Примеры организации данных
фактографических и
документальных БД
П1. Физическая структура данных в dBase
Dbase-подобная база данных физически может состоять из специализированных файлов следующего назначения:
- основного файла базы данных;
- memo-файла для хранения длинных полей;
- индексного файла.
Структура основного файла базы данных (типа .DBF)
Файл базы данных состоит из записи заголовка и записей с данными. В записи заголовка, начинающейся с нулевой позиции, определяется структура базы данных.
Количество полей определяет число подзаписей полей. В базе данных для каждого поля существует одна подзапись поля.
Структура заголовка файла данных
|
Байты |
Описание |
|
00 |
Типы файлов с данными FoxBASE+/dBASEIII +, без memo - 0х03 FoxBASE+/dBASEIII +, с memo - 0х83 FoxPro/dBASEIV, без memo - 0х03 FoxPro с memo - 0хF5 dBASEIV с memo - 0x8B |
|
01-03 |
Последнее изменение (ГГММДД) |
|
04-07 |
Число записей в файле |
|
08-09 |
Положение первой записи с данными |
|
10-11 |
Длина одной записи с данными (включая признак удаления) |
|
12-27 |
Зарезервированы |
|
28 |
1 - есть составной индексный файл (типа .CDX), 0-нет |
|
29-31 |
Зарезервированы |
|
32-n |
Подзаписи полей (для каждого поля одна подзапись) |
|
N+1 |
Признак завершения записи заголовка (0х01) |
Структура подзаписи полей
|
Байты |
Описание |
|
00-10 |
Название поля (максимально - 10 символов) |
|
11 |
Тип данных: C - символьное; N - числовое; L - логическое; M - типа memo; D - дата; F - с плавающей точкой; P - шаблон. |
|
12-15 |
Расположение поля внутри записи |
|
16 |
Длина поля (в байтах) |
|
18-31 |
Зарезервированы |
Записи с данными следуют за заголовком и включают в себя фактическое содержимое полей. Длина записи (в байтах) определяется суммированием длин полей, указанных в заголовке.
Записи данных (значений полей) в файле начинаются с позиции, указываемой в записи заголовка в байтах 08-09. Записи начинаются с байта, содержащего признак удаления. Если в этот байт занесен пробел, то запись не удалялась; если же в первом байте – звездочка, то запись удалена. За признаком удаления следуют данные из полей, названия которых находятся в подзаписях полей.
Структура memo-файла (тип .FPT)
Файл типа memo содержит одну запись заголовка файла и произвольное число блоков данных.
В записи заголовка располагается указатель на следующий свободный блок и размер блока в байтах, который устанавливается командой SET BLOCKSIZE (или фиксированная длина 512 байт для файлов типа .DBT) при создании файла. Запись заголовка начинается с нулевой позиции файла и занимает 512 байтов.
За записью заголовка следуют блоки, в которых содержатся заголовок блока и текст memo. В файл базы данных включены номера блоков, которые используются для ссылки на блоки memo. Расположение блока в memo-файле определяется умножением номера блока на размер блока (находящийся в записи заголовка). Все memo-блоки начинаются с четных адресов границ блоков.
Структура заголовка memo-файла
|
Байты |
Описание |
|
00-03 |
Расположение следующего свободного блока |
|
04-05 |
Не используются |
|
06-07 |
Размер блока (число байтов в блоке) |
|
08-511 |
Не используются |
Заголовок блока memo и текст memo
|
|
|
|
00-03 |
Сигнатура блока (тип данных в блоке): 0 - шаблон (поле типа шаблон) / 1 - текст (поле типа memo) |
|
04-07 |
Длина memo (в байтах) |
|
08-n |
Текст memo (n=длина) |
Структура индексного файла (тип .IDX)
В индексных файлах располагается одна запись заголовка и одна или больше записей вершин. В записи заголовка находится информация о корневой вершине, текущем размере файла, длине ключа, особенностях индекса и сигнатура, а также представление ключа в коде ASCII, которое можно вывести на печать, и выражения FOR. Запись заголовка начинается с нулевой позиции файла.
Во всех других записях вершин содержится атрибут, количество существующих ключей и указатели на вершины, располагающиеся слева и справа (на том же уровне) от данной вершины. Помимо этого, в них находится группа символов, представляющая значение ключа, и либо указатель на вершину нижнего уровня, либо подлинный номер записи в базе данных. Размер каждой записи равен 512 байтам.
Запись заголовка индексного файла
|
Байты |
Описание |
|
00-03 |
Указатель на корневую вершину |
|
04-07 |
Указатель на свободную в списке вершину (-1, если таковая отсутствует) |
|
08-11 |
Указатель на конец файла (размер файла) |
|
12-13 |
Длина ключа |
|
14 |
Особенности индекса (любое из нижеследующих числовых значений либо их сумма): 1 - уникальный индекс; 8 - индекс имеет дополнительный оператор FOR. |
|
15 |
Сигнатура индекса |
|
16-235 |
Ключевое выражение (не компилируется; до 220 символов)[1] |
|
236-455 |
Выражение FOR (не компилируется; до 220 символов, оканчивающееся пустым символом) |
|
456-511 |
Не используются |
Запись вершины индекса
|
Байты |
Описание |
|
00-01 |
Атрибуты вершины (любое из нижеследующих числовых значений либо их сумма): 0 - вершина индекса; 1 - корневая вершина; 2 - лист. |
|
02-03 |
Количество существующих ключей (0, 1 или больше) |
|
04-07 |
Указатель на вершину, расположенную непосредственно слева от данной вершины (на том же уровне; -1, если отсутствует) |
|
08-11 |
Указатель на вершину, расположенную непосредственно справа от данной вершины (на том же уровне; -1, если отсутствует) |
|
12-511 |
До 500 символов, включающих в себя значение ключа для длины ключа с четырехбайтовым шестнадцатиричным числом (хранящемся в обычном формате слева направо). Если вершина является листом (атрибут = 02 или 03), тогда четыре байта содержат подлинный номер, номер в базе данных в шестнадцатиричном формате - иначе 4 байта содержат внутрииндексный указатель[2]. |
Структура компактного индексного файла (тип .IDX)
Структура записи заголовка компактного индексного файла
|
Байты |
Описание |
|
00-03 |
Указатель на корневую вершину |
|
04-07 |
Указатель на свободную в списке вершину (-1, если таковая отсутствует) |
|
08-11 |
Резервируются для внутреннего использования |
|
12-13 |
Длина ключа |
|
14 |
Особенности индекса (любое из нижеследующих значений либо их сумма): 1 - уникальный индекс; 8 - индекс имеет дополнительный оператор FOR; 32 - формат компактного индекса; 64 - заголовок составного индекса. |
|
15 |
Сигнатура индекса |
|
16-35 |
Зарезервированы для внутреннего использования |
|
36-501 |
Зарезервированы для внутреннего использования |
|
502-503 |
По возрастанию или убыванию: 0 - возрастание; 1 - убывание. |
|
504-505 |
Зарезервированы для внутреннего использования |
|
506-507 |
Длина пула выражения FOR |
|
508-509 |
Зарезервированы для внутреннего использования |
|
510-511 |
Длина пула выражения FOR |
|
510-1023 |
Пул выражения ключа (не компилируется) |
Структура записи внутренней вершины для компактного индекса
|
Байты |
Описание |
|
00-01 |
Атрибуты вершины (любое из нижеследующих числовых значений либо их сумма): 0 - индексная вершина; 1 - корневая вершина; 2 - вершина-лист. |
|
02-03 |
Число существующих ключей (0, 1 или больше) |
|
04-07 |
Указатель на вершину, расположенную непосредственно слева от данной вершины (на том же уровне; -1 - если отсутствует) |
|
08-11 |
Указатель на вершину, расположенную непосредственно справа от данной вершины (на том же уровне; -1 - если отсутствует) |
|
12-511 |
До 500 символов, включающих в себя значение ключа для длины ключа с четырехбайтовым шестнадцатиричным числом (хранящемся в обычном формате слева направо). Эта вершина всегда содержит ключ индекса, номер записи и внутрииндексный указатель[3]. Комбинация из значения ключа и четырехбайтового числа будет повторена столько раз, количество которых задается в байтах 02-03. |
Структура записи внешней вершины для компактного индекса
|
Байты |
Описание |
|
00-01 |
Атрибуты вершины (любое из нижеследующих числовых значений либо их сумма): 0 - индексная вершина; 1 - корневая вершина; 2 - вершина-лист. |
|
02-03 |
Число существующих ключей (0, 1 или больше) |
|
04-07 |
Указатель на вершину, расположенную непосредственно слева от данной вершины (на том же уровне; -1 - если отсутствует) |
|
08-11 |
Указатель на вершину, расположенную непосредственно справа от данной вершины (на том же уровне; -1 - если отсутствует) |
|
12-13 |
Свободное для распределения пространство в вершине |
|
14-17 |
Маска номера записи |
|
18 |
Маска запасного байтового счетчика |
|
19 |
Маска хвостового байтового счетчика |
|
20 |
Количество битов, используемых для номера записи |
|
21 |
Количество битов, используемых для запасного счетчика |
|
22 |
Количество битов, используемых для хвостового счетчика |
|
23 |
Количество байтов, содержащих номер записи, запасной счетчик и хвостовой счетчик |
|
24-511 |
Ключи индексов и информация |
П2. Физическая структура[4] данных в MS SQL Server
Файлы операционной системыв MS SQL Serverпредставляются как нумерованные устройства для хранения БД. Каждое устройство разбивается на виртуальные страницы по 8 Кбайт.
MSSQLServer используется следующая иерархия понятий:
База данных — некоторый объем файлового физического пространства для размещения данных, принадлежащих одной логической базе.
Файлы БД. Каждая база данных состоит не менее чем из двух файлов. Один из них отводится под журнал транзакций. Отдельный файл данных может принадлежать только одной базе данных.
Экстент. Пространство для хранения объектов выделяется блоками (экстентами) по 8 следующих друг за другом страниц размером 8К. Экстент является единицей выделения пространства. Поэтому при создании БД нужно указывать размер файла с точностью до 64Кбайт.
Страница. Файлы делятся на страницы размером по 8 Кбайт каждая. Логический номер страницы складывается из внутреннего номера базы данных, номера файла и номера страницы в файле. В рамках БД файлы нумеруются, начиная с 1, и так же нумеруются страницы в рамках файла.
Используется два типа экстентов: однородные и смешанные. Однородные экстенты всегда принадлежат только одному объекту. Смешанный экстент может использоваться несколькими объектами.
В SQLServer существуют несколько типов страниц.
Следующие типы страниц относятся к хранению и поиску информации:
- страниц данных;
- индексных страниц;
- текстовых страниц;
- страницы журнала транзакций;
Кроме этого используются также страницы размещения:
- карты распределения блоков (основная и вторичная);
- карты свободного пространства;
- индексные карты размещения.
На странице всегда (в отличие от экстента) хранится однородная информация. Все страницы имеют заголовок, в котором хранится общая информация, используемая ядром СУБД для работы со страницами:
- номер страницы в формате <номер файла, номер страницы>;
- идентификатор объекта, которому принадлежит страница;
- индекс и уровень внутри индексного дерева, которому принадлежит страница;
- количество строк на странице;
- общий объем свободного пространства на странице;
- указатель на свободное пространство после последней строки на странице;
- минимальная длина строки на странице;
- объем зарезервированного пространства.
После заголовка следует информация о статусе страницы в картах распределения блоков и карте свободного пространства.
Страницы размещения
SQLServer использует три типа страниц размещения: карты распределения экстентов, карты свободного пространства, индексные карты размещения.
Карта распределения экстентов состоит из стандартного заголовка и битового массива в 64 000 битов. Каждый бит характеризует один экстент. Поэтому одна страница карты распределения описывает пространство в 64 000 экстентов или 4 Гбайт данных.
При отведении пространства используются два типа карт распределения экстентов:
- глобальная карта распределения (Globalallocationmap, GAM) хранит информацию об использовании экстентов. Если бит установлен в 0, то экстент занят данными, если в 1 — то экстент свободен;
- вторичная глобальная карта распределения (Secondaryglobalallocationmap, SGAM) хранит информацию о типе экстентов. Если бит установлен в 1, то соответствующий экстент смешанный и минимум одна страница в нем свободна, в остальных случаях бит равен 0.
Карта свободного пространства (Pagefreespacepage, PFS) отражает степень заполнения страниц. Каждая PFS-страница хранит информацию о 8000 страницах - по одному байту на страницу. Каждый байт представляет собой битовую карту, которая сообщает о степени занятости страницы и о том, принадлежит ли она объекту.
Карта распределения размещается с первой страницы файла БД. Страницы повторяются через каждые 8000 страниц.
Первая страница PFS после стандартного заголовка страницы содержит заголовок файла (его описание), затем размещается сам блок PFS. Вторая страница — это GAM, третья — SGAM. Карты распределения экстентов повторяются через каждые 512 000 страниц.
Для организации связи между экстентами и расположенными на них объектами используются индексные карты размещения (IndexAllocationMap, IAM). Каждая таблица или индекс имеют одну или более страниц IAM. В каждом файле, в котором размещаются таблица или индекс, существует минимум одна карта размещения для этой таблицы или индекса. Страницы IAM размещаются произвольно внутри файла и отводятся по мере необходимости. IAM объединены друг с другом в цепочку двунаправленными ссылками. Указатель на первую карту размещения содержится в поле FirstlAM системной таблицы Sysindex.
Каждая IAM описывает некоторый диапазон экстентов и представляет собой битовую карту: если бит установлен в 1, то в данном экстенте есть страницы, принадлежащие данному объекту, если в 0 — то нет.
Все страницы размещения не связаны напрямую с некоторым объектом БД, они соответствуют некоторой системной информации, поэтому параметр «идентификатор объекта» для всех этих страниц одинаков и равен 99.
Страницы данных используются для хранения собственно данных. Структурно страницу данных можно подразделить на три зоны: заголовок, строки данных и таблицу размещения строк (слоты). Связь между страницами и объектами реализует специальная структура — карты размещения.
Строка данных должна полностью умещаться на странице, поэтому существуют ограничения на длину строки. Размер страницы 8 Кбайт, 96 байт занимает заголовок. Кроме того, в таблице размещения каждому слоту отводится по 4 байта для каждой строки, размещенной на странице.
Строки данных на странице не обязательно хранятся непрерывно. При удалении строки пустое пространство помечается как свободное и потом его может занять новая строка, перемещения строк не происходит. Адрес (смещение) на странице и длина строки фиксируется в слоте (Slot).
Если таблица не имеет кластеризованного индекса, то номер слота является идентификатором строки, пока не будет удалена соответствующая строка. Если же таблица имеет кластеризованный индекс, то слоты располагаются в порядке, задаваемом индексом.
Первые страницы данных таблиц БД расположены не подряд: сразу за первой страницей данных таблицы следует ее индексная карта размещения.
Для более эффективного управления дисковым пространством SQL Server не выделяет создаваемым таблицам сразу целый экстент. Для новой таблицы или индекса, как правило, выделяется место на смешанном экстенте. Когда объем таблицы или индекса увеличивается до восьми страниц, все последующие выделяемые экстенты будут однородными. Соответственно, если на смешанных экстентах места нет, а объем таблицы не достиг еще восьми страниц, то выделяемый новый экстент будет объявлен смешанным. Например, таблица занимает две страницы на смешанном экстенте, и в нее еще добавляется сразу шесть записей, то если свободных страниц на смешанных экстентах нет, будет выделен новый смешанный экстент, и на нем разместятся 6 записей. Потом, если добавляется еще одна запись, будет выделен полный новый однородный экстент, и на нем размещена эта новая запись.
Данные хранятся на страницах в виде строк. Каждая строка кроме собственно данных хранит дополнительную форматирующую информацию. Длина строки зависит от типов полей таблицы. Независимо от объявления, каждая строка имеет поле с количеством полей переменной длины (к ним относятся также поля фиксированной длины, допускающие неопределенные значения NULL, которые при этом резервируют пространство, указанное в определении поля).
Фиксированные поля вместе с описателями хранятся до полей переменной длины. Поля фиксированной длины всегда занимают свою полную длину, значение NULL задается специальным флагом.
В каждой строке хранится общая длина строки и текущие длины полей переменной длины. Данные считываются последовательно с начального адреса.
Вторая часть — это необязательная область, она существует только тогда, когда имеются в записи поля переменной длины, и включает:
- указатель на местоположение полей переменной длины;
- собственно значения полей переменной длины.
Текстовая страница может содержать несколько текстовых полей.
Строка данных содержит указатель на корневую структуру. Собственно данные хранятся в виде сбалансированного В-дерева.
Данные длиной менее 64 байт хранятся в корневой структуре.
Для данных до 32 Кбайт корневая структура может адресовать 4 блока данных (это не экстенты страниц) до 8 Кбайт каждый. Блоки наращиваются до 8 Кбайт (реально на одной текстовой странице может быть размещено до 8080 байт).
Если же длина текстового поля более 32 Кбайт, то строятся промежуточные узлы.
Индексы
Кластеризованный индекс представляет собой двоичное дерево, в котором на нулевом уровне (уровне листьев) содержатся страницы актуальных данных таблицы, а физическое расположение информации в данном индексе логически упорядочено.
В случае некластеризованных индексов страницы уровня листа содержат не актуальные данные таблицы (как в случае кластеризованного индекса), а указатель на строкуданных, включающий номер страницы данных и порядковый номер записи на станице. Некластеризованный индекс не требует физического переупорядочения строк данных таблицы.
Двоичные деревья являются динамически поддерживаемыми структурами, т.е при вставке, удалении или обновлении строк данных информация в индексах также должна быть изменена для отражения выполненных в таблице изменений. Для обработки страниц индексов требуются дополнительные операции ввода-вывода.
Но при разбивке[5] страницы кластеризованного индекса не требуется вносить изменения в информацию некластеризованных индексов, так как в SQL Server 7 эти дополнительные операции ввода-вывода полностью исключены за счет использования в некластеризованных индексах значений ключей кластеризованного индекса вместо номеров физических страниц в случае, когда таблица имеет оба типа индексов.
Индексы таблиц хранятся в виде страниц. Каждая страница размером 8192 байт включает заголовок, имеющий длину 96 байт. Еще один фрагмент страницы используется для размещения других структур данных, например информации о переполнении строк. Вся оставшаяся часть страницы (8060 байт) предназначена для размещения данных. Каждая строка включает элемент индекса (значение индексируемого поля таблицы) и идентификатор RowID (включающий идентификатор файла, номер страницы, номер строки), указывающий на соответствующую запись в таблице.
Организация и оптимизация доступа к данным
Вследствие объективно существующей разницы в скорости работы процессоров и оперативной памяти с одной стороны, и устройств внешней памяти с другой, буферизация страниц базы данных в оперативной памяти — единственно реальный способ достижения удовлетворительной эффективности СУБД. Кроме этого используется механизм распределенного хранения информации - расщепления данных между файлами и файловыми группам, физически размещаемыми на разных устройствах или RAID-массивах. Логически такое устройство представляется как единое целое, но на самом деле состоит из нескольких физических дисков. Данные на дисках размещаются блоками одной длины и таким образом, легко могут быть распределены по всем дискам.
Стратегия буферизации, применяемая в операционных средах, не соответствует целям и задачам СУБД, поэтому для оптимизации обработки данных одной из главных задач СУБД является создание эффективной системы управления процессом буферизации.
Память, управляемая СУБД, состоит из нескольких типов буферов:
- буфера страниц данных, с которыми работает СУБД;
- буфера страниц журнала транзакций, которые отражают процесс выполнения транзакции — последовательности операций над БД, переводящей БД из одного непротиворечивого состояния в другое непротиворечивое состояние;
- системные буферы, которые содержат общую информацию о БД, о пользователях, о физической структуре БД, о базе метаданных.
Если бы запись об изменении базы данных реально немедленно записывалась во внешнюю память, это привело бы к существенному замедлению работы системы. Поэтому записи в журнал тоже буферизуются: при нормальной работе очередная страница выталкивается во внешнюю память журнала только при полном наполнении записями.
Но поскольку имеются два вида буферов, содержащих взаимосвязанную информацию — буфер журнала и буфер страниц оперативной памяти, которые могут выталкиваться во внешнюю память, буферы выделяются не для каждого пользовательского процесса, а для всех процессов сервера. Это позволяет увеличить степень параллелизма при исполнении клиентских процессов.
П3. Документальная информационно-поисковая система
Организация данных и механизмы поиска в базах данных документальных информационных систем, построены на тех же принципах, что и фактографические системы. Однако в физической реализации есть и существенные отличия, которые обусловлены в первую очередь информационной природой элементов данных:
1. Запись базы данных – документ, который задается как набор в общем случае необязательных полей, для каждого из которых определены имя и тип. Допустимы большинство стандартных типов (так называемые «форматные» поля, задающие числовые, символьные и другие величины), а также текстовые. Текстовые поля имеют переменную длину и композиционную структуру, не имеющую прямых аналогов среди стандартных типов языков программирования: текстовое поле состоит из параграфов; параграф - из предложений; предложение - из слов. При этом идентифицируемым (адресуемым атомарным) элементом данных с точки зрения хранения будет поле, а с точки зрения поиска (атомарным семантически значимым) – слово. Вследствие этого поисковые структуры строятся в виде инвертированных файлов.
2. Семантическая природа текстовых полей, представляющих смысл в основном на естественном языке, определяет необходимость учитывать важнейшие свойства используемых терминов: синонимию, полисемию, омонимию, контекстную обусловленность смысла отдельного слова и возможность выразить один смысл многими способами. Вследствие этого поисковые индексы могут быть отличны от соответствующих словоформ поля.
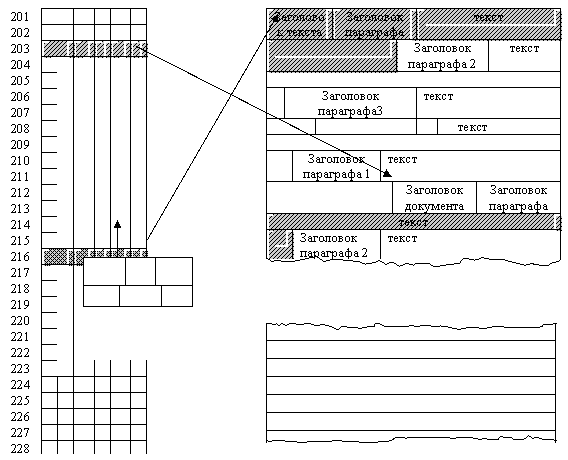
На рис. п.1 приведена принципиальная схема организации данных для представления и поиска информации диалоговой системы поиска документов STAIRS (StorageandInformationRetrievalSystem), разработанной фирмой IBM в 70-х годах. Данная структура характерна и для большинства современных АИПС.
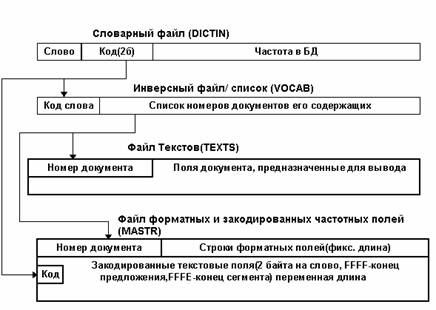
Рис. п1. Организация данных в диалоговой системы поиска документов STAIRS
Физическая структура БД рассматриваемой системы включает в себя четыре файла операционной системы:
- файл частотного словаря, устанавливающий соответствие между словом, встречающимся в БД, его кодом и частотой, используется при текстовом поиске;
- инверсный (инвертированный, обратный) список, содержащий для каждого слова БД список документов, его содержащих, используется при текстовом поиске;
- текстовый файл, содержащий собственно документы, используется при выдаче (просмотре) документов;
- прямой, последовательный файл, содержащий "собранные" в одну строку фиксированной длины форматные поля и список двухбайтовых кодов слов, находящихся в тексте данного документа. При необходимости, в соответствующих местах находятся разделители сегментов и/или предложений. Файл используется при форматном поиске и при наличии в запросах конструкций SENT, SEGM, CTX.
На рис. п.2 детально представлен словарь слов, в котором содержится перечень слов, встречающихся в документах. Ввиду значительных размеров словаря его организация должна предусматривать наличие специального индекса, представленного матрицей пар знаков. Каждой паре знаков поставлен в соответствие указатель на блок словаря, содержащий группу слов, начинающихся с этих знаков. Знаками могут быть буквы, цифры, а также специальные символы. Второй знак может быть пробелом. Группы слов в словаре имеют переменную длину. Первые два знака слов, содержащихся в словаре, отсутствуют, но они показаны на рисунке, чтобы облегчить понимание структуры файла. Некоторые слова в словаре могут иметь одинаковый смысл; такие слова связаны с помощью специального указателя «синоним» (на рисунке связи данного типа показаны штриховыми стрелками).
Каждому слову поставлен в соответствие указатель на списки экземпляров, являющихся перечнем документов, в которых встречается данное слово. Каждый список экземпляров содержит заголовок, из которого можно узнать число экземпляров слова во всем файле документов, а также число документов, в которых это слово встречается.
Система присваивает каждому документу уникальный номер. Этот номер является внутрисистемным и не связан с номерами, по которым пользователь может получить данный документ где-нибудь вне системы. В списке экземпляров, соответствующем какому-либо слову, содержатся внутрисистемные номера всех документов, в которых оно встречается. Поисковый критерий может включать требование поиска всех документов, содержащих одновременно два специфических слова. Например, можно осуществлять поиск документа, в котором содержится как слово ORANGUTANG, так и слово OSTRICH. В этом случае система находит множество документов, содержащих первое слово, а затем множество документов, содержащих второе слово, и путем их пересечения определяет множество документов, содержащих как первое, так и второе слово.
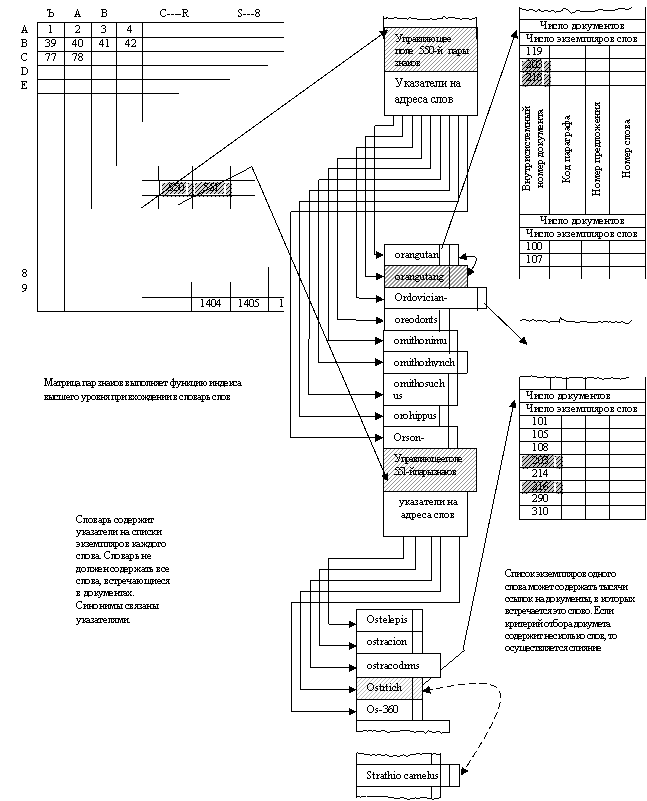
Рис. п.2. Организация поисковых индексов АИПС STAIRS