Handbook по дисциплине
«Эконометрика»
Программа магистерской подготовки по направлению
«Финансовый менеджмент»
Кафедра Математических методов принятия решений
Пантина И.В.
Handbook по дисциплине
«Эконометрика»
Программа магистерской подготовки по направлению
«Финансовый менеджмент»
Содержание
Тема 1. Модели временных рядов
Тема 2. Модели авторегрессии и скользящего среднего
Тема 3. Модели интегрируемой авторегрессии и скользящего среднего
Тема 4. Модели авторегрессии и условной гетероскедастичности
Дисциплина «Эконометрика» магистерской программы является продолжением базового курса «Эконометрика» программы бакалавриата. Отличительной особенностью является то, что содержание курса нацелено на изучение и приобретение практических навыков в области анализа временных рядов такой структуры, которая характерна для обменных курсов валют, доходности облигаций, фондовых индексов и других показателей деятельности финансовых институтов.
Обобщая систему знаний, полученных в результате освоения слушателем курсов математического моделирования, статистики и прогнозирования, финансового менеджмента и инвестиций, курс эконометрики позволяет сформировать системное видение, а также выявить количественные взаимосвязи и причинно-следственные связи между процессами.
Цель дисциплины: освоить эконометрические методы моделирования показателей деятельности финансовых институтов.
Задачи изучения дисциплины:
· сформировать представление о теоретических концепциях моделирования показателей финансовых рынков;
· развить навыки практической обработки показателей финансовых рынков, построения моделей, оценки их адекватности и использования моделей для прогноза;
· углубить представление о методах прогнозирования доходности финансовых инструментов.
В результате изучения дисциплины обучаемый должен:
Иметь представление о:
· эконометрических моделях временных рядов;
· особенностях использования эконометрических моделей для характеристики и прогнозирования финансовых временных рядов;
· методах оценки параметров моделей временных рядов;
· свойствах компонентов временных рядов.
Знать:
· виды моделей временных рядов;
· критерии, позволяющие идентифицировать структуру временного ряда;
· различные виды структур временного ряда.
Уметь:
· определять рациональную модель временного ряда;
· применять систему коэффициентов автокорреляции для определения структуры ряда;
· использовать статистические тесты для оценки стационарности и интегрируемости временного ряда;
· оценивать параметры моделей временных рядов;
· использовать модели временных рядов для прогноза.
Временной ряд – набор значений какого-либо показателя за несколько последовательных моментов или периодов времени. Каждое значение временного ряда в самом общем случае состоит из трех компонент:
·трендовой (Т);
·сезонной (S);
·случайной (E).
Как правило, уровень временного ряда можно представить как сумму или произведение трендовой, сезонной и случайной компонент.
Аддитивная модель временного ряда составляется как сумма трех указанных компонент:
Y = T + S + E
Мультипликативная модель составляется как произведение трех указанных компонент:
Y = T·S ·E
Выбор в пользу одной из двух моделей осуществляется на основе графического анализа структуры сезонных колебаний. Если амплитуда колебаний приблизительно постоянна, строят аддитивную модель временного ряда, в которой значения сезонной компоненты предполагаются постоянными для различных циклов. Если амплитуда сезонных колебаний изменяется во времени, то строят мультипликативную модель временного ряда, которая ставит уровни ряда в зависимость от значений сезонной компоненты.
При наличии во временном ряде тенденции и циклических колебаний значения каждого последующего уровня ряда зависят от предыдущих. Корреляционную зависимость между последовательными уровнями временного ряда называют автокорреляцией уровней ряда. Измерить автокорреляцию можно с помощью линейного коэффициента автокорреляции между уровнями исходного временного ряда и лаговыми значениями этого ряда.
Параметр указывает на то, что автокорреляция между уровнями определяется для различных значений лага . Графическим отображением значений коэффициентов автокорреляции разного порядка является кореллограмма.

Рис. 1. Значения коэффициентов автокорреляции и вид автокорреляционной
функции для лаговых значений от 1 до 24
Анализ автокорреляционной функции и коррелограммы позволяет определить лаг, при котором автокорреляция наиболее высокая и, следовательно, лаг, при котором связь между текущим и предыдущими уровнями ряда наиболее тесная, т.е. при помощи анализа автокорреляционной функции и коррелограммы можно выявить структуру ряда. Если наиболее высоким оказался коэффициент автокорреляции первого порядка, исследуемый ряд содержит только тенденцию. Если наиболее высоким оказался коэффициент автокорреляции порядка τ, ряд содержит циклические колебания с периодичностью в τ моментов времени. Если ни один из коэффициентов автокорреляции не является значимым, можно сделать одно из двух предположений относительно структуры этого ряда: либо ряд не содержит тенденции и циклических колебаний и имеет структуру, сходную со структурой ряда, содержащего лишь случайные колебания; либо ряд содержит сильную нелинейную тенденцию, для выявления которой нужно провести дополнительный анализ. Поэтому коэффициент автокорреляции уровней и автокорреляционную функцию целесообразно использовать для выявления во временном ряде наличия или отсутствия трендовой компоненты (T) и циклической (сезонной) компоненты (S).
Статистически значимые величины коэффициента автокорреляции первого порядка свидетельствуют о наличии во временном ряду трендовой компоненты, а повторяющиеся с определенным шагом лаговые значения коэффициентов автокорреляции – о наличии сезонности соответствующей частоты.
Моделирование структуры временных рядов проводится в несколько этапов.
Во-первых, методом скользящей средней определяются значения сезонной компоненты S.
Во-вторых, на основе регрессионной трендовой модели проводится выделение тренда T.
В-третьих, с помощью статистики Дарбина–Уотсона проверяется наличие автокорреляции в остатках Е. Если значения случайных остатков не содержат автокорреляции, то с одной стороны, выделенные сезонную и трендовую составляющие можно использовать для прогнозирования, а с другой стороны, случайные остатки можно использовать вместо исходного ряда при анализе взаимосвязей и моделировании совместно с другими временными рядами.
Рассмотрим эти методы подробнее.
Выравнивание исходных уровней ряда методом скользящей средней.
В зависимости от периода сезонности вычисляются скользящие средние за этот период. Если в процессе вычислений среднее значение приходится на момент между соседними периодами или моментами времени, то проводят соотнесение вычисленных значений с фактическими моментами времени, т.е. дополнительно вычисляют скользящие средние по двум соседним значениям или так называемые центрированные скользящие средние.
Для аддитивной модели из текущих уровней временного ряда вычитаем значения центрированных скользящих средних. Определяем средние за весь рассматриваемый период значения сезонной компоненты за каждый период. Для этого вычисляем среднее значение ряда, приходящееся на одноименный месяц (неделю, квартал и.т.п.) по всем рассматриваемым периодам. Модели с учетом сезонных колебаний предполагают, что за полный цикл сезонные возвращают временной ряд на прежний уровень. В аддитивной модели это выражается в том, что сумма значений сезонной компоненты за один рассматриваемый полный цикл должна равняться нулю. Если для вычисленных величин сезонной составляющей это требование не выполняется, необходимо определить корректирующий коэффициент:
где – значение сезонной компоненты в момент (период) времени t,
s – количество периодов сезонности в течение года.
Итоговая величина коэффициента сезонности в аддитивной модели определяется как разность между ее средней оценкой и корректирующим коэффициентом k.
В мультипликативной модели вычитание центрированной скользящей средней из уровней заменяется на деление. Таким образом, величины сезонной компоненты определяются как частное от деления уровней на центрированные скользящие средние. Аналогично варианту с аддитивной моделью, сезонную составляющую за каждый момент времени необходимо усреднить за весь рассматриваемый период.
В мультипликативной модели условие о взаимопогашаемости сезонных колебаний выражается в том, что сумма значений коэффициентов сезонности должна равняться количеству периодов в рассматриваемом цикле. Если это условие не выполняется, корректирующий коэффициент определяется по формуле:
где – значение сезонной компоненты в момент (период) времени t,
s – количество периодов сезонности в течение года.
Скорректированные значения сезонной компоненты определяются путем умножения корректирующего коэффициента на величину усредненной сезонной компоненты.
После того как определены величины коэффициентов сезонности, из наблюдаемых уровней временного ряда исключаем сезонную составляющую. Для аддитивной модели сезонная компонента вычитается из уровней:
Т + Е = Y – S.
Для мультипликативной модели уровни делятся на сезонную компоненту:
Т · Е = Y : S.
После исключения сезонной составляющей из уровней ряда необходимо выделить трендовую компоненту. Тип тренда можно определить визуально, построив поле корреляции для ряда с исключенной сезонной составляющей. Параметры тренда определяются для парной линейной или иной регрессии, где в качестве зависимой переменной выступает компонента Т + Е или Т · Е, а в качестве фактора – время t.
.
После определения параметров тренда и оценки качества построенной трендовой модели можно вычислить прогнозные значения тренда и исключить трендовую составляющую из скорректированных с учетом сезонности уровней. Как и в случае с коэффициентами сезонности, для аддитивной модели вычисляется разность:
а для мультипликативной модели – частное:
.
Выделенные сезонную и трендовую компоненты можно считать пригодными для прогноза только в том случае, если случайный компонент не содержит автокорреляции в остатках.
Проверить наличие или отсутствие автокорреляции в остатках можно графическим и аналитическим способом.
В первом случае необходимо построить график зависимости остатков Е от времени t.
Во втором случае можно использовать критерий Дарбина–Уотсона. Для этого вычисляется DW-статистика по формуле:
Кроме того можно использовать коэффициент автокорреляции остатков первого порядка:
где:
, .
Связь между критерием Дарбина–Уотсона и коэффициентом автокорреляции остатков первого порядка определяется следующим соотношением:
.
Следовательно, если в остатках существует высокая положительная автокорреляция, то и d = 0. Если в остатках присутствует высокая отрицательная автокорреляция, то и, следовательно, d = 4. Если автокорреляции в остатках не наблюдается, то и d = 2. Таким образом,
Для использования критерия Дарбина-Уотсона для оценки автокорреляции остатков используют механизм проверки статистических гипотез.
Выдвигаются гипотеза об отсутствии автокорреляции остатков и альтернативные гипотезы и заключающиеся, соответственно, в наличии положительной или отрицательной автокорреляции в остатках. По таблицам критических значений DW-статистики для заданного числа наблюдений n, числа независимых переменных модели k и уровня значимости определяются пороговые величины критерия Дарбина–Уотсона dL и dU. Эти значения используют для разбиения отрезка [0;4] на пять частей. Принятие или отклонение каждой из гипотез с вероятностью осуществляется по схеме:

Если расчетное значение критерия Дарбина–Уотсона попадает в зону неопределенности, то считают, что автокорреляция остатков существует, и гипотезу отклоняют.
Рассмотрим процесс и предположим, что текущие уровни этого временного ряда зависят от уровня в предыдущий момент времени . Такая зависимость носит название авторегрессии первого порядка:
где – белый шум, и – неизвестные параметры.
Добавление лаговых значений процесса в правую часть выражения увеличивает порядок авторегрессии:
В общем виде авторегрессионный процесс произвольного порядка p обозначается AR(p).
Как правило, свободный член опускается, и рассматривается поведение случайного процесса в зависимости от величины параметров при лаговых значениях. Если значение параметра превосходит единицу, то каждая последующая итерация (в каждый следующий момент/период времени) увеличивает значение . Для рядов такой природы существует специальный термин – процесс случайного блуждания. Для отображения свойств подобных процессов используют другой термин – нестационарный процесс.
Стационарность в узком смысле подразумевает независимость от времени совместного распределения k наблюдаемых величин. В широком смысле стационарность выражается в независимости от времени двух параметров: среднего значения и дисперсии выборки.
Проверка временного ряда на стационарность осуществляется путем оценивания параметра из выражения
где – оцениваемый параметр,
– первая разность .
Нестационарные временные ряды иногда называют процессами с единичным корнем. Если переписать авторегрессию с помощью лагового оператора L
и выделить характеристическое уравнение
,
то у стационарного процесса корни этого уравнения лежат вне единичного круга, т.е. , а у нестационарного процесса корни равны единице, т.е. .
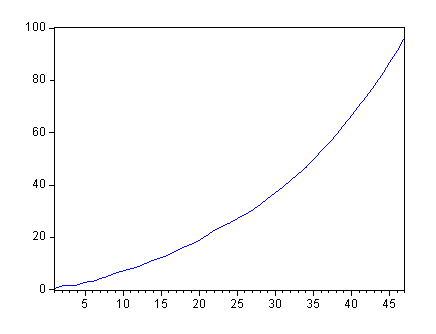
Рис. 2. График нестационарного процесса AR(1)
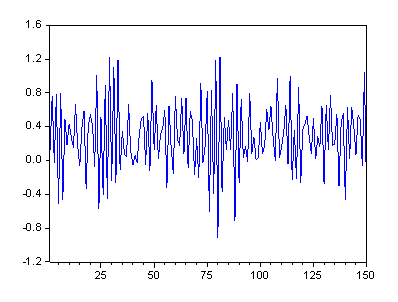
Рис. 3. График стационарного процесса AR(1)
Рассмотрим процесс, порожденный линейной комбинацией лаговых элементов белого шума:
.
Временные ряды такой природы называют процессом скользящего среднего первого порядка.
Параметр называют шоком, т.к. этот параметр определяет влияние на процесс лаговых значений белого шума.
Если в правой части выражения включены не одно, а несколько лаговых значений белого шума, то порядок процесса скользящего среднего определяется количеством q лаговых слагаемых:
.
Процесс скользящего среднего является стационарным в широком смысле, т.к. среднее и дисперсия такого ряда не зависит от времени.
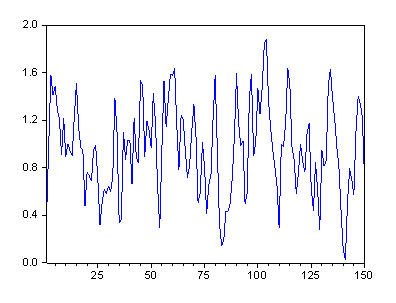
Рис. 4. График процесса скользящего среднего MA(2) .
Объединение процессов авторегрессии и скользящего среднего порождает ARMA (p, q) процесс. Порядок авторегрессии обозначается p, порядок процесса скользящего среднего – q. Особенность ARMA (p, q) модели в том, что случайный остаток авторегрессионной модели заменяется процессом скользящего среднего.
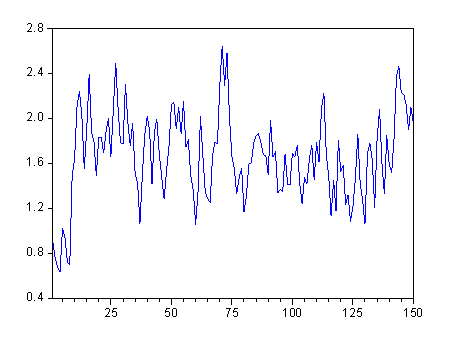
Рис. 5. График процесса авторегрессии и скользящего среднего ARMA(1, 1) .
Для определения порядка процессов авторегрессии и скользящего среднего используются автокорреляционная и частная автокорреляционная функции.
Автокорреляционная функция представляет собой коэффициент автокорреляции, рассчитанный для разных значений лага t:
Частная автокорреляционная функция также вычисляется в зависимости от величины лага t, но дополнительно необходимо построить авторегрессионную модель
,
и тогда коэффициентом частной автокорреляции считают величину коэффициента при максимальной величине лага t:
.
Исходя из свойств процессов авторегрессии и скользящего среднего для процесса MA(q) автокорреляционная функция ACF порядка большего чем q равна нулю, а для процесса AR(p) частная автокорреляционная функция PACF порядка большего чем p равна нулю.
В предыдущей теме рассматривались нестационарные авторегрессионные процессы в широком и узком смысле. Используя эти определения сформулируем свойства для идентификации стационарных и нестационарных временных рядов.
Свойства стационарных временных рядов позволяют сделать предположения о характере временных рядов на основании графиков уровней и автокорреляционной функции.
Стационарные ряды:
·в долгосрочном периоде уровни ряда колеблются около постоянного среднего значения,
·дисперсия временного ряда не зависит от времени,
·автокорреляционная функция убывающая, т.е. при увеличении длины лага значение ACF убывает.
Нестационарные ряды:
·в долгосрочном периоде уровни ряда группируются около разных средних значений,
·дисперсия ряда меняется от периода к периоду, т.е. зависит от времени,
·автокорреляционная функция почти постоянная, убывает очень медленно.
На основе этих свойств установить стационарность невозможно. Можно лишь выдвинуть предположения. Аналитически для установления стационарности или порядка интегрируемости временных рядов используют ряд тестов, которые именуют тестами единичного корня.
Перед тем, как проводить любой регрессионный анализ временных рядов, необходимо провести проверку на стационарность рядов данных, включенных в анализ, и в случае нестационарности определить порядок интеграции каждого ряда, либо сделать заключение о неинтегрированности процесса вообще.
Дадим определение стационарного процесса (временного ряда): случайный процесс в форме авторегрессии первого порядка:
. (1)
где – «белый шум», называется стационарным или интегрированным нулевого порядка I(0), когда ; и процесс называется нестационарным, если .
Наиболее простой способ проверки на стационарность временного ряда – применение интеграционной статистики Дарбина–Уотсона (IDW-статистика). Разработанная на основе статистики Дарбина и Уотсона для анализа автокорреляции остатков, IDW-статистика имеет следующий вид:
,
где – среднее арифметическое переменной . Если в уравнении (1) , тогда выражение в числителе: . Интуитивно ясно, что у нестационарного ряда это отношение будет близко к 0. Можно сказать, что процесс – нестационарный, если значение , и относительно точно утверждать о стационарности , если значение . Утверждение о стационарности процесса не требует подтверждения результатами других тестов, однако нестационарность влечет за собой задачу определения порядка интеграции либо заключения о неинтегрированности процесса вообще.
Метод для определения порядка интеграции был предложен Дики и Фуллером (1979). Основная идея метода заключается в проверке гипотезы о стационарности процесса и его последовательных разностей разного порядка.
Если проводить оценку параметра уравнения (1) обычным методом наименьших квадратов, и проверять гипотезу о равенстве с помощью t-статистики, мы можем получить ложную значимость, так как в рамках нулевой гипотезы t-теста Стьюдента, оцениваемое значение не стационарно. Поэтому необходимо использовать альтернативный тест, нулевая гипотеза которого предполагает стационарность процесса. Тест Дики–Фуллера (Dickey-Fuller test, DF-тест), или так называемый тест единичного корня, основан на оценке параметра , уравнения , эквивалентного уравнению регрессии (1). В этом случае, нулевая гипотеза состоит в равенстве , а противоположная ей: .
Отклонение нулевой гипотезы в пользу альтернативной, приводит к заключению, что , и процесс – стационарный, или интегрированный нулевого порядка ( ).
Проведенный таким образом DF-тест для уравнения (1), позволит определить: является ли процесс стационарным (интегрированным нулевого порядка), или нет.
Так как распределение статистики Дики–Фуллера не имеет аналитического представления, существуют отдельные сложности с определением точного критического значения для DF-статистики. Таблицы теста Дики–Фуллера на порядок интеграции, рассчитаны для привычных уровней значимости в 1 %, 5 %, 10 %. Представленные там значения – эмпирические, а не теоретические, поэтому в таблице критических значений указано верхнее и нижнее пороговые значения. Не следует забывать, что указанные в таблице значения DF-статистики отрицательные.
Для проверки процесса на порядок интеграции, рассчитывают значение t-статистики Стьюдента для параметра , и сравнивают его с верхним и нижним пороговыми значениями DF-статистики из таблицы. Если значение расчетной t-статистики меньше (более отрицательное) чем нижнее критическое значение для соответствующего числа наблюдений , нулевую гипотезу (о наличии единичного корня) следует отклонить, и принять альтернативную, о стационарности процесса . Если расчетное значение t-статистики превышает верхнее критическое значение, тогда нулевая гипотеза не может быть отклонена. В случае, когда расчетное критическое значение попадает в область между верхним и нижним критическими значениями, ничего определенного об отклонении или принятии нулевой гипотезы, сказать нельзя.
В случае, когда нулевая гипотеза о равенстве не отклоняется, можно только утверждать, что процесс нестационарен. Дополнительный вывод, который следует из этого утверждения: либо процесс интегрирован выше нулевого порядка, либо не интегрирован вообще.
Следующий этап в оценке порядка интегрированности временного ряда – проверка гипотезы об интегрированности процесса первого порядка, т. е. . В этом случае применяем DF-тест к первым разностям вместо . Уравнение (1) примет следующий вид:
. (2)
Снова выдвигаем две альтернативные гипотезы:
.
Если на основании DF-теста отклоняем гипотезу , и принимаем альтернативную гипотезу , тогда ряд – стационарный, а процесс , интегрированный первого порядка, т.е. . Иногда в таком случае говорят, что процесс имеет один единичный корень. Если нулевая гипотеза не может быть отклонена, тогда следует проверить на интегрированность второго порядка.
Теоретически можно продолжать процесс проверки на стационарность до тех пор, пока, с одной стороны, не определится порядок интеграции , или, с другой стороны – не установится неинтегрированность процесса . На практике редко встречаются временные ряды, интегрированные выше второго порядка. Неинтегрированность временного ряда означает, что невозможно добиться стационарности ряда, вычисляя последовательные разности разного порядка. Возможна также ситуация, когда процесс интегрирован, но применяемый тест неадекватно оценивает его порядок. В обоих случаях существует опасность «сверхразности», т.е. применения разностного оператора несколько раз. Очевидный сигнал «сверхразности» – очень высокое положительное значение DF-статистики наряду с высоким значением коэффициента детерминации для оцениваемой регрессии. В этом случае необходимо использовать другие методы оценки порядка интеграции временного ряда.
DF-тест также применим для оценки порядка интегрированности случайного процесса со смещением, который задается следующим уравнением:
, (3)
где – константа, смещение, поправка на параметр. Используемый для оценивания порядка интегрирования механизм аналогичен описанному выше, за исключением применяемой таблицы критических значений для t-критерия Стьюдента. На практике очень трудно различить ситуации, когда следует применять DF-тест, а когда DF-тест со сдвигом. Опыт показывает, что иногда результаты теста со сдвигом очень трудно интерпретировать.
В статистике стохастическая тенденция часто рассматривается наряду с детерминированной. Поэтому следующая модификация DF-теста – DF-тест со смещением и линейным детерминированным трендом. Уравнение этого теста имеет следующий вид:
. (4)
В уравнении (4) можно одновременно оценить отсутствие случайного тренда и наличие детерминированного тренда . В этом случае нулевая гипотеза включает два параметра. Адекватный этой ситуации тест – тест множителей Лагранжа, для которого, как и в предшествующих случаях, критические значения точно не определены. Простейший способ проверки переменной на порядок интеграции, обусловленной наличием детерминистического тренда, лежащего в основе процесса этой переменной, обычный DF-тест на отрицательность параметра . Для этого случая существует отдельная таблица критических значений DF-критерия.
Очевидный недостаток DF-теста в том, что в нем никак не учитывается возможная автокоррелированность остатков . Если в остатках наблюдается автокорреляция, тогда результаты обычного метода наименьших квадратов будут не достоверны. Для решения этой проблемы, Дики и Фуллер предложили включить в правую часть дополнительные объясняющие переменные: лаговые значения переменной из левой части, т.е.:
, (5)
Этот тест называется обобщенный тест Дики–Фуллера (Augmented Dickey-Fuller test, ADF-тест). Это наиболее эффективный, распространенный и наиболее часто встречающийся из простых тестов на интеграцию. Процедура тестирования аналогичная предыдущим, оценивается значение t-критерия Стьюдента для параметра . Критические значения для ADF-теста те же самые, что и для обычного DF-теста.
По аналогии с добавлением в уравнение (1) константы и линейного тренда, не нарушая логики рассуждений, эти же слагаемые можно включить в уравнение (5):
, (6)
. (7)
Добавленные в уравнения (3), (4) лаговые компоненты, никак не изменяют верхние и нижние пороговые значения; поэтому в качестве таблицы критических значений для ADF-статистики используют соответствующую таблицу для DF-статистики. Замечания, сделанные в адрес DF-теста по поводу «сверхразности», справедливы и для ADF-теста.
На практике, выбор длины лага и элементов авторегрессионой компоненты – очень сложная задача. Основная цель от включения дополнительных слагаемых – обеспечение свойств «белого шума» для случайной компоненты , поэтому необходимо проверить на независимость и одинаковое распределение. Применения обычного теста Дарбина–Уотсона недостаточно. Также важно не перегружать ADF-уравнение большим количеством дополнительных слагаемых. В этом случае удобно использовать обычный метод исключений: выбрать максимальный лаг k, затем удалять из рассмотрения незначимые слагаемые. Обычно удаление незначимых слагаемых не сказывается на отсутствии автокорреляции в остатках. Необходимо отметить, что даже если максимальная длина лага рана k, то количество дополнительных слагаемых может быть меньше чем k, т.к. некоторые из коэффициентов могут оказаться равными нулю.
Для оценки качества прогноза по построенной модели можно использовать два показателя, линейный и квадратический: среднюю ошибку аппроксимации и относительную среднюю квадратическую ошибку.
Средняя ошибка аппроксимации вычисляется как простая арифметическая средняя:
.
Относительная средняя квадратическая ошибка определяется из выражения:
При построении моделей по временным рядам предполагается, что автокорреляция остатков в модели отсутствует. Однако эмпирические исследования не подтверждают этого предположения и требования. Автокорреляция остатков проявляется в разных значениях дисперсии остатков на разных временных интервалах. Такое поведение остатков носит название гетероскедастичности.
Условная дисперсия остатков в зависимости от доступной информации на момент времени t может быть определена следующим образом:
Рассмотрим авторегрессию первого порядка при наличии условной гетероскедастичности в остатках, тогда ARCH(1) процесс, т.е. авторегрессионный с условной гетероскедастичностью, может быть представлен в виде:
где – белый шум,
, , и – неизвестные параметры.
Условная гетероскедастичность проявляется в том, что условная дисперсия ошибки равна
,
т.е. зависит от значения остатков в предшествующий момент времени и является переменной.
В общем виде ARCH(p) процесс предполагает, что построена авторегрессия первого порядка и выражение для остатка содержит p лаговых значений.
Процесс проверки AR(p) модели на условную гетероскедастичность заключается в следующем:
·построить AR(p) модель и оценить остатки регрессии .
·построить регрессию в зависимости от
·с помощью статистических критериев t, F или c2 проверить гипотезу H0: против H1: . Если нулевая гипотеза отклоняется, то авторегрессионный процесс следует считать процессом ARCH(p).
Добавление лаговых значений дисперсии и остатка более высокого порядка в выражение для дисперсии, т.е. использование ARMA(p, q) модели для записи остатка
приводит к построению обобщенной модели авторегрессии с условной гетероскедастичностью. GARCH(p, q).
1.
Gourieroux С., Jasiak J.
Financial econometrics. – Princeton.:
2. Берндт Э.Р. Практика эконометрики: классика и современность / Пер. с англ. под ред. проф. С.А. Айвазяна. – М.: Юнити-Дана, 2005. – 863 с.
3. Эконометрика: учебник / Под. ред. И.И. Елисеевой. – 2-е изд., перераб. и доп. – М.: Финансы и статистика, 2006. – 344 с.
4. Практикум по эконометрике: учебник / Под. ред. И.И. Елисеевой. – 2-е изд., перераб. и доп. – М.: Финансы и статистика, 2006. – 344 с.
1. Айвазян С.А., Мхитарян В.С. Прикладная статистика и основы эконометрики. – М.: Юнити, 1998. – 1022 с.
2. Доугерти К. Введение в эконометрику. – М.: ИНФРА – М, 2009. – 465 с.
3. Катышев П.К., Магнус Я.Р., Пересецкий А.А., Головань С.В. Сборник задач к начальному курсу эконометрики – М.: Дело, 2007. – 368 с.
4. Магнус Я.Р., Катышев П.К., Пересецкий А.А. Эконометрика. Начальный курс: учебник. – 8-е изд. – М.: Дело, 2007. – 504 с.
1. http://www.nsu.ru/ef/tsy/ecmr/study.htm
2. http://www.nsu.ru/ef/tsy/ecmr/index.htm
3. http://www.statsoft.ru/home/textbook/glossary/default.htm
4. http://www.tvp.ru/vnizd/mathem4.htm
5. http://subscribe.ru/archive/science.humanity.econometrika/200007/17050500.html
6. http://www.cemi.rssi.ru/rus/publicat/e-pubs/ep97001/1.htm
[1] Бокс Дж., Дженкинс Г. Анализ временных рядов. Прогноз и управление: Пер. с англ. – 1974.
[2] Практикум по эконометрике: учебник / Под. ред. И.И. Елисеевой. – 2-е изд., перераб. и доп. – М.: Финансы и статистика, 2006. – 344 с.
[3] Берндт Э.Р. Практика эконометрики: классика и современность / Пер. с англ. под ред. проф. С.А. Айвазяна. – М.: Юнити-Дана, 2005. – 863 с.