, в нашей задаче нам необходимо каким-то образом получить эту оценку. Это можно сделать, например, следующим образом. Просмотрев данные по нареканиям клиентов за последние полгода, менеджер может заметить, что на каждого сотрудника в основном приходится от 6 до 36 нареканий. Зная, что для нормального распределения практически все значения удалены от среднего значения не более чем на три стандартных отклонения, он может с определенным основанием полагать, что:
-
Формула для определения размера случайной выборки в случае оценки разности между долями имеет вид:
Пример
Некоторая компания имеет две фабрики по производству аналогичной продукции. Менеджер компании хочет сравнить доли бракованной продукции на обеих фабриках. По имеющейся информации процент брака на обеих фабриках составляет от 3 до 5%. Предполагается построить 99%-й доверительный интервал с половиной длины не более 0,005 (или 0,5%). Какое количество изделий необходимо отобрать с каждой фабрики?
Решение
Здесь р1оц и р2оц являются оценками двух неизвестных долей брака на 1-й и 2-й фабрике. Если положить р1оц = р2оц = 0,5, то мы получим завышенное значение для n. Но поскольку в нашем случае мы имеем некоторую априорную информацию об этих долях, то мы берем верхнюю оценку этих долей, а именно 0,05. Получаем
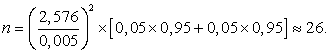
Когда делается оценка некоторых параметров совокупности по выборочным данным, полезно дать не только точечную оценку параметра, но и указать доверительный интервал, который показывает, где может находиться точное значение оцениваемого параметра.
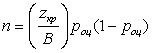
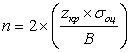 .
.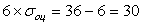 , откуда
, откуда 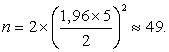 .
.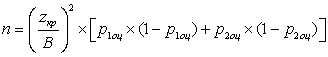
В данной главе мы также познакомились с количественными соотношениями, позволяющими строить такие интервалы для различных параметров; узнали способы управления длиной доверительного интервала.
Отметим также, что задачу оценки размеров выборки (задача планирования эксперимента) можно решить, используя стандартные средства StatPro, а именно StatPro/Statistical Inference/Sample Size Selection.
