4.5. Модели распределения данных по физическим носителям
Важным фактором, влияющим на производительность подсистемы ввода-вывода, является распределение данных по дискам. Даже минимальная по объему высокопроизводительная система должна иметь по крайней мере четыре диска: один для операционной системы и области подкачки (swap), один для данных, один для журнала и один для индексов.
Размещение всех данных БД на одном и том же диске почти всегда приводит к неудовлетворительной производительности. В частности, может оказаться, что процесс формирования журнала, который должен записываться синхронно, в действительности будет выполняться в режиме произвольного, а не последовательного доступа к диску. Уже только эта операция будет существенно задерживать каждую транзакцию обновления базы данных.
Кроме того, выполнение запросов, выбирающих записи из таблицы данных путем последовательного сканирования индекса, будет сильно увеличивать время ожидания ввода-вывода. Обычно сканирование индекса выполняется последовательно, но в данном случае головка диска должна перемещаться для поиска каждой записи данных между выборками индексов. Наконец, следует отметить, что объединение разных функций на одних и тех же физических ресурсах приводит к резкому увеличению времени подвода головок на диске.
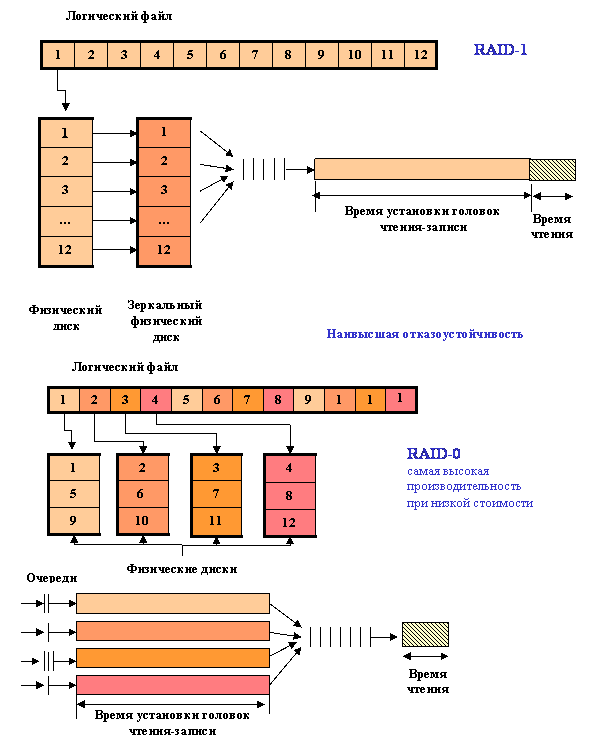
Примером, иллюстрирующим подход с точки зрения практических компромиссов выбора решения, являются RAID-массивы. На рис. 4.18 приведены два варианта: RAID-0, обеспечивающий максимальную производительность при «стандартной» надежности, и RAID-1, обеспечивающий «двойную» надежность при «стандартной» производительности.
|
|||||||
 |
|||||||
|
|||||||
Системы управления базами данных применяют по крайней мере два механизма для распределения данных по дисковым накопителям. Для эффективного распределения доступа к данным многие СУБД имеют возможность осуществлять сцепление нескольких дисковых накопителей или файлов. Если по запросам производится произвольный доступ к данным, например, если пользователи независимо запрашивают разные записи, то возможности сцепления дисков в СУБД полностью обеспечивают распределение нагрузки по доступу к множеству дисков (при достаточно равномерном заполнении пространства базы). Если обращения по своей природе последовательны, в частности если один или несколько пользователей должны просматривать каждую строку таблицы, то больше подходит механизм расщепления дисков. Главное отличие между сцеплением и расщеплением заключается в размещении смежных данных. Когда диски сцепляются друг с другом, последовательное сканирование представляет собой тяжелую нагрузку для каждого из дисков, но эта нагрузка носит последовательный характер (только один диск участвует в обслуживании запроса). Расщепление дисков осуществляет деление данных на меньшие порции, размещаемые на разные диски, позволяя тем самым всем дискам участвовать в обслуживании даже сравнительно небольшого запроса. В результате использование расщепления существенно уменьшает загрузку дисков при выполнении последовательного доступа. Основными кандидатами для расщепления являются обычно архивные и журнальные файлы, поскольку к ним всегда осуществляется последовательный доступ, что может ограничить общую производительность системы.
Контрольные вопросы
1. Перечислите типы физических записей. Приведите примеры, показывающие соотношение физических и логических записей.
 |
2. Перечислите факторы, влияющие на выбор метода размещения данных (организацию файла).
3. Перечислите методы организации файлов, позволяющих оптимизировать доступ к записям.
4. Приведите пример организации данных в виде индексно-последовательного файла.
5. Какие типы указателей можно использовать для реализации иерархической структуры.
6. Какие типы указателей можно использовать для реализации сетевой структуры с последовательным размещением.
7. Придумайте схему реализации сетевой структуры для случая часто изменяемых данных.
8. Какие методы организации данных, применяемые для реализации иерархических структур, неэффективны для реализации сетевых?
9. Приведите примерную структурную схему «страничной» организации хранения данных.
10. Приведите примерную схему размещения данных с использованием механизма расщепления.
Назад к разделу "4.4.2. Страничная организация данных"
Вперед к разделу "Глава 5. Модели и этапы проектирования баз данных"