Программисту или пользователю необходимо иметь возможность обращаться к отдельным, нужным ему записям (описаниям объектов) или отдельным элементам данных. В зависимости от уровня программного обеспечения прикладной программист может использовать следующие способы:
- задать машинный адрес данных и в соответствии с физическим форматом записи прочитать значение. Это случай, когда программист должен быть «навигатором»;
- сообщить системе имя записи или элемента данных, которые он хочет получить, и, возможно, организацию набора данных. В этом случае система сама произведет выборку (по предыдущей схеме), но для этого она должна будет использовать вспомогательную информацию о структуре данных и организации набора. Такая информация по существу будет избыточной по отношению к объекту, однако общение с базой данных не будет требовать от пользователя знаний программиста и позволит переложить заботы о размещении данных на систему.
В качестве ключа, обеспечивающего доступ к записи, можно использовать идентификатор – отдельный элемент данных. Ключ, который идентифицирует запись единственным образом, называется первичным (главным).
В том случае, когда ключ идентифицирует некоторую группу записей, имеющих определенное общее свойство, ключ называется вторичным (альтернативным). Набор данных может иметь несколько вторичных ключей, необходимость введения которых определяется практической необходимостью – оптимизацией процессов нахождения записей по соответствующему ключу.
Иногда в качестве идентификатора используют составной сцепленный ключ – несколько элементов данных, которые в совокупности, например, обеспечат уникальность идентификации каждой записи набора данных.
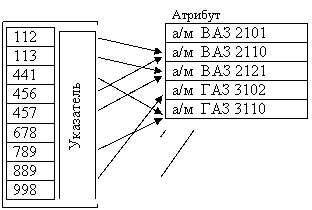
При этом ключ может храниться в составе записи или отдельно. Например, ключ для записей, имеющих неуникальные значения атрибутов, для устранения избыточности может храниться отдельно. На рис. 3.4 приведены два таких способа хранения ключей и атрибутов для набора простейшей структуры.
|
 |
|||||||||||||||||||||
Рис. 3.4 Способы хранения ключа и атрибута
Введенное понятие ключа является логическим и его не следует путать с физической реализацией ключа – индексом, обеспечивающим доступ к записям, соответствующим отдельным значениям ключа.
Один из способов использования вторичного ключа в качестве входа - организация инвертированного списка, каждый вход которого содержит значение ключа вместе со списком идентификаторов соответствующих записей. Данные в индексе располагаются в возрастающем или убывающем порядке, поэтому алгоритм нахождения нужного значения довольно прост и эффективен, а после нахождения значения запись локализуется по указателю физического расположения. Недостатком индекса является то, что он занимает дополнительное пространство и его надо обновлять каждый раз, когда удаляется, обновляется или добавляется запись. На рис. 3.5 приведен инвертированный список для предыдущего примера.
|
а/м ВАЗ 2101 |
678 |
|
а/м ВАЗ 2110 |
112, 456, 889 |
|
а/м ВАЗ 2121 |
113, 457 |
|
а/м ГАЗ 3102 |
998 |
|
а/м ГАЗ 3110 |
441, 789 |
Рис. 3.5. Инвертированный список для ключа «Марка автомобиля»
В общем случае инвертированный список может быть построен для любого ключа, в том числе составного.
В контексте задач поиска можно сказать, что существуют два основных способа организации данных. Первый соответствует примеру, приведенному на рис. 3.3, и представляет прямую организацию массива. Второй способ является инверсией первого, он соответствует рис. 3.4. Прямая организация массива удобна для поиска по условию «Каковы свойства указанного объекта?», а инвертированная – для поиска по условию «Какие объекты обладают указанным свойством?».
В [14] приводится следующая типология простых (атомарных) запросов:
1. А(Е) = ?Каково значение атрибута А для объекта Е?
2. А(?) = VКакие объекты имеют значение атрибута равное V?
3. ?(Е) = VКакие атрибуты объекта Е имеют значение равное V?
4. ?(Е) = ? Какие значения атрибутов имеет объект Е?
5. А(?) = ?Какие значения имеет атрибут А в наборе?
6. ?(?) = VКакие атрибуты объектов набора имеют значение равное V?
Здесь в запросах типов 2, 3, 6 вместо оператора равенства может быть использован другой оператор сравнения (больше, меньше, не равно или другие).
Запросы типа 1 выполняются поиском по «прямому» массиву: доступ к записи производится по первичному ключу. Запросы типа 2 выполняются поиском по инвертированному списку: доступ к записи(ям) производится по указателю, выбираемому из списка по значению вторичного ключа. Ответом в этих случаях будет значение атрибута или идентификатора. Запросы типа 3 имеют ответом имя атрибута.
Запросы типа 2, 5, 6 относятся к нескольким атрибутам, и в этом случае могут быть построены несколько индексов, облегчающих поиск по этим ключам.
Составные условия поиска могут использовать несколько простых условий, обычно связанных логическими (булевыми) операторами.
Следует отметить, что в контексте обработки запросов 2-го типа «Какие объекты имеют заданное значение атрибута?» можно выделить три следующих типа архитектур доступа:
1. Системы с вторичными индексами. В этих системах последовательность расположения записей соответствует последовательности значений первичного ключа. Как правило, используется один первичный индекс и несколько вторичных.
2. Системы частично инвертированных файлов. В этих системах записи могут располагаться в произвольной последовательности. В отличие от систем первого типа первичный индекс отсутствует. Вторичные индексы применяются для прямой адресации записей, что существенно облегчает включение в файл новых записей, так как допускается их размещение в любом свободном участке файла.
3. Системы полностью инвертированных файлов. В этих системах предусмотрено наличие файлов, содержащих значения отдельных элементов данных, входящих в состав записей – допускается раздельное хранение элементов данных записи. Значения элементов данных, составляющих конкретную запись или кортеж, в общем случае могут размещаться в памяти произвольно. Для ускорения процесса поиска в системе используют два набора индексов: индекс экземпляров (значений ключей)и индекс данных (инвертированный список). С помощью индекса экземпляров можно найти в файле элементы данных, имеющих заданное значение. С помощью индекса данных можно найти записи, связанные с заданными значениями элементов. Такая организация характерна для организации данных документальных информационных систем.
Назад к разделу "3.2. Идентификация объектов и записей"
Вперед к разделу "3.4. Представление предметной области и модели данных"