Использование концепции файлов и файловых групп для физического размещения хранимых данных упрощает управление базами данных и дисковой памятью, а также обеспечивает гибкость при размещении конкретных объектов на устройстве или устройствах. Причем в этом случае обеспечивается реальное распределение данных между всеми входящими в группу файлами (отдельными дисковыми устройствами или RAID-массивами): дисковые устройства действительно одновременно, ане поочередно будут заполняться поступающими данными, поскольку данные будут пропорционально «чередоваться» по файлам группы (рис. 10.1).
data1.mdf
 |
data2.mdf
Рис. 10.1. Чередование данных в файловой группе
Для повышения производительности системы в ряде случаев может использоваться индекс - отдельная физическая структура в базе данных, создаваемая на основе таблицы и предназначенная для ускорения выборки данных, поиск которых осуществляется по значению из проиндексированного столбца. Кроме того, индексы используются для обеспечения уникальности строк и столбцов таблиц, упорядочения данных таблицы в отдельном файле или группе файлов для повышения скорости доступа.
Однако наличие индекса замедляет такие операции с таблицей, как вставка, обновление и удаление данных: индексы являются динамически поддерживаемыми структурами, т.е. при вставке, удалении или обновлении данных информация в индексах также должна быть изменена для отражения выполненных в таблице изменений. Для такой обработки требуются дополнительные операции ввода-вывода.
Кластерный индекс представляет собой двоичное дерево, в котором на нулевом уровне (уровне листьев) содержатся страницы актуальных данных таблицы, а физическое расположение информации в данном индексе логически упорядочено. Такое размещение данных позволяет сократить время доступа к данным, но только при отборе по этому индексу. В других случаях это приводит к задержкам, т.к. доступ данным осуществляется только через индекс и доступ начинается всегда с корня.
Для отдельной таблицы можно построить только один кластерный индекс.
В случае некластерных индексов страницы уровня листа содержат не текущие данные таблицы (как в случае кластерного индекса), а указатель на строкуданных, включающий номер страницы данных и порядковый номер записи на станице.
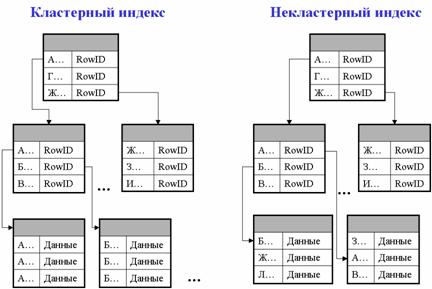
Рис. 10.2. Кластерный и некластерный индексы
Некластерный индекс позволяет быстро получить доступ к данным и не требует физического переупорядочения строк данных таблицы. Для каждой таблицы можно создавать до 249 некластерных индексов (рис. 10.2).