Введение. 5
Тема 1. Синтаксис языка Java. Объектная модель в Java. 6
Тема 2. Сравнение C# и Java. 53
Тема 3. Создание сетевых приложений. 70
Тема 4. Многопоточность в JAVA.. 100
Тема 5. Графический интерфейс пользователя в Java. 152
Тема 6. Работа
с базами данных в Java. 186
Тема 7. Платформы
CDC и CLDC.. 195
Контрольные вопросы.. 207
Вариант 1. 207
Вариант 2. 211
Литература. 213
Письмо возымело на
удивление большой успех как у ведущих инженеров, таки у высшего руководства
компании, а именно у Билла Джоя, основателя Sun Microsystems, и Джеймса
Гослинга, непосредственного начальника Нотона.
В день планируемого
увольнения Патрик Нотон получает зеленый свет на реализацию всех своих идей и
собственную группу ведущих разработчиков под кодовым названием Green, чтобы они
делали что угодно, но решили накопившиеся проблемы.
Команда приступила к
разработке нового объектно-ориентированного языка программирования, который
должен был стать ведущим на рынке промышленной и бытовой электроники. Вскоре
Нотон предложил использовать новые наработанные технологии для интернет -
приложений, в связи, с чем были написаны компилятор Java и браузер Hotjava. 23
мая 1995 года компания Sun официально представила Java и Hotjava на выставке
SunWorld'95. Именно тогда язык программирования
сделал первый шаг к современным высокотехнологичным мобильным
устройствам.
Платформа Java 2
Micro Edition (J2ME) , была разработана уже ближе к нашим дням для
устройств с ограниченными ресурсами памяти и процессора, таких как сотовые
телефоны, пейджеры, смарт-карты, органайзеры и миникомпьютеры. J2ME позволяет
запускать Java-приложения на ресурсоогранниченных вычислительных устройствах.
Для данных целей J2ME адаптирует существующую Java-технологию.
Отличие синтаксиса языка Java от C++.
Программирование в классах Java. Объектная
модель и типовые библиотеки Java.
Программы на Java транслируются в байт-код, выполняемый виртуальной java-машиной (JVM) —
программой, обрабатывающей байтовый код и передающей инструкции оборудованию
как интерпретатор, но с тем отличием, что байтовый
код, в отличие от текста, обрабатывается значительно быстрее.
Достоинство подобного
способа выполнения программ — в полной независимости байт-кода от ОС и оборудования, что позволяет выполнять
Java-приложения на любом устройстве, которое поддерживает виртуальную машину.
Другой важной особенностью технологии Java является гибкая система безопасности
благодаря тому, что исполнение программы полностью контролируется виртуальной
машиной. Любые операции, которые превышают установленные полномочия программы
(например, попытка несанкционированного доступа к данным или соединения с
другим компьютером) вызывают немедленное прерывание. Это позволяет
пользователям загружать программы, написанные на Java, на их компьютеры (или
другие устройства, например, мобильные телефоны) из неизвестных источников, при
этом не опасаясь заражения вирусами, пропажи ценной информации, и т. п.
Часто к недостаткам
концепции виртуальной машины относят то, что исполнение байт-кода виртуальной
машиной может снижать производительность программ и алгоритмов, реализованных
на языке Java. Данное утверждение было справедливо для первых версий
виртуальной машины Java, однако в последнее время оно практически потеряло
актуальность. Этому способствовал ряд усовершенствований: применение технологии
JIT (Just-In-Time
compilation), позволяющей переводить байт-код в машинный код во время
исполнения программы с возможностью сохранения версий класса в машинном коде,
широкое использование native-кода в стандартных
библиотеках, а также аппаратные средства, обеспечивающие ускоренную обработку
байт-кода (например, технология Jazelle, поддерживаемая некоторыми процессорами фирмы ARM).
Идеи, заложенные в концепцию
и различные реализации JVM, вдохновили множество энтузиастов на расширение
перечня языков, которые могли бы быть использованы для создания программ,
исполняемых в среде JVM. Эта идея перекликается с концепцией CLI, заложенной в основу
платформы .NET компании Microsoft.
Программа, выводящая «Hello, World!»:
public class HelloWorld { public static void main(String[] args) { System.out.println("Hello, World!"); }
}
Пример использования
шаблонов:
import java.util.*;
public class Sample { public static void main(String[] args) { // Создание объекта по шаблону.
List<String> strings = new LinkedList<String>();
strings.add("Hello"); strings.add("world"); strings.add("!"); for (String s : strings) { System.out.print(s);
System.out.print(" ");
В языке Java имеются только
динамически создаваемые объекты. Причем переменные объектного типа и объекты в Java — совершенно
разные сущности. Переменные объектного типа являются ссылками, то есть неявными указателями на динамически создаваемые
объекты. Это подчёркивается синтаксисом описания переменных. Так, в
Java нельзя писать:
double a[10][20];
Foo b(30);
а нужно:
double[][] a = new double[10][20];
Foo b = new Foo(30);
При присваиваниях, передаче
в подпрограммы и сравнениях объектные переменные
ведут себя как указатели, то есть присваиваются, копируются и сравниваются адреса объектов. А при
доступе с помощью объектной переменной к полям данных или методам объекта не
требуется никаких специальных операций разыменовывания — этот
доступ осуществляется так, как если бы объектная переменная была самим
объектом.
Объектными являются
переменные любого типа, кроме простых числовых типов. Явных указателей в Java
нет. В отличие от указателей C, C++ и других языков программирования, ссылки в
Java в высокой степени безопасны благодаря жёстким ограничениям на их
использование, в частности:
· Нельзя преобразовывать объект типа int
или любого другого примитивного типа в указатель или ссылку и наоборот.
· Над ссылками запрещено выполнять операции ++, −−,
+, − или любые другие арифметические операции.
· Преобразование типов между ссылками жёстко
регламентировано. За исключением ссылок на массивы, разрешено преобразовывать
ссылки только между наследуемым типом и его наследником, причём преобразование
наследуемого типа в наследующий должно быть явно задано и во время выполнения
производится проверка его осмысленности. Преобразования ссылок на массивы
разрешены лишь тогда, когда разрешены преобразования их базовых типов, а также
нет конфликтов размерности.
· В Java нет операций взятия адреса (&) или взятия
объекта по адресу (*). Звёздочка в Java означает умножение, и только. Амперсанд (&)
означает всего лишь «побитовое и» (двойной амперсанд — «логическое и»).
Благодаря таким специально
введенным ограничениям в Java невозможно прямое манипулирование памятью на
уровне физических адресов (хотя ссылки, не указывающие ни на что, есть:
значение такой ссылки обозначается null).
Дублирование
ссылок и клонирование
Из-за того, что объектные
переменные являются ссылочными, при присваивании не происходит копирования
объекта. Так, если написать:
Foo foo, bar;
…
bar = foo;
то произойдет копирование
адреса из переменной foo в переменную bar.
То есть foo и bar
будут указывать на одну и ту же область памяти, то есть на один и тот же
объект; попытка изменить поля объекта, на который ссылается переменная foo,
будет менять объект, с которым связана переменная bar,
и наоборот. Если же необходимо получить именно ещё одну копию исходного
объекта, пользуются или методом (функцией-членом,
в терминологии C++) clone(), создающим
копию объекта, или же копирующим конструктором.
Метод clone()
требует, чтобы класс реализовывал интерфейс
Cloneable (об интерфейсах
см. ниже). Если класс реализует интерфейс Cloneable,
по умолчанию clone() копирует
все поля (мелкая копия). Если требуется не копировать, а клонировать поля
(а также их поля и так далее), надо переопределять метод clone().
Определение и использование метода clone()
часто является нетривиальной задачей.
Java не является процедурным
языком: любая функция может существовать только внутри класса. Это подчёркивает
терминология языка Java, где нет понятий «функция» или «функция-член» (англ. member function),
а только метод. В методы превратились и стандартные функции. Например, в
Java нет функции sin(), а есть метод
Math.sin() класса Math
(содержащего, кроме sin(), методы cos(),
exp(), sqrt(),
abs() и многие другие).
Статические методы и поля.
Для того чтобы не надо было
создавать объект класса Math (и других аналогичных классов) каждый раз, когда
надо вызвать sin() (и другие
подобные функции), введено понятие статических методов (англ. static method;
иногда в русском языке они называются статичными). Статический метод
(отмечаемый ключевым словом static
в описании) можно вызвать, не создавая объекта его класса. Поэтому можно
писать:
double x = Math.sin(1);
вместо:
Math m = new Math();
double x = m.sin(1);
Ограничение, накладываемое
на статические методы, заключается в том, что в объекте this
они могут обращаться только к статическим полям и методам.
Статические поля имеют тот
же смысл, что и в C++: каждое существует только в единственном экземпляре.
Развитие абстракции.
Все языки программирования обеспечивают абстракцию.
Она может быть обсуждена как запутанная проблема, решаемая вами напрямую в
зависимости от рода и качества абстракции. Под “родом” я понимаю “Что вы
абстрагируете?” Сборный язык - это небольшая абстракция лежащей в основе
машины. Многие созвучные “императивные” языки, которые сопровождаются (такие
как Фортран, Бейсик и C) были абстракцией сборного языка. Эти языки являются
большим улучшением собирающих языков, но их первичная абстракция остается
необходима вам, чтобы думать в терминах структуры компьютера, а не в структуре
проблемы, которую вы решаете. Программист должен установить ассоциацию между
машинной моделью (в “области решения”, которая является местом, где вы
моделируете проблему, как и компьютер) и моделью проблемы, которая
действительно должна быть решена (в “пространстве проблемы”, где проблема
существует). Усилие, необходимое для выполнения этой связи и факты, присущие
языку программирования, производят программу, которая сложна для написания и
дорога для сопровождения, а с другой стороны, создается эффект целой индустрии
“методов программирования”.
Альтернативой к моделированию машины является
моделирование проблемы, которую вы пробуете решить. Ранние языки
программирования, такие как LISP и APL выбирают определенный взгляд на мир
(“Все проблемы - это, в конечном счете, список” или “Все проблемы - это
алгоритмы” соответственно). Пролог преобразует все проблемы в цепочку решений.
Были созданы Языки для программирования ограниченной базы и для
программирования манипуляций исключительно с графическими символами. (Позже
стали тоже ограниченными.) Каждый из этих подходов - это хорошее решение для
определенного класса проблем, которые они призваны решать, но когда вы выходите
за пределы этой области, они становятся неудобными.
Объектно-ориентированным подход продвигается на шаг
дальше, обеспечивая инструмент для программиста, представляющий элементы в
пространстве проблемы. Это представление достаточно общее, чтобы программист не
был скован определенным типом проблем. Мы ссылаемся на элементы в пространстве
проблемы и на их представление в пространстве решения, как на “объект”.
(Конечно, вам также необходимы другие объекты, которые не имеют аналогов в
пространстве проблемы.) Идея в том, что программа позволяет адаптировать себя к
языку проблемы путем добавления новых типов объектов, так что вы, читая код,
описывающий решение, читаете слова, которые описывают проблему. Это более
гибкая и мощная абстракция языка, чем те, что были ранее. Поэтому, ООП
позволяет вам описать проблему в терминах проблемы, а не в терминах компьютера,
где работает решение. Хотя здесь остается связь с компьютером. Каждый объект
полностью выглядит как маленький компьютер, он имеет состояние и он может
работать так, как вы скажете. Однако это не выглядит как плохая аналогия с
объектом в реальном мире — они все имеют характеристики и характер поведения.
Некоторые разработчики языков решают, что
объектно-ориентированное программирование само по себе не достаточно легко для
решения всех проблем программирования и отстаивают комбинацию различных
подходов в мультипарадигмовых языках программирования.
Алан Кэй суммирует пять основных характеристик
Смалтолка, первого удачного объектно-ориентированного языка, и одного из
языков, основанного на Java. Эти характеристики представлены в чистых подходах
к объектно-ориентированному программированию:
1. Все есть объект. Думать об объектах, как об особенных переменных; они хранят данные, но
вы можете “сделать запрос” к такому объекту, попросив его самого выполнить
операцию. Теоретически вы можете взять любой умозрительный компонент в проблеме,
которую вы пробуете решить (собак, дома, услугу и т.п.) и представить его как
объект в вашей программе.
2. Программа - это связка объектов, говорящих друг другу
что делать, посылая сообщения. Чтобы
сделать запрос к объекту, вы “посылаете сообщение” этому объекту. Правильнее вы
можете думать о сообщении, как о запросе на вызов функции, которая принадлежит
определенному объекту.
3. Каждый объект имеет свою собственную память, отличную
от других объектов. Говоря другими
словами, вы создаете объект нового вида, создавая пакет, содержащий
существующие объекты. Поэтому, вы можете построить сложные связи, пряча их
позади простых объектов.
4. Каждый объект имеет тип. Другими словами, каждый объект является экземпляром
класса, где “класс” - это синоним “типа”. Большинство важных различий
характеристик класса в том, “Какие сообщение можете вы посылать ему?”
5. Все объекты определенного типа могут принимать
одинаковые сообщения. Это
действительно важное утверждение, как вы увидите позднее. Так как объект типа
“круг” также является объектом типа “форма”, круг гарантированно примет
сообщения формы. Это означает, что вы можете писать код, который говорит форме
и автоматически управляет всем, что соответствует описанию формы. Это представляется
одной из большинства полезных концепций ООП.
Объект имеет интерфейс.
Аристотель, вероятно, был первым, кто начал
старательно изучать концепцию типа; он говорил: “класс рыбы и класс
птицы”. Идея, что все объекты, хотя являются уникальными, также являются частью
класса объектов, которые имеют общие характеристики и характер поведения, что
было использовано в первом объектно-ориентированном языке Симула-67 с этим
основополагающим словом класс, которое ввело новый тип в программу.
Симула, как показывает его название, был создан для разработки
симуляторов, таких как классическая “проблема банковского кассира”. В ней вы
имеете группу кассиров, клиентов, счетов, переводов и денег — множество
“объектов”. Объекты, которые идентичны, за исключением своих состояний во время
исполнения программы, группируются вместе в “классы объектов”. Так и пришло
ключевое слово класс. Создание абстрактных типов данных (классов) - это
основополагающая концепция в объектно-ориентированном программировании.
Абстрактные типы данных работают почти так же, как и встроенные типы: вы можете
создавать переменные этого типа (называемые объектами или экземплярами,
если говорить объектно-ориентированным языком) и манипулировать этими
переменными (это называется посылка сообщений или запрос; вы
посылаете сообщение и объект смотрит что нужно с ним делать). Члены (элементы)
каждого класса распределяются с некоторой унифицированностью: каждый счет имеет
баланс, каждый кассир может принимать депозит и т.п. В то же время, каждый член
имеет свое собственное состояние, каждый счет имеет различный баланс, каждый
кассир имеет имя. Поэтому, кассиры, клиенты, счета, переводы и т.п. могут быть
представлены как уникальная сущность в компьютерной программе. Эта сущность и
есть объект, а каждый объект принадлежит определенному классу, который
определяет характеристики и черты поведения.
Так, несмотря на то, что мы реально делаем в
объектно-ориентированном программировании - это создание новых типов,
фактически все объектно-ориентированные языки используют ключевое слово
“класс”. Когда вы видите слово “тип”, то думайте “класс” и наоборот.
Так как класс описывает набор объектов, которые имеют
идентичные характеристики (элементы данных) и черты поведения
(функциональность), класс реально является типом данных, потому что, например,
число с плавающей точкой также имеет набор характеристик и черт поведения.
Отличия в том, что программист определяет класс исходя из проблемы, чтобы
представить блок для хранения в машине. Вы расширяете язык программирования,
добавляя спецификации новых типов данных, которые вам необходимы. Эта система
программирования приветствует новые классы и заботится за ними всеми, выполняя
проверку типа, как и для встроенных типов.
Объектно-ориентированный подход не ограничивается
построением симуляторов. Независимо от того, согласны вы или нет, что любая
разрабатываемая вами программа - это эмуляция системы, использование ООП
техники может легко снизить большую часть проблем для упрощения решения.
Как только класс создан, вы можете создать столько
объектов этого класса, сколько захотите, а затем манипулировать этими объектами
так, как если бы они являлись элементами, которые существуют в проблеме,
которую вы пробуете решить. Несомненно, одно из предназначений
объектно-ориентированного программирования - это создание связей один-к-одному
между элементами в пространстве проблемы и объектами в пространстве решения.
Интерфейс определяет какой запрос вы можете
выполнить для определенного объекта. Однако должен существовать определенный
код, для удовлетворения этого запроса. Здесь, наряду со спрятанными данными,
содержится реализация. С точки зрения процедурного программирования это
не сложно. Тип имеет функциональные ассоциации для каждого возможного запроса
и, когда вы делаете определенный запрос к объекту, вызывается такая функция.
Этот процесс обычно суммируется и можно сказать, что вы “посылаете сообщение”
(делаете запрос) объекту, а объект определяет, что он должен сделать с этим
сообщением (он исполняет код).
В этом промере имя типа/класса - Light, имя
этого обычного объекта Light - lt, а запросы, которые вы можете
сделать для объекта Light - это включить его, выключить, сделать ярче
или темнее. Вы создаете объект Light, определяя “ссылку” (lt) для
объекта и вызываете new для запроса нового объекта этого типа. Для
отправки сообщения объекту вы объявляете имя объекта и присоединяете его к
сообщению запроса, разделив их (точкой). С точки зрения пользователя,
предварительное определение класса - более красивый способ программирования с
объектами.
Диаграмма, показанная выше, следует формату Унифицированного
Языка Моделирования (Unified Modeling Language (UML). Каждый класс
представляется ящиком, с именем типа в верхней части ящика и членами - данными,
которые вы описываете в средней части ящика, а члены - функции
(принадлежащие объекту функции, которые принимают сообщения, которые вы
посылаете этому объекту) в нижней части ящика. Чаще всего только имя класса и
публичные члены - функции показаны в диаграмме разработки UML, так что средняя
часть не показывается. Если вы интересуетесь только именем класса, нижние части
нет необходимости показывать.
Свойства Java, краткий обзор.
Java проста, объектно-ориентированна и знакома. Система Java создана на основе *простого* языка
программирования, техника, использования которого близка к общепринятой и
обучение которому не требует значительных усилий. Java как язык
программирования является объектно-ориентированной с момента основания. Кроме
того программист с самого начала обеспечивается набором *стандартных* библиотек,
обеспечивающих функциональность от стандартного ввода/вывода и сетевых
протоколов до графических пользовательских интерфейсов. Эти библиотеки легко
могут быть расширены. Несмотря на то, что язык С++ был отвергнут, синтаксис
языка Java максимально приближен к синтаксису С++. Это делает язык знакомым
широкому кругу программистов. В то же время из языка были удалены многие
свойства, которые делают С++ излишне сложным для пользования, не являясь
абсолютно необходимыми. В результате язык Java получился более простым и
органичным, чем С++.
Надежность и безопасность Java существенно облегчает создание надежного
программного обеспечения. Кроме исчерпывающей проверки на этапе компиляции,
система предусматривается анализ на этапе выполнения. Сам язык спроектирован
так, чтобы вырабатывать у программиста привычку писать "правильно".
Модель работы с памятью, в которой исключено использование указателей, делает
невозможными целый класс ошибок, характерных для С и С++. В силу того, что Java
предназначена для работы в распределенной среде, безопасность становится
чрезвычайно важной проблемой. Требования безопасности определяют многие черты,
как языка, так и реализации всей системы.
Независимость от архитектуры и переносимость. Компилятор Java производит байт-коды, т.е. модули
приложения имеют архитектурно-независимый формат, который может быть
проинтерпретирован на множестве разнообразных платформ. Это уже не исходные
тексты, но еще не платформно-зависимые машинные коды.
Следующий шаг - "замораживание" стандарта на формат основных
встроенных типов данных. Программа, созданная на одной платформе, работает на
всех остальных. Этот стандарт фиксирован в документе, описывающем Java Virtual
Machine. Стандарт может быть реализован на любой аппаратно-программной
платформе, поддерживающей многопотоковость. Производительность. Схема
работы системы и набор байт-кодов виртуальной машины Java таковы, что позволяют
достичь высокой производительности на этапе выполнения программы:
· анализ кодов на соблюдение правил безопасности производится
один раз до запуска кодов на выполнение, в момент выполнения таких проверок уже
не нужно, и коды выполняются максимально эффективно;
· работа с базовыми типами максимально эффективна, для
операций с ними зарезервированы специальные байт-коды;
· методы в классах не обязательно связываются
динамически;
· автоматический сборщик мусора работает отдельным
фоновым потоком, не замедляя основную работу программы, но в то же время,
обеспечивая своевременный возврат свободной памяти в систему;
· стандарт предусматривает возможность написания
критических по производительности участков программы в машинных кодах.
Интерпретируемый, многопотоковый и динамический.
Интерпретируемая природа языка позволяет сделать фазу
линкования простой, инкрементальной и, следовательно, быстрой. Это резко
сокращает цикл разработки и тестирования программных фрагментов.
Многопотоковость позволяет выполнять в рамках одного приложения несколько задач
одновременно. Это становится особенно актуально в современных распределенных
приложениях, когда процессы сетевого обмена могут идти одновременно и
асинхронно. При этом программа продолжает реагировать на ввод информации
пользователем без неприятных задержек. Многопотоковость поддерживается на
уровне языка - часть примитивов синхронизации встроена в систему реального
времени, а библиотека содержит базовый класс Thread. К тому же системные
библиотеки написаны thread-safe, т.е. все они могут быть использованы в
многопотоковых приложениях. Система обеспечивает динамическую сборку программы.
Классы подгружаются по мере необходимости, причем загружены они могут быть с
любой точки сети, что позволяет сделать внесение изменений в приложения
прозрачным для пользователя. Пользователь может быть уверен, что всегда
работает со свежей версией приложения.
Базовая система Java.
Опыт показывает, что отсутствие стандартных базовых
библиотек для языка С++ чрезвычайно затрудняет работу с ним. В силу того, что
любое нетривиальное приложение требует наличия некоторого набора базовых
классов, разработчикам приходится пользоваться различными несовместимыми между
собой библиотеками или писать свой собственный вариант такого набора. Все это
затрудняет как разработку, так и дальнейшую поддержку приложений, затрудняет
стыковку приложений, написанных разными людьми.
Полная система Java включает в себя готовый набор
библиотек, который можно разбить на следующие пакеты:
· java.lang - базовый набор типов, отраженных в самом
языке. Этот пакет обязательно входит в состав любого приложения. Содержит
описания классов Object и Class, а также поддержку многопотоковости,
исключительных ситуаций, оболочку для базовых типов, а также некоторые
фундаментальные классы;
· java.io - потоки и файлы произвольного доступа. Аналог
библиотеки стандартного ввода-вывода системы UNIX. Поддержка сетевого доступа
(sockets, telnet, URL) содержится в пакете java.net;
· java.util - классы-контейнеры (Dictionary, HashTable,
Stack) и некоторые другие утилиты. Кодирование и декодирование. Классы Date и
Time;
· java.awt - Abstract Windowing Toolkit,
архитектурно-независимый оконный интерфейс, позволяющий запускать интерактивные
оконные Java-приложения на любой платформе. Содержит базовые компоненты
интерфейса, такие как события, цвета, фонты, а также основные оконные элементы
- кнопки, scrollbars и т.д.
Каждая из перечисленных характеристик по отдельности
может быть найдена в уже существующих программных пакетах. Новым является
соединение их в стройную непротиворечивую систему, которая должна стать
всеобщим стандартом.
Java – объектноориентированный язык программирования.
На сегодняшний день наиболее популярными языками
программирования являются С и С++. Из них двоих лишь С++ претендует на
объектную ориентацию. Характеристики этого языка складывались в ходе длинной
истории его развития, причем довольно хаотично, каждое новое свойство не
отменяло всех предыдущих. Стандарт языка до сих пор не зафиксирован, т.к. новые
свойства продолжают появляться по сей день. В результате С++ стал бесконечно
сложным и избыточным -- одну и ту же операцию возможно реализовать на языке множеством
способов.
Java представляет собой новую точку отсчета в программном обеспечении.
Разработчики языка взяли за основу С++, затем методично удалили из него черты,
которые:
· делают невозможным контроль безопасности приложений;
· не являются абсолютно необходимыми, чаще мешают
программисту, чем облегчают его задачу;
· являются источником наиболее трудно и поздно
распознаваемых ошибок.
В то же время в языке Java полностью сохранен
"дух" программирования на С++, опытным С++ программистам потребуется
одна-две недели на освоение самого языка, а огромный объем программного
обеспечения, уже созданного с использованием С++, может быть адаптирован под
новый язык относительно легко.
Основные свойства языка программирования Java.
Встроенные (примитивные) типы данных.
В языке Java, так же как и в С++, существует набор
встроенных типов данных, которые (так же как и в С++) не являются объектами.
Набор их также сходен с набором базовых типов С++ за некоторыми исключениями.
Numeric.
Характерным отличием от С++ является то, что бинарное
представление чисел отныне фиксировано:
· целые числа: 8-бит byte, 16-бит short, 32-бит int,
64-бит long. Все числа со знаком, ключ unsigned из языка удален;
· числа с плавающей точкой. 32-бит float, 64-бит double.
Представление должно соответствовать стандарту IEEE 754.
Character.
Отличаются от С++ как синтаксисом, так и
представлением. Тип character есть 16-разрядное число без знака (диапазон
0-65,535). Кодировка соответствует стандарту Unicode. В силу того, что эта
кодировка в идеале должна охватывать все существующие в мире языки, это
представление должно облегчить локализацию приложений.
Boolean.
Этот тип данных не выделен в С++, однако неявно
присутствует практически во всех программах. В Java тип называется boolean,
может принимать значения true и false и не может (в отличие от С++) быть
преобразован в другой тип.
Операторы.
Добавлен новый оператор >>> логического
сдвига вправо (т.к. нет беззнаковых целых чисел). Встроенная операция слияния
строк (оператор +).
Массивы.
В отличие от С++ массивы в Java являются полноценными
объектами с определенным runtime представлением. Декларация:
Point myPoints[];
резервирует ссылку на массив, а не место под реальный
объект. Сам массив может быть затем создан выполнением:
myPoints = new Point[10];
а его элементы заполнены операцией типа:
myPoints[2] = new Point();
Размер массива может быть получен во время выполнения
программы:
howMany = myPoints.length;
Значение индекса проверяется при каждом обращении, при
ошибке возбуждается исключительная ситуация.
Указатели полностью исключены из языка вместе с целой категорией трудноуловимых
ошибок "замедленного действия". К тому же наличие указателей
противоречит требованиям безопасности и усложняет реализацию сборщика мусора.
Strings.
Строки в Java являются полноценными объектами. Они
делятся на текстовые константы (Strings) и модифицируемые строки
(StringBuffer). Компилятор позволяет явно определять текстовые литералы в
программе подобно тому, как это делается в С++.
String hello = "Hello world!";
Ссылка hello инициируется объектом класса String на
основе представления "Hello world!" в кодировке Unicode.
Оператор "+" может быть применен к строкам, например
System.out.println("There are" + num +
"characters in the file.");
Multi-Level Break.
В Java отсутствует выражение goto. Анализ С/С++
текстов показал, что подавляющее число случаев использования этого оператора
связано с необходимостью выхода из вложенного цикла. Для отработки таких
ситуаций в Java перед началом блока может ставиться метка, а инструкции break и
continue также могут сопровождаться меткой, на которую должен быть осуществлен
переход. Например:
test:
for(int i = 0; i < 10; i++)
for(int j = 0; j < 10; j++)
if( i > 3)
break test;
Управление памятью, сборка мусора.
Необходимость явно управлять памятью в С/С++
программах всегда была большой занозой для программистов. Мало того, что сами
программы изобиловали вызовами функции free или операторами delete,
непосредственно к логике программы отношения не имеющими. Ошибки, связанные с
неосвобождением памяти или наоборот, с удалением уже однажды удаленных
объектов, относятся к категории ошибок наиболее трудных для обнаружения и
исправления.
Java полностью снимает эту заботу с программиста.
Автоматический сборщик мусора обязан быть встроен в run-time системы. Память
объектов, на которые больше нет ссылок, в конце концов возвращается в систему.
Опыт показывает, что несмотря на относительную сложность сборщиков мусора,
производительность системы в целом может оказаться не меньше, а часто и больше,
чем при явном освобождении памяти программой.
Сборка мусора в фоновом режиме.
Одно из преимуществ того, что Java-приложения
многопотоковые, заключается в том, что сборка мусора может производиться в
фоновом потоке. Этот поток имеет меньший приоритет выполнения, чем остальные,
поэтому система всегда готова ответить на действия пользователя, отсутствуют
"периоды молчания", в которые производится только сборка мусора. С
другой стороны, паузы в операциях пользователя сборщик мусора может
использовать для своей работы, обеспечивая наличие свободной памяти в моменты,
когда это необходимо.
Встроенная синхронизация потоков.
Java поддерживает многопотоковость не только на уровне
библиотек, но и на уровне самого языка, что значительно облегчает построение
приложений, надежно работающих в многопотоковом режиме.
Свойства, присутствующие в С и С++, и удаленные из
Java.
Конструкция typedef, препроцессор. Конструкция typedef была унаследована С++ из С. Из
Java она выброшена совсем. Необходимость в макропроцессоре также во многом
отпала при написании программ на С++. Почти все, для чего использовались
макрорасширения, можно было сделать более элегантным и надежным образом,
используя конструкции самого языка. Система неявно поощряла создание каждым
программистом своего собственного подмножества языка, неизвестного остальному
миру. По мере разрастания кодов увеличивается тот смысловой контекст, в котором
компилятор интерпретирует каждую строку программы. Уже в проектах среднего
размера существенно возрастает нагрузка на компилятор, не говоря уже о нагрузке
на память программиста. Единственная оставшаяся важная функция препроцессора
позволить включение в программу файлы-заголовки с описаниями классом. Эта
операция может быть выполнена более просто и эффективно, если позволить
компилятору читать подготовленные бинарные файлы с описанием классов. Последний
путь был выбран при создании языка Java. Все эти соображения позволили
полностью исключить необходимость использования текстового препроцессора в
языке Java.
Struct и union. Структуры не имеют смысла в Java, их роль полностью выполняют классы.
Использование конструкций типа union для типизованных объектов также больше не
нужно язык позволяет определить тип объекта при исполнении программы. Функции.
В этом смысле Java чисто объектно-ориентированная система. Функции и
процедуры, не привязанные к контексту какого-либо объекта, больше не
присутствуют в системе. В ситуации, когда функция логически не привязана к
определенному экземпляру класса, она может быть создана как метод самого класса
(т.е. иметь тип static).
Множественное наследование. Последовательная реализация концепции множественного
наследования в С++ привела к существенным сложностям как в создании
компиляторов, так и в использовании его (множественного наследования) в
программах. В качестве альтернативы Java использует понятие интерфейса
определяющего набор методов, которые должны быть определены в классе,
реализующем этот интерфейс. Интерфейс может также содержать определение
некоторых констант. То, чего интерфейс содержать не может - это реализации
методов или изменяемые поля данных. Классы, которые объявлены, как реализующие
тот или иной интерфейс, обязаны реализовать все методы, объявленные в
интерфейсе.
Goto. см.
выше описание операторов continue и break с меткой.
Перегрузка операторов. Опыт использования перегруженных операторов в С++
показывает, что они имеют смысл в довольно ограниченном наборе ситуаций. С
другой стороны, злоупотребление этим свойством может сделать программу
абсолютно непонятной. Единственное "встроенное" в язык Java
исключение -- возможность использования оператора "+" для склеивания
строк (см. выше).
Автоматическое преобразование типов. В языке Java запрещено автоматическое преобразование
типов, широко используемое (и рекомендуемое) в С++. Чтобы преобразовать элемент
одного типа в другой, необходимо указать это явно, например:
int myInt;
double myFloat = 3.14159;
myInt = myFloat; // допустимо в С++, недопустимо в
Java
myInt =
(int)myFloat; // допустимо в Java
Исключение составляет преобразование между встроенными
численными типами без потери информации.
Указатели. Большинство
исследований показали, что применение указателей в С/С++ являются одним из
основных источников ошибок. В силу того, что в языке больше не стало структур,
а массивы и строки превратились в полноценные объекты, надобность в указателях
отпала. Содержимое строк и массивов доступно только по индексам, причем
контроль доступа во время выполнения не позволяет выходить за границы массива
или строки.
Итак, показано два из основных свойства языка
программирования Java:
· знакомый - Java сохраняет стиль программирования C и
С++;
· простой - количество конструкций языка в Java
существенно сокращено по сравнению с С и С++.
Язык Java объектно-ориентирован.
Система Java создавалась объектно ориентированной с
самого начала. Объектно-ориентированная парадигма наиболее удобна при создании
программного обеспечения типа клиент-сервер, а также для организации
распределенных вычислений. Одна из черт, присущих объектам, заключается в том,
что объекты обычно переживают процедуру, их создающую. Они затем могут
перемещаться по сети, храниться в базах данных и т.д.
Идейными наследниками Java являются такие языки, как C++, Eiffel, Smalltalk и
Objective C. За исключением примитивных типов данных, практически все в языке
является объектом.
Основные требования к объектно-ориентированной системе:
· инкапсуляция - сокрытие реализации за абстрактным
интерфейсом;
· полиморфизм - одно и то же сообщение, посланное
различным объектам, приводит к выполнению разных операций;
· наследование - новые классы могут наследовать данные и
функциональность уже существующих классов;
· динамическое связывание - новые классы могут
появляться в системе откуда угодно, в том числе и из сети. Необходимо иметь
возможность динамически включать их в систему.
Объектная модель Java.
Классы.
Класс есть языковая конструкция, определяющая поля
данных объектов данного класса (instance variables) и их поведение (methods).
Практически класс в Java сам по себе не является объектом. Это лишь шаблон,
который определяет, из каких частей будет состоять объект, созданный с помощью
этого класса, и как он будет себя вести.
Простейший пример описания класса:
class Point extends
Object {
public double x;
public double
y;
}
Создание объекта определенного класса.
Создать объект описанного выше класса можно
декларацией:
Point myPoint; // объявление переменной типа Point
myPoint = new Point(); // инициализация
а обратиться к полям данных следующим образом:
myPoint.x = 10.0;
myPoint.y = 25.7;
Конструкторы.
При объявлении класса, возможно, указать методы
специального вида, называемые конструкторами и предназначенные для
инициализации созданного объекта. Имя этих методов должно совпадать с именем
класса, они могут иметь какое-то количество аргументов, например:
class Point extends
Object {
Point() {
x = 0.0;
y = 0.0;
}
Point(double x, double y) {
this.x = x;
this.y = y;
}
public double x;
public double y;
}
а использованы они могут быть следующим образом:
Point a;
Point b;
a = new Point();
b = new Point(1.0, 2.0);
обратите внимание на имя this в определении
конструктора с аргументами. Оно используется для обозначения самого объекта, в
методе которого мы находимся, в тех случаях, когда ссылка на этот объект не
подразумевается неявно.
Методы и посылка сообщений.
Если один объект в программе заставляет другой
выполнить какую-то операцию, то принято говорить, что он посылает сообщение
другому объекту. Например, мы можем переопределить наш класс следующим образом:
Pclass Point extends Object {
private double x;
private double y;
public void setX(double x) {
this.x = x;
}
public void setН(double y) {
this.y
= y;
}
...
}
Мы теперь сделали поля x и y недоступными извне
класса, но для изменения их состояния предусмотрели специальные методы setX и
setY.
Финализаторы. Специальное
имя finalize зарезервировано для метода, который будет вызван сборщиком мусора
перед тем, как объект будет уничтожен. В силу того, что Java освобождает нас от
необходимости самим следить за освобождением памяти, занимаемой объектами, необходимость
в таких методах обычно возникает лишь тогда, когда надо освободить какие-то
внешние ресурсы, например, закрыть открытый файл:
protected void
finalize() {
try {
file.close();
} catch (Exception e) {
}
}
Производные классы.
Наследование классов позволяет создавать новые типы
объектов, эффективно использующие функциональность уже существующих типов.
Новый тип обычно называется производным классом, а тот, чьи свойства
наследуются -- базовым классом. Например, мы можем описать новый класс, соответствующий
координатам точки в трехмерном пространстве, на основе уже описанного класса
для точки на плоскости:
class ThreePoint
extends Point {
protected double z;
ThreePoint() {
super();
z = 0.0;
}
ThreePoint(double x, double y, double z) {
super(x, y);
this.z = z;
}
}
Здесь мы добавили новую координату z, а поля x и y (и
методы доступа к ним) унаследовали от класса Point.
Контроль доступа.
Контроль доступа к данным и методам объекта в Java
несколько отличается от С++. Помимо трех уровней доступа, имеющихся в С++
(public, private, protected) имеется четвертый, находящийся где-то между
уровнями public и protected. Он не имеет имени и используется по умолчанию,
когда явно не указан другой уровень. Поля этого типа доступны внутри только
одного программного пакета. Пакет представляет группу классов, объединенных в
одну логическую группу. Например, классы, описывающие точку и прямоугольник в
графическом пакете, могут иметь прямой доступ к полям данных друг друга,
запрещенный обычно для остального мира. Также следует отметить, что контроль
доступа в C++ помогает программисту лишь при построении программы. Различия
между полями, помеченными public и private, отсутствуют в выполняемом модуле,
созданном с использованием этого языка. В Java контроль доступа реален, т.к. он
осуществляется не только при компиляции, но и непосредственно перед запуском
кодов на выполнение виртуальной машиной.
Переменные и методы класса.
Как и С++ язык Java позволяет использовать переменные
и методы, принадлежащие классу целиком. Для определения их используется
ключевое слово static. Естественно, что методы самого класса не могут
оперировать данными и методами объекта класса, т.к. они не относятся ни к
какому определенному объекту.
Например, версия реализации класса Rectangle может
быть задана следующим образом:
class Rectangle
extends Object {
static final int version = 2 ;
static final
int revision
= 0 ;
}
Ключевое слово final означает, что значение поля
окончательное и изменению не подлежит (это константа).
Абстрактные методы.
Абстрактные методы - это методы, для которых в данном
классе не определена их реализация. Мы указываем лишь на необходимость наличия
методов с данным протоколом. Конкретная реализация должна быть осуществлена
классами-наследниками. В то же время остальная, "неабстрактная" часть
класса может содержать конкретную информацию, которая может быть использована
производными классами. Например:
abstract class Graphical
extends Object
{
protected Point lowerLeft;
protected Point upperRight;
...
public void setPosition(Point ll, Point ur)
{
lowerLeft = ll;
upperRight = ur;
}
abstract void drawMyself();
}
class Rectangle
extends Graphical
{
void
drawMyself()
{
....
}
}
Здесь мы описали класс Graphical. В нем объявлено
свойство всех графических элементов иметь какое-то положение на плоскости.
Каждый элемент обязан также иметь метод для рисования самого себя, однако
никакого метода рисования по-умолчанию быть не может. Класс Rectangle,
представляющий собой конкретную реализацию для типа Graphical, реализует также
этот метода для объекта прямоугольной формы.
Класс, содержащий хотя бы один абстрактный метод,
должен быть объявлен как абстрактный. По понятным причинам создание экземпляров
такого класса невозможно.
Итак, освещены следующие стороны Java как
объектно-ориентированного языка программирования:
· Классы определяют шаблон, по которому создаются
конкретные объекты;
· Поля данных объекта определяют состояние объекта;
· Объекты обмениваются сообщениями между собой.
Получение сообщения приводит к вызову одного из методов;
· Методы определяют поведение объекта данного класса.
Методы для разных классов могут иметь одно и то же имя, но различное
содержание.
Нейтральность к архитектуре.
Достигается, прежде всего, стандартизацией
"бинарного формата кодов". Промежуточный код не зависит от конкретной
аппаратной платформы, операционной системы и типа оконного интерфейса. Для
того, чтобы программы, написанные на Java, могли работать на данной
аппаратно-программной платформе, достаточно, чтобы для нее была создана лишь
соответствующая виртуальная машина.
Байт-коды.
Компилятор Java производит не "машинные
коды" подобно тому, как это делает, например, компилятор языка С. Вместо
этого генерируются так называемые байт-коды: высокоуровневые машиннонезависимые
коды для абстрактной машины, которая должна быть реализована в виде интерпретатора
Java и run-time системы. Сама по себе идея байт-кодов не нова, они широко
используются в различных системах начиная с середины семидесятых годов.
Особенности Java байт-машины следующие:
· набор ее кодов легко не только интерпретировать, но и
эффективно скомпилировать "на лету" непосредственно в машинные коды
для любой современной аппаратной платформы;
· коды содержат избыточную информацию, которая позволяет
проверить их на безопасность выполнения.
Переносимость на другие архитектуры.
Кроме независимости кодов от конкретной архитектуры
Java жестко специфицирует формат базовых типов данных. Без этого одна и та же
программа, скомпилированная для разных аппаратных платформ, вела бы себя
по-разному. Например, стандарт С/С++ не предусматривает конкретного представления
для целого типа int. Предполагается, что этому типу соответствует основной
формат машинного слова для данной архитектуры. В результате программа,
написанная для 32-разрядного процессора, чаще всего переносится на 16-разрядную
архитектуру с очень большими усилиями. Таким образом, решение зафиксировать
форматы базовых типов данных в Java вполне естественно. Каждая Java-машина
обязана реализовать их следующим образом:
byte - 8-bit two's complement
short - 16-bit
two's complement
int - 32-bit two's
complement
long - 64-bit two's
complement
float - 32-bit IEEE
754 floating point
double - 64-bit
IEEE 754 floating point
char - 16-bit
Unicode character
Выбор именно такого набора базовых типов и их формата
обусловлен тем, что практически любой современный центральный процессор
поддерживает эти форматы. Более того, перенос самой среды может быть
осуществлен достаточно просто. Компилятор Java сам написан на этом языке.
Виртуальная машина написана на ANSI C в соответствии со стандартом POSIX.
Спецификация языка не содержит ссылок типа "в зависимости от конкретной
реализации".
Интеллектуальность.
Система Java предназначена для создания программного
обеспечения, которое должно быть интеллектуальным, предельно надежным и
безопасным по множеству параметров. Особое внимание уделяется как ранней
диагностике возможных проблем, так и поздней, во время выполнения кодов.
Жесткая проверка на этапе компиляции и во время
выполнения.
Компиляция с языка Java предусматривает жесткую
проверку исходных текстов, множество ошибок может быть выявлено уже на этом
этапе. Одним из преимуществ языка С++ как строго типизованного языка является
возможность раннего выявления некоторых категорий ошибок. Однако во многом этот
язык наследует свойства С, позволяя нарушать требования строгого объявления
функций и методов. Язык Java требует явного объявления прототипов и не
поддерживает характерных для С неявных преобразований. Значительное число
проверок, производимых компилятором, повторяются виртуальной машиной непосредственно
перед выполнением приложения. Линкер получает всю информацию о прототипах
методов и на основе ее производит такую же проверку, как и компилятор, позволяя
избежать расхождений в версиях между отдельными модулями. Наиболее существенное
отличие языка Java от С или С++ заключается в том, что архитектура Java не
позволяет случайно или намеренно повредить память программы. Вместо арифметики
указателей Java использует полноценные объекты для массивов и строк, что
позволяет контролировать индексы доступа к ним во время выполнения. Кроме того,
невозможны превращения между целыми числами и указателями. Естественно, что все
это не может полностью гарантировать программиста от любых ошибок, однако, Java
устраняет целый класс их, существенно облегчая задачу разработчика.
Интерпретируемый и динамический.
Для разработчика, использующего в своей работе обычные
компилируемые языки, цикл разработки обычно выглядит следующим образом:
редактировать текст -- скомпилировать его -- собрать программу линкером --
загрузить -- довести ее до "падения" -- рассмотреть обломки -- начать
все с начала. Кроме того, приходится постоянно следить за тем, какие из
исходных текстов подлежат перекомпиляции. Для этого обычно используются
дополнительные инструменты (например, популярная утилита make), часто не
связанные с конкретным языком программирования и использующие крайне
консервативный подход -- перекомпилировано должно быть все, что теоретически
могло быть затронуто изменением. По мере того, как исходные тексты приложения
разрастаются до сотен тысяч строк, взаимозависимости связывают части проекта
крепче и крепче, скорость разработки приближается к нулю. Система Java в силу
своей интерпретируемой и динамической природы значительно более подходит для
целей быстрой разработки надежных программ. Как уже было отмечено выше, на
выходе компилятора Java мы получаем байт-коды для Виртуальной Машины Java.
Полная спецификация виртуальной машины открыта и общедоступна. Она может быть реализована
практически на любой из современных программно-аппаратных платформ. После этого
программы на языке Java могут быть собраны из любых мест в сети и работать на
этой платформе так же, как и на любой другой. Процесс сборки программы
(linking) существенно ускорен по сравнению с обычными компилируемыми системами.
Он представляет собой подгрузку необходимых классов и производится
инкрементально, т.е. недостающие части подгружаются по мере надобности, что
также приводит к сокращению времени цикла разработки.
Динамическая загрузка и связывание.
То, что Java является интерпретатором, позволяет
расширять систему динамически. Отдельные классы загружаются лишь по мере
необходимости и могут быть собраны из различных мест в сети. Перед запуском на
выполнение коды проходят жесткую проверку. В настоящее время
объектно-ориентированный подход стал общепринятым. В качестве языка
программирования при этом обычно выбирают С++. Однако этот язык обладает
определенным недостатком, который известен под названием "проблемы хрупкости
базового класса" (fragile superclass problem). "Проблема хрупкости
базового класса" в С++. Эта проблема возникает как побочный эффект
реализации модели С++. Каждый раз, когда Вы добавляете новый метод или
переменную в класс, все остальные модули приложения, использующие этот класс,
требуют перекомпиляции. В противном случае программа успешно собирается, а при
запуске так же успешно разваливается. Даже при использовании специальных утилит
типа make неточное отслеживание взаимозависимостей между классами является
неиссякающим источником ошибок. Эта проблема "хрупкости базового
класса" также часто именуется как проблема "постоянной
перекомпиляции". Избежать ее можно путем разнообразных уловок, обычно
связанных с отказом от прямого использования объектно-ориентированных свойств
языка.
Решение "проблемы хрупкости базового
класса".
В системе программирования Java эта проблема решается
в несколько этапов. Во-первых, компилятор не разрешает ссылок вплоть до
численных значений. Напротив, символьная информация передается вместе с
байт-кодами для проверки и интерпретации. Окончательное связывание имен
производится интерпретатором в момент загрузки класса. После этого ссылки уже
"прописаны", как непосредственные указатели, и интерпретатор может
работать с нормальной скоростью. Во вторых то, как объект должен выглядеть в
памяти машины, определяется не компилятором, а самим интерпретатором.
Добавление в класс новых переменных или методов не требует изменений в
остальных кодах.
Понятие интерфейса в языке Java.
Под интерфейсом (interface) в Java понимается
спецификация дополнительного набора методов, которые "обязан знать"
объект. Идея заимствована из языка Objective C, где такая спецификация
называется протоколом (protocol). Интерфейс не включает в себя модифицируемых
переменных или выполняемых кодов. Класс может реализовать любое количество
интерфейсов, без всех трудностей организации иерархии классов при множественном
наследовании в С++.
Представление в исполняемом модуле.
Классы в Java реально представлены в работающей
системе. Существует выделенный класс по имени Class, экземпляры которого
создаются виртуальной машиной и содержат информацию о всех классах в системе.
Для любого объекта возможно найти соответствующий ему объект, представляющий
его класс. Класс может сообщить свое имя и ссылку на своего непосредственного
предшественника в иерархии. Возможен также поиск классов по имени.
Интерпретируемая и динамическая природа языка Java
предоставляет разработчику определенные преимущества:
· интерпретирующее окружение позволяет быстрое создание
прототипов без обычного цикла перекомпиляции и сборки;
· среда динамически расширяема, т.к. классы подгружаются
на лету по мере необходимости;
· характерная для С++ проблема "хрупкого базового
класса" решена в силу того, что расположение элементов объекта в памяти
определяется не на этапе компиляции, а на этапе выполнения.
Безопасность в Java.
По мере стремительного роста использования глобальных
сетей в спектре услуг, простирающемся от электронного распространения
программного обеспечения и объектов multimedia до электронных платежей,
безопасность становится ключевой проблемой. Мы коснемся того, как компилятор
Java и run-time предотвращают создание и проникновение "диверсионных"
кодов.
Компилятор и run-time включают в себя несколько
уровней обороны против потенциально опасных программ. В общем случае система
исходит из предположения, что доверять нельзя никому. Следующие несколько
секций касаются проблемы более детально.
Резервирование и распределение памяти.
Во-первых, решение о распределении памяти принимает не
компилятор, а run-time система. Оно может зависеть от особенностей архитектуры
конкретной системы.
Во-вторых, язык не поддерживает указателей.
Символические ссылки на объекты разрешаются интерпретатором на этапе
выполнения. Выделение памяти и работа со ссылками находятся полностью под
управлением системы и не доступны непосредственно из программы. Отложенное до
последнего момента размещение структур в памяти не позволяет определить
реальное положение полей класса по его описанию.
Процесс проверки байт-кодов.
Несмотря на то, что компилятор гарантирует, что коды
не нарушают требований безопасности, если они были получены из других точек
сети возникает следующая проблема: коды могут быть созданы не компилятором
Java, а другими средствами. Или они могут быть намеренно модифицированы после
создания. Поэтому run-time система подвергает полученные коды тщательной
проверке. Проверка включает в себя несколько этапов, начиная с контроля
целостности формата полученного файла до анализа каждого фрагмента кодов на
предмет выполнения следующих правил:
· нет незаконных манипуляций с указателями;
· нет попыток нарушения прав доступа;
· объекты используются в строгом соответствии с их типами,
например, объекты класса InputStream используются только как InputStream и
никак иначе.
Верификатор байт-кодов.
Верификатор байт-кодов (bytecode verifier) сканирует
байт-коды, извлекает информацию о типах объектов в каждой точке выполнения
фрагмента кода.
На приведенном рисунке изображен путь от исходных
текстов на языке Java через компилятор Java, верификатор кодов до
интерпретатора. Важно отметить, что загрузчик и верификатор байт-кодов не
делают никаких предположений относительно происхождения кодов, получены они с
локальной файловой системы или с другого континента. Верификатор гарантирует,
что любой код, прошедший проверку, может быть использован интерпретатором без
риска повредить его (интерпретатор), а именно:
· не может произойти переполнение или
"исчерпание" стека;
· параметры для инструкций байт-машины имеют нужный тип;
· доступ к полям и методам объектов не нарушает
объявленных в классе правил (public, private, protected).
Правила безопасности при загрузке.
В ходе выполнения программы может потребоваться
загрузка дополнительных классов. После того как, полученный код прошел проверку
на валидность байт-кодов, он поступает в загрузчик кодов. Для загрузчика все
пространство имен загружаемых классов может быть подразделено на отдельные
области (name spaces). Причем классы, полученные локально (заслуживающие
безусловного доверия), и классы, присланные по сети из остального мира (и
потенциально враждебные), находятся в разных пространствах имен. При разрешении
ссылки на какой-либо класс он ищется, прежде всего, в локальном пространстве.
Это не позволяет "внешним" кодам подменить один из базовых классов в
системе.
Безопасность в сетевом пакете.
Сетевой пакет Java включает в себя поддержку различных
сетевых протоколов (FTP, HTTP, Telnet и т.д.). Это - передовая линия защиты от
вторжения по сети. Осторожность при установке прав сетевого доступа в локальную
систему может быть доведена до параноидальной. Вы можете
· запретить сетевой доступ вообще;
· разрешить доступ только к тому узлу, с которого был
получен код;
· разрешить доступ только к узлам за пределами firewall,
если код также получен с той стороны firewall;
· разрешить любой сетевой доступ.
Система Java достаточно безопасна, чтобы жить в
сетевом окружении. Нейтральность к архитектуре и переносимость делают ее
достаточно привлекательной для создания распределенных по сети приложений.
Многопотоковость в Java.
Современного пользователя компьютера все чаще
раздражает ситуация, когда программа способна выполнять в один момент времени
лишь одну задачу. Реальный мир наполнен событиями, происходящими одновременно и
независимо. Пользователь требует от компьютера адекватной реакции.
К сожалению, написание программ, отвечающих этим
требованиям, значительно сложнее, чем написание программ, выполняющихся
последовательно. Они могут быть созданы с использованием С или С++, однако
делать это сложнее, т.к. отсутствует поддержка в самом языке, а также
большинство существующих на сегодняшний день внешних библиотек часто не могут
быть использованы в таких программах в силу того, что они не удовлетворяют так
называемому thread-safe условию. Термин thread-safe означает, что каждая
функция данной библиотеки может быть использована одновременно несколькими
потоками. Основная проблема при прямом управлении потоками состоит в том, что
Вы никогда не можете быть полностью уверены, что поставили все нужные замки
(locks) и вовремя их освободили. При преждевременном завершении процедуры или
при возникновении исключительной ситуации замок может остаться неснятым, что
обычно приводит к блокировке программы (deadlock).
Встроенная многопотоковость - существенная черта
архитектуры Java. Стандартная библиотека включает в себя класс Thread, с
методами, позволяющими стартовать новый поток, завершить его работу и проверить
текущее состояние потока. Интеграция примитивов синхронизации непосредственно в
язык упрощает работу с ними. Потоки в Java вытесняющие (pre-emptive), а также
могут выполняться в режиме разделения времени (time-sliced), но только на
платформах, которые поддерживают это. В системах, в которых такая поддержка
отсутствует, после того, как поток был запущен, он может быть прерван только
другим потоком с более высоким приоритетом. Если ваше приложение требует
больших периодов вычислений, рекомендуется явно отдавать управление другим
потокам (вызовом Thread.yield()).
Интегрированная синхронизация потоков.
Система Java содержит поддержку многопотоковости как
на уровне синтаксиса языка, так и на уровне библиотек и системных вызовов. На
уровне самого языка методы, объявленные с признаком synchronized, гарантировано
не будут выполняться одновременно для данного объекта. Методы запускаются под
управлением монитора (monitor). Каждый класс и объект имеют свой собственный
монитор. Если объект находится в состоянии выполнения одного из
синхронизованных методов, попытка вызвать этот метод или любой другой
синхронизованный метод для этого же объекта из другого потока
приостанавливается до того момента, когда выполнение метода каким-то образом завершится
(обычным образом или в результате возбуждения исключительной ситуации).
При программировании с использованием
объектно-ориентированного подхода одними из самых главных понятий являются
понятия класса и объекта (экземпляр класса).
Категория вопросов по объектам и классам в java
покрывает следующие вопросы:
· Класс (class);
· Экземпляр класса (объект/instance), инстанциирование
объектов;
· Поля (fields) и методы (methods) класса, конструкторы
(constructors) класса;
· Статические методы;
· Ссылки на объекты (references);
· Импорт пакетов (статический импорт не рассмотрен).
При ответе на вопросы данного раздела необходимо
обратить внимание на ссылки - где ссылки (references) теряются при присвоении,
а где ссылка на объект остается.
Также необходимо следить за модификаторами методов
(methods) и учитывать видимость статических (static) и нестатических
(non-static) методов между собой.
Распространенными являются вопросы о классе String и
его экземплярах. Не следует забывать, что String является неизменяемым
(immutable), а также все, что с этим связано.
Рассмотрим несколько примеров по классам и объектам в java:
Перечислите все валидные сигнатуры конструкторов
класса Clazz:
· Clazz(String name);
· Clazz Clazz(String name);
· int Clazz(String name);
· void Clazz(String name);
· Clazz(name);
· Clazz().
Конструктор класса это тоже метод, но у него нет возвращаемого
значения (даже того типа, что и класс). Также у конструктора должен
присутствовать список формальных параметров или же параметры должны
отсутствовать вообще.
Таким образом нам подходят 2 ответа: Clazz(String
name) и Clazz().
Скомпилируется ли следующий код, если оба класса будут
объявлены в файле Test.java?
//Test.java
public class Car{
public String myCar = "Ferrari" ;
}
public class Test{
public static void main(String ... args){
Car myCar = new Car();
System.out.println(myCar.myCar);
}
}
Код не скомпилируется из-за класса Car. Только один из
классов в файле может быть объявлен как public.
Если предоставить в распоряжение программиста только язык
программирования и не снабдить его набором готовых модулей, предназначенных для
решения самых распространенных задач, ему придется отвлекаться на множество
мелких деталей.
Обычно все профессиональные системы разработки
приложений на языке программирования C++ содержат в своем составе набор
стандартных библиотечных функций или библиотеки классов. В комплекте со всеми
средствами разработки Java поставляются достаточно развитые библиотеки классов,
значительно упрощающие программирование. В этом разделе мы кратко расскажем о
составе и назначении библиотек классов Java.
В языке Java все классы происходят от класса Object,
и, соответственно, наследуют методы этого класса. Некоторые библиотеки классов
подключаются автоматически, и мы будем называть их встроенными. К таким
относится, в частности, библиотека с названием java.lang. Другие библиотеки
классов вы должны подключать в исходном тексте приложения Java явным образом с
помощью оператора import.
Очень часто в наших приложениях вместо базовых типов
переменных мы будем использовать объекты встроенных классов, которые называются
замещающими классами (wrapper classes). Ниже мы перечислили названия этих
классов и названия базовых типов данных, которые они замещают:
|
Базовый
тип данных
|
Замещающий
класс
|
|
boolean
|
Boolean
|
|
char
|
Character
|
|
int
|
Integer
|
|
long
|
Long
|
|
float
|
Float
|
|
double
|
Double
|
Заметим, что для преобразования базовых типов данных в
объекты замещающего класса и обратно вы не можете применять оператор
присваивания. Вместо этого необходимо использовать соответствующие конструкторы
и методы замещающих классов.
Класс String.
Класс String предназначен для работы с такими часто встречающимися
объектами, как текстовые строки. Методы этого класса позволяют выполнять над
строками практически все операции, которые вы делали раньше при помощи
библиотечных функций C. Это преобразование строки в число и обратно с любым
заданным основанием, определение длины строки, сравнение строк, извлечение
подстроки и так далее.
Хотя в языке Java не допускается перезагрузка
(переопределение) операторов, для объектов класса Stirng и объектов всех
произошедших от него классов сделана встроенная перезагрузка операторов
"+" и "+=". С помощью этих операторов можно выполнять
слияние текстовых строк, например:
System.out.println("x = " + x + '\n');
Здесь в качестве параметра функции println передается
текстовая строка, составленная из трех компонент: строки "x = ",
числа x и символа перехода на следующую строку '\n'. Значение переменной x
автоматически преобразуется в текстовую строку (что выполняется только для
текстовых строк) и полученная таким образом текстовая строка сливается со
строкой "x = ".
Другие встроенные классы.
Среди других встроенных классов отметим класс Math,
предназначенный для выполнения математических операций, таких как вычисление
синуса, косинуса и тангенса.
Предусмотрены также классы для выполнения запуска
процессов и потоков, управления системой безопасности, а также для решения
прочих системных задач.
Библиотека встроенных классов содержит очень важные
классы для работы с исключениями. Эти классы нужны для обработки ошибочных
ситуаций, которые могут возникнуть (и возникают!) при работе приложений или
аплетов Java.
Ниже мы кратко перечислим подключаемые библиотеки
классов для того чтобы вы могли оценить возможности набора классов Java. Подробное
описание этих классов есть в справочной системе Java WorkShop и в различной
литературе, посвященной Java. Мы же ограничимся описанием тех классов, которые
будем использовать в наших примерах приложений.
Библиотека классов java.util.
Библиотека классов java.util очень полезна при
составлении приложений, потому что в ней имеются классы для создания таких
структур, как динамические массивы, стеки и словари. Есть классы для работы с
генератором псевдослучайных чисел, для разбора строк на составляющие элементы
(токены), для работы с календарной датой и временем.
Библиотека классов java.io.
В библиотеке классов java.io собраны классы, имеющие
отношение к вводу и выводу данных через потоки. Заметим, что с использованием
этих классов можно работать не только с потоками байт, но также и с потоками
данных других типов, например числами int или текстовыми строками.
Библиотека классов java.net.
Язык программирования Java разрабатывался в
предположении, что им будут пользоваться для создания сетевых приложений.
Поэтому было бы странно, если бы в составе среды разработки приложений Java не
поставлялась библиотека классов для работы в сети. Библиотека классов java.net
предназначена как раз для этого. Она содержит классы, с помощью которых можно
работать с универсальными сетевыми адресами URL, передавать данные с
использованием сокетов TCP и UDP, выполнять различные операции с адресами IP.
Эта библиотека содержит также классы для выполнения преобразований двоичных
данных в текстовый формат, что часто бывает необходимо.
Библиотека классов java.awt.
Для создания пользовательского интерфейса аплеты Java
могут и должны использовать библиотеку классов java.awt. AWT - это сокращение
от Abstract Window Toolkit (инструментарий для работы с абстрактными окнами).
Классы, входящие в состав библиотеки java.awt,
предоставляют возможность создания пользовательского интерфейса способом, не
зависящим от платформы, на которой выполняется аплет Java. Вы можете создавать
обычные окна и диалоговые панели, кнопки, переключатели, списки, меню, полосы
просмотра, однострочные и многострочные поля для ввода текстовой информации.
Библиотека классов
java.awt.image.
В среде любой операционной системы работа с
графическими изображениями является достаточно сложной задачей. В операционной
системе Windows для этого применяется графический интерфейс GDI. Если вы будете
рисовать графические изображения в среде OS/2 или X-Windows, вам, очевидно,
придется использовать другой программный интерфейс. Большую сложность также
вызывает разбор заголовков графических файлов, так как они могут иметь
различный формат и иногда содержат неправильную или противоречивую информацию.
Когда вы программируете на Java, рисование и обработка
графических изображений выполняется намного проще, так как вам доступна
специально предназначенная для этого библиотека классов java.awt.image. Помимо
широкого разнообразия и удобства, определенных в ней классов и методов, отметим
способность этой библиотеки работать с графическими изображениями в формате
GIF. Этот формат широко используется в Internet, так как он позволяет сжимать
файлы графических изображений во много раз без потери качества за счет
устранения избыточности.
Библиотека классов
java.awt.peer.
Библиотека классов java.awt.peer служит для
подключения компонент AWT (например, кнопок, списков, полей редактирования
текстовой информации, переключателей и так далее) к реализациям, зависящим от
платформы, в процессе создания этих компонент.
Библиотека классов
java.applet.
Как нетрудно догадаться из названия, библиотека
классов java.applet инкапсулирует поведение аплетов Java. Когда вы будете
создавать свои аплеты, вам будет нужен класс Applet, расположенный в этой
библиотеке классов. Дополнительно в библиотеке классов java.applet определены
интерфейсы для подключения аплетов к содержащим их документам и классы для
проигрывания звуковых фрагментов.
Указатели,
которых нет.
Самая большая и шокирующая новость для тех, кто раньше
программировал на С, а теперь занялся изучением Java, это то, что в языке Java
нет указателей. Традиционно считалось, что работать с указателями трудно, а их
использование приводит к появлению трудно обнаруживаемых ошибок. Поэтому
разработчики Java решили отказаться от использования указателей совсем.
Спешим успокоить - вы сможете успешно составлять
приложения Java и без указателей, несмотря на то что вам, возможно, придется
немного изменить стиль программирования.
Вы можете спросить: как же передавать функциям ссылки
на объекты, если нет указателей?
Если вам нужно передать ссылку на переменную базового
типа, такого, например, как int или long, то ничего не получится - мы уже
говорили, что переменные базовых типов передаются по значению, а не по ссылке.
Поэтому нельзя напрямую создать на языке Java эквивалент следующей программы,
составленной на языке С:
// Некоторая переменная
int nSomeValue;
// Функция, изменяющая значение переменной,
// заданной своим адресом
void StoreValue(int *pVar, int nNewValue)
{ pVar->nNewValue;
}
. . .
StoreValue(&nSomeValue, 10);
Выход, однако, есть.
Язык Java позволяет использовать вместо указателей
ссылки на объекты. Пользуясь этими ссылками, вы можете адресовать объекты по их
имени, вызывая методы и изменяя значения данных объектов.
Что же касается данных базовых типов, если вам нужно
передавать на них ссылки, то следует заменить базовые типы на соответствующие
замещающие классы. Например, вместо типа int используйте класс Integer, вместо
типа long - класс Long и так далее.
Инициализация таких объектов должна выполняться с
помощью конструктора, как это показано ниже:
Integer nSomeValue;
nSomeValue = new Integer(10);
Первая строка создает неинициализированную ссылку с
именем nSomeValue и типом Integer. При попытке использования такой ссылки
возникнет исключение.
Вторая строка создает объект класса Integer, вызывая
конструктор. Этот конструктор определяет начальное значение. После выполнения
оператора присваивания ссылка nSomeValue будет ссылаться на реальный объект
класса Integer и ее можно будет использовать.
Имя объекта nSomeValue типа Integer вы можете
передавать функциям в качестве параметра, причем это будет ссылкой на объект.
Составляя программы на языке С, вы часто использовали
указатели для адресации элементов массивов, созданных статически или динамически
в оперативной памяти. Зная начальный адрес такого массива и тип хранящихся в
нем элементов, вы могли адресоваться к отдельным элементам массива.
В языке Java реализован механизм массивов, исключающих
необходимость использования указателей.
Для создания массива вы можете пользоваться
квадратными скобками, расположив их справа от имени массива или от типа
объектов, из которых составлен массив, например:
int nNumbers[];
int[] nAnotherNumbers;
Допустимы оба варианта, поэтому вы можете выбрать тот,
который вам больше нравится.
При определении массивов в языке Java нельзя указывать
их размер. Приведенные выше две строки не вызывают резервирования памяти для
массива. Здесь просто создаются ссылки на массивы, которые без инициализации
использовать нельзя.
Для того чтобы заказать память для массива, вы должны
создать соответствующие объекты с помощью ключевого слова new, например:
int[] nAnotherNumbers;
nAnotherNumbers = new int[15];
Как выполнить инициализацию ячеек таблицы?
Такую инициализацию можно выполнить либо статически,
либо динамически. В первом случае вы просто перечисляете значения в фигурных
скобках, как это показано ниже:
int[] nColorRed = {255, 255, 100, 0, 10};
Динамическая инициализация выполняется с использованием
индекса массива, например, в цикле:
int nInitialValue = 7;
int[] nAnotherNumbers;
nAnotherNumbers = new int[15];
for(int i = 0; i < 15; i++)
{ nAnotherNumbers[i] = nInitialValue;
}
Вы можете создавать массивы не только из переменных
базовых типов, но и из произвольных объектов. Каждый элемент такого массива
должен инициализироваться оператором new.
Массивы могут быть многомерными и, что интересно,
несимметричными.
Ниже создается массив массивов. В нулевом и первом
элементе создается массив из четырех чисел, а во втором - из восьми:
int[][] nDim = new int[5][10];
nDim[0] = new int [4];
nDim[1] = new int [4];
nDim[2] = new int [8];
Заметим, что во время выполнения приложения
виртуальная машина Java проверяет выход за границы массива. Если приложение
пытается выйти за границы массива, происходит исключение.
Массивы в языке Java являются объектами некоторого
встроенного класса. Для этого класса существует возможность определить размер
массива, обратившись к элементу данных класса с именем length, например:
int[] nAnotherNumbers;
nAnotherNumbers = new int[15];
for(int i = 0; i < nAnotherNumbers.length; i++)
{ nAnotherNumbers[i] = nInitialValue;
}
Для определения размера массива вам не нужен такой оператор,
как sizeof из языка программирования С, потому что существует другой способ
определения этого размера.
Базовым элементом объектно-ориентированного
программирования в языке Java является класс. В этой главе Вы научитесь
создавать и расширять свои собственные классы, работать с экземплярами этих
классов и начнете использовать мощь объектно-ориентированного подхода.
Напомним, что классы в Java не обязательно должны содержать метод main.
Единственное назначение этого метода — указать интерпретатору Java, откуда надо
начинать выполнение программы. Для того, чтобы создать класс, достаточно иметь
исходный файл, в котором будет присутствовать ключевое слово class, и вслед за
ним — допустимый идентификатор и пара фигурных скобок для его тела:
class Point {
}
Имя исходного файла Java должно соответствовать имени
хранящегося в нем класса. Регистр букв важен и в имени класса, и в имени файла.
Как вы помните, класс — это шаблон для создания
объекта. Класс определяет структуру объекта и его методы, образующие
функциональный интерфейс. В процессе выполнения Java-программы система
использует определения классов для создания представителей классов.
Представители являются реальными объектами. Термины «представитель»,
«экземпляр» и «объект» взаимозаменяемы. Ниже приведена общая форма определения
класса:
class имя_класса extends
имя_суперкласса { type переменная1_объекта:
type переменная2_объекта:
type переменнаяN_объекта:
type
имяметода1(список_параметров) { тело метода;
}
type имяметода2(список_параметров)
{ тело метода;
}
type имя
методаМ(список_параметров) { тело метода;
}
}
Ключевое слово extends указывает на то, что «имя_класса»
— это подкласс класса «имя_суперкласса». Во главе классовой иерархии
Java стоит единственный ее встроенный класс — Object. Если вы хотите создать
подкласс непосредственно этого класса, ключевое слово extends и следующее за
ним имя суперкласса можно опустить — транслятор включит их в ваше определение
автоматически. Примером может служить класс Point, приведенный ранее.
Переменные представителей (instance variables).
Данные инкапсулируются в класс путем объявления
переменных между открывающей и закрывающей фигурными скобками, выделяющими в
определении класса его тело. Эти переменные объявляются точно так же, как
объявлялись локальные переменные в предыдущих примерах. Единственное отличие
состоит в том, что их надо объявлять вне методов, в том числе вне метода main.
Ниже приведен фрагмент кода, в котором объявлен класс Point с двумя переменными
типа int.:
class Point { int х, у;
}
В качестве типа для переменных объектов можно
использовать как любой из простых типов, так и классовые типы. Скоро мы добавим
к приведенному выше классу метод main, чтобы его можно было запустить из командной
строки и создать несколько объектов.
Оператор new.
Оператор new создает экземпляр указанного класса и
возвращает ссылку на вновь созданный объект. Ниже приведен пример создания и
присваивание переменной р экземпляра класса Point:
Point р = new Point();
Вы можете создать несколько ссылок на один и тот же
объект. Приведенная ниже программа создает два различных объекта класса Point и
в каждый из них заносит свои собственные значения. Оператор точка используется
для доступа к переменным и методам объекта:
class TwoPoints {
public static void main(String args[]) {
Point p1 = new Point();
Point p2 = new Point();
p1.x = 10;
p1.y = 20;
р2.х = 42;
р2.у = 99;
System.out.println("x = " + p1.x + " у = " + p1.y);
System.out.println("x =
" + р2.х + " у = " + р2.у);
} }
В этом примере снова использовался класс Point, было
создано два объекта этого класса, и их переменным х и у присвоены различные
значения. Таким образом мы продемонстрировали, что переменные различных
объектов независимы на самом деле. Ниже приведен результат, полученный при
выполнении этой программы:
С:\> Java
TwoPoints
х = 10 у = 20
х = 42 у = 99
Поскольку при запуске интерпретатора мы указали в
командной строке не класс Point, а класс TwoPoints, метод main класса Point был
полностью проигнорирован. Добавим в класс Point метод main и, тем самым,
получим законченную программу:
class Point { int х, у;
public static void main(String args[]) {
Point p = new Point();
р.х = 10;
p.у = 20;
System.out.println("x = " + р.х + " у = " + p.y);
} }
Объявление методов.
Методы - это подпрограммы, присоединенные к конкретным
определениям классов. Они описываются внутри определения класса на том же уровне,
что и переменные объектов. При объявлении метода задаются тип возвращаемого им
результата и список параметров. Общая форма объявления метода такова:
тип имя_метода (список
формальных параметров) {
тело метода:
}
Тип результата, который должен возвращать метод может
быть любым, в том числе и типом void - в тех случаях, когда возвращать
результат не требуется. Список формальных параметров - это последовательность
пар тип-идентификатор, разделенных запятыми. Если у метода параметры отсутствуют,
то после имени метода должны стоять пустые круглые скобки:
class Point { int х, у;
void init(int a, int b) {
х = а;
У = b;
} }
В Java отсутствует возможность передачи параметров по
ссылке на примитивный тип. В Java
все параметры примитивных типов передаются по значению, а это означает,
что у метода нет доступа к исходной переменной, использованной в качестве
параметра. Заметим, что все объекты передаются по ссылке, можно изменять
содержимое того объекта, на который ссылается данная переменная.
Скрытие переменных представителей.
В языке Java не допускается использование в одной или
во вложенных областях видимости двух локальных переменных с одинаковыми
именами. Интересно отметить, что при этом не запрещается объявлять формальные параметры
методов, чьи имена совпадают с именами переменных представителей. Давайте
рассмотрим в качестве примера иную версию метода init, в которой формальным
параметрам даны имена х и у, а для доступа к одноименным переменным текущего
объекта используется ссылка this:
class Point { int х, у;
void init(int х, int у) {
this.x = х;
this.у = у } }
class TwoPointsInit {
public static void main(String args[]) {
Point p1 = new Point();
Point p2 = new Point();
p1.init(10,20);
p2.init(42,99);
System.out.println("x = " + p1.x + " у = •• + p-l.y);
System.out.printlnC'x = " + p2.x + " у = •• + p2.y);
} }
Конструкторы.
Инициализировать все переменные класса всякий раз,
когда создается его очередной представитель — довольно утомительное дело даже в
том случае, когда в классе имеются функции, подобные методу init. Для этого в
Java предусмотрены специальные методы, называемые конструкторами. Конструктор —
это метод класса, который инициализирует новый объект после его создания. Имя
конструктора всегда совпадает с именем класса, в котором он расположен
(также, как и в C++). У конструкторов нет типа возвращаемого результата -
никакого, даже void. Заменим метод init из предыдущего примера конструктором:
class Point { int х, у;
Point(int х, int у) {
this.x = х;
this.у = у;
} }
class PointCreate {
public static void main(String args[]) {
Point p = new Point(10,20);
System.out.println("x = " + p.x + " у = " + p.у);
} }
Программисты на Pascal (Delphi) для обозначения конструктора
используют ключевое слово constructor.
Совмещение методов.
Язык Java позволяет создавать несколько методов с
одинаковыми именами, но с разными списками параметров. Такая техника называется
совмещением методов (method overloading). В качестве примера приведена
версия класса Point, в которой совмещение методов использовано для определения
альтернативного конструктора, который инициализирует координаты х и у
значениями по умолчанию (-1):
class Point { int х, у;
Point(int х, int у) {
this.x = х;
this.у = у;
}
Point() {
х = -1;
у = -1;
} }
class PointCreateAlt {
public static void main(String args[]) {
Point p = new Point();
System.out.println("x = " + p.x + " у = " + p.y);
} }
В этом примере объект класса Point создается не при
вызове первого конструктора, как это было раньше, а с помощью второго
конструктора без параметров. Вот результат работы этой программы:
С:\> java PointCreateAlt
х = -1 у = -1
Решение о том, какой конструктор нужно вызвать в том
или ином случае, принимается в соответствии с количеством и типом параметров,
указанных в операторе new. Недопустимо объявлять в классе методы с одинаковыми
именами и сигнатурами. В сигнатуре метода не учитываются имена формальных
параметров учитываются лишь их типы и количество.
This в конструкторах.
Очередной вариант класса Point показывает, как,
используя this и совмещение методов, можно строить одни конструкторы на основе
других:
class Point { int х, у;
Point(int х, int у) {
this.x = х;
this.у = у;
}
Point() {
this(-1, -1);
} }
В этом примере второй конструктор для завершения
инициализации объекта обращается к первому конструктору.
Методы, использующие совмещение имен, не обязательно
должны быть конструкторами. В следующем примере в класс Point добавлены два
метода distance. Функция distance возвращает расстояние между двумя точками.
Одному из совмещенных методов в качестве параметров передаются координаты точки
х и у, другому же эта информация передается в виде параметра-объекта Point:
class Point { int х, у;
Point(int х, int у) {
this.x = х;
this. y = y;
}
double distance(int х, int у) {
int dx = this.x - х;
int dy = this.у - у;
return Math.sqrt(dx*dx + dy*dy);
}
double distance(Point p) {
return distance(p.x, p.y);
} }
class PointDist {
public static void main(String args[]) {
Point p1 = new Point(0, 0);
Point p2 = new Point(30, 40);
System.out.println("p1 = " + pi.x + ", " + p1.y);
System.out.println("p2 = " + p2.x + ", " + p2.y);
System.out.println("p1.distance(p2) = " + p1.distance(p2));
System.out.println("p1.distance(60, 80) = " + p1.distance(60,
80));
} }
Обратите внимание на то, как во второй фороме метода distance
для получения результата вызывается его первая форма. Ниже приведен результат
работы этой программы:
С:\> java PointDist
р1 = 0, 0
р2 = 30, 40
р1.distance(p2) = 50.0
p1.distance(60, 80) = 100.0
Наследование.
Вторым фундаментальным свойством объектно-ориентированного
подхода является наследование (первый – инкапсуляция). Классы-потомки имеют
возможность не только создавать свои собственные переменные и методы, но и наследовать переменные и методы
классов-предков. Классы-потомки принято называть подклассами. Непосредственного
предка данного класса называют его суперклассом. В очередном примере показано,
как расширить класс Point таким образом, чтобы включить в него третью
координату z:
class Point3D extends Point { int z;
Point3D(int x, int y, int z) {
this.x = x;
this.у = у;
this.z = z; }
Point3D() {
this(-1,-1,-1);
} }
В этом примере ключевое слово extends используется для
того, чтобы сообщить транслятору о намерении создать подкласс класса Point. Как
видите, в этом классе не понадобилось объявлять переменные х и у, поскольку
Point3D унаследовал их от своего суперкласса Point.
Вероятно, программисты, знакомые с C++, очевидно
ожидают, что сейчас мы начнем обсуждать концепцию множественного наследования.
Под множественным наследованием понимается создание класса, имеющего несколько
суперклассов. Однако в языке Java ради обеспечения высокой производительности и
большей ясности исходного кода множественное наследование реализовано не было.
В большинстве случаев, когда требуется множественное наследование, проблему
можно решить с помощью имеющегося в Java механизма интерфейсов.
Super.
В примере с классом Point3D частично повторялся код,
уже имевшийся в суперклассе. Вспомните, как во втором конструкторе мы
использовали this для вызова первого конструктора того же класса.
Аналогичным образом ключевое слово super позволяет обратиться
непосредственно к конструктору суперкласса (в Delphi / С++ для этого
используется ключевое слово inherited):
class Point3D extends Point { int z;
Point3D(int x, int у, int z) {
super(x, y); // Здесь мы вызываем конструктор
суперкласса this.z=z;
public static void main(String args[]) {
Point3D p = new Point3D(10, 20, 30);
System.out.println( " x = " + p.x + " y = " + p.y +
" z = " + p.z);
} }
Вот результат работы этой программы:
С:\> java Point3D
x = 10 у = 20 z = 30
Замещение методов.
Новый подкласс Point3D класса Point наследует реализацию
метода distance своего суперкласса (пример PointDist.java). Проблема
заключается в том, что в классе Point уже определена версия метода distance(mt
х, int у), которая возвращает обычное расстояние между точками на плоскости. Мы
должны заместить (override) это определение метода новым,
пригодным для случая трехмерного пространства. В следующем примере
проиллюстрировано и совмещение (overloading), и замещение
(overriding) метода distance:
class Point { int х, у;
Point(int х, int у) {
this.x = х;
this.у = у;
}
double distance(int х, int у) {
int dx = this.x - х;
int dy = this.у - у:
return Math,sqrt(dx*dx + dy*dy);
}
double distance(Point p) {
return distance(p.х, p.y);
}
}
class Point3D extends Point {
int z;
Point3D(int х, int y, int z) {
super(x, y);
this.z = z;
(
double distance(int х, int y, int z) {
int dx = this.x - х;
int dy = this.y - y;
int dz = this.z - z;
return Math.sqrt(dx*dx + dy*dy + dz*dz);
}
double distance(Point3D other) {
return distance(other.х, other.y, other.z);
}
double distance(int х, int y) {
double dx = (this.x / z) - х;
double dy = (this.у / z) - y;
return Math.sqrt(dx*dx + dy*dy);
}
}
class Point3DDist {
public static void main(String args[]) {
Point3D p1 = new Point3D(30, 40, 10);
Point3D p2 = new Point3D(0, 0, 0);
Point p = new Point(4, 6);
System.out.println("p1 = " + p1.x + ", " + p1.y +
", " + p1.z);
System.out.println("p2 = " + p2.x + ", " + p2.y +
", " + p2.z);
System.out.println("p = " + p.x + ", " + p.y);
System.out.println("p1.distance(p2) = " + p1.distance(p2));
System.out.println("p1.distance(4, 6) = " + p1.distance(4, 6));
System.out.println("p1.distance(p) = " + p1.distance(p));
} }
Ниже приводится результат работы этой программы:
С:\> Java Point3DDist
p1 = 30, 40, 10
р2 = 0, 0, 0
р = 4, 6
p1.distance(p2) = 50.9902
p1.distance(4, 6) = 2.23607
p1.distance(p) = 2.23607
Обратите внимание — мы получили ожидаемое расстояние
между трехмерными точками и между парой двумерных точек. В примере используется
механизм, который называется динамическим назначением методов (dynamic
method dispatch).
Динамическое назначение методов.
Давайте в качестве примера рассмотрим два класса, у
которых имеют простое родство подкласс / суперкласс, причем единственный метод
суперкласса замещен в подклассе:
class A { void callme() {
System.out.println("Inside A's callrne method");
class В extends A { void callme() {
System.out.println("Inside B's callme method");
} }
class Dispatch {
public static void main(String args[]) {
A a = new B();
a.callme();
} }
Обратите внимание — внутри метода main мы объявили
переменную а класса А, а проинициализировали ее ссылкой на объект класса В. В
следующей строке мы вызвали метод callme. При этом транслятор проверил наличие
метода callme у класса А, а исполняющая система, увидев, что на самом деле в
переменной хранится представитель класса В, вызвала не метод класса А, а callme
класса В. Ниже приведен результат работы этой программы:
С:\> Java Dispatch
Inside
B's calime method
Программистам Delphi / C++ следует отметить, что все
Java по умолчанию являются виртуальными функциями (ключевое слово virtual).
Рассмотренная форма динамического полиморфизма времени
выполнения представляет собой один из наиболее мощных механизмов
объектно-ориентированного программирования, позволяющих писать надежный,
многократно используемый код.
Final.
Все методы и переменные объектов могут быть замещены по
умолчанию. Если же вы хотите объявить, что подклассы не имеют права замещать
какие-либо переменные и методы вашего класса, вам нужно объявить их как final
(в Delphi / C++ не писать слово virtual):
final int FILE_NEW = 1;
По общепринятому соглашению при выборе имен переменных
типа final — используются только символы верхнего регистра (т.е. используются
как аналог препроцерных констант C++). Использование final-методов порой
приводит к выигрышу в скорости выполнения кода — поскольку они не могут быть замещены,
транслятору ничто не мешает заменять их вызовы встроенным (in-line)
кодом (байт-код копируется непосредственно в код вызывающего метода).
Finalize.
В Java существует возможность объявлять методы с
именем finalize. Методы
finalize аналогичны деструкторам в C++ (ключевой знак ~) и Delphi
(ключевое слово destructor). Исполняющая среда Java будет вызывать его
каждый раз, когда сборщик мусора соберется уничтожить объект этого класса.
Static.
Иногда требуется создать метод, который можно было бы
использовать вне контекста какого-либо объекта его класса. Так же, как в случае
main, все, что требуется для создания такого метода — указать при его
объявлении модификатор типа static. Статические методы могут
непосредственно обращаться только к другим статическим методам, в них ни в
каком виде не допускается использование ссылок this и super. Переменные также
могут иметь тип static, они подобны глобальным переменным, то есть доступны из
любого места кода. Внутри статических методов недопустимы ссылки на переменные
представителей. Ниже приведен пример класса, у которого есть статические
переменные, статический метод и статический блок инициализации:
class Static {
static int a = 3;
static int b;
static void method(int x) {
System.out.println("x = " + x);
System.out.println("a = " + a);
System.out.println("b = " + b);
}
static {
System.out.println("static block initialized");
b = a * 4;
}
public static void main(String args[]) {
method(42);
} }
Ниже приведен результат запуска этой программы:
С:\> java Static static block initialized
Х = 42
А = 3
B = 12
В следующем примере мы создали класс со статическим
методом и несколькими статическими переменными. Второй класс может вызывать
статический метод по имени и ссылаться на статические переменные
непосредственно через имя класса:
class StaticClass {
static int a = 42;
static int b = 99;
static void callme() {
System.out.println("a = " + a);
} }
class StaticByName {
public static void main(String args[]) {
StaticClass.callme();
System.out.println("b = " + StaticClass.b);
} }
А вот и результат запуска этой программы:
С:\> Java StaticByName
а = 42 b = 99
Abstract.
Бывают ситуации, когда нужно определить класс, в котором
задана структура какой-либо абстракции, но полная реализация всех методов
отсутствует. В таких случаях вы можете с помощью модификатора типа abstract
объявить, что некоторые из методов обязательно должны быть замещены в
подклассах. Любой класс, содержащий методы abstract, также должен быть
объявлен, как abstract. Поскольку у таких классов отсутствует полная
реализация, их представителей нельзя создавать с помощью оператора new. Кроме
того, нельзя объявлять абстрактными конструкторы и статические методы. Любой
подкласс абстрактного класса либо обязан предоставить реализацию всех
абстрактных методов своего суперкласса, либо сам должен быть объявлен
абстрактным:
abstract class A {
abstract void callme();
void metoo() {
System.out.println("Inside A's metoo method");
} }
class B extends A {
void callme() {
System.out.println("Inside B's callme method");
} }
class Abstract {
public static void main(String args[]) {
A a = new B():
a.callme():
a.metoo():
} }
В нашем примере для вызова реализованного в подклассе
класса А метода callme и реализованного в классе А метода metoo используется
динамическое назначение методов, которое мы обсуждали раньше:
С:\> Java Abstract
Inside
B's callrne method Inside A's metoo method
Оба языка реализуют принципиально одинаковую модель
работы с динамическими данными: объекты создаются динамически с помощью
конструкции new, среда
исполнения отслеживает наличие ссылок на них, а сборщик мусора периодически
очищает память от объектов, ссылок на которые нет. Для оптимизации сборки
мусора спецификации языков и сред исполнения не содержат ограничений на время
жизни объекта после удаления последней ссылки на него — сборщик работает
независимо от исполнения программы, поэтому реальное уничтожение объекта может
произойти в любой момент после удаления последней ссылки до завершения работы
программы. В реальности сборщики мусора оптимизируют исполнение так, чтобы
обеспечить приемлемый расход памяти при минимальном замедлении работы программ.
И в Java, и в C# есть
сильные и слабые ссылки на объекты. Оба языка
поддерживают методы-финализаторы. Из-за неопределённости
момента удаления объекта финализаторы не могут использоваться для освобождения
системных ресурсов, занятых объектом, что вынуждает создавать дополнительные
методы для «очистки» объекта и вызывать их явно.
C# содержит в стандартной
библиотеке интерфейс IDisposable и
специальную конструкцию using,
гарантирующую своевременный вызов метода очистки:
// DisposableClass реализует интерфейс IDisposable и описывает его метод Dispose
class DisposableClass : IDisposable
{ public void Dispose()
{ // ... Здесь освобождаются занятые экземпляром ресурсы
}
}
using (DisposableClass obj = new DisposableClass(...))
{ ... Код, использующий объект obj
}
... Здесь для объекта obj гарантированно уже вызван метод Dispose
В Java подобной конструкции
нет и очистка объектов может быть выполнена только вручную:
class AnyClass { void clear() { // ... Здесь находится код очистки
}
}
AnyClass obj = new AnyClass(...);
try { ... код, использующий объект obj
}
finally { obj.clear(); // - явный вызов метода очистки объекта по завершении его использования
}
Java позволяет
зарегистрировать слушателя (listener), который будет получать сообщения, когда
ссылка подвергается сборке мусора, что даёт улучшение производительности WeakHashMap.
C# (точнее, среда CLR)
позволяет отменить выполнение финализатора для данного объекта методом GC.SuppressFinalize(obj)
(напр., соединение SQL
на файловом потоке). Это бывает полезным, поскольку финализация считается относительно дорогой
операцией при сборке мусора, и объект с финализатором «живёт» дольше.
Оба языка — объектно-ориентированные,
с синтаксисом, унаследованным от C++, но значительно переработанным. Код и
данные могут описываться только внутри классов.
Инкапсуляция.
В Java модификатор protected
в описании, помимо доступа из классов-потомков, разрешает доступ из всех
классов, входящих в тот же пакет, что и класс-владелец.
В C# для объектов, которые
должны быть видны в пределах сборки (примерный аналог пакета Java) введён
отдельный модификатор internal, а protected сохраняет свой изначальный смысл,
взятый из C++ — доступ только из классов-потомков. Допускается комбинировать
internal и protected — тогда получится область доступа, соответствующая
protected в Java.
Внутренние классы.
Оба языка позволяют
определить класс внутри класса. Внутренние классы Java имеют доступ к
нестатическим членам родительского класса, то есть «знают о this»; кроме того,
внутри методов можно определять локальные классы, имеющие доступ по чтению к
локальным переменным, и безымянные (анонимные) локальные классы, которые
фактически позволяют создавать экземпляры объектов и интерфейсов, перекрывающие
методы своего класса. На этом механизме в Java-программах может строиться
обработка событий.
Подход C# более напоминает
C++. Внутренние классы в C# имеют доступ только к статическим членам внешнего
класса, а для доступа к нестатическим членам нужно явно указывать экземпляр
внешнего класса. Локальные внутренние классы в C# не поддерживаются, обработка
событий в нём не требует таких классов, поскольку строится на других
механизмах.
Методы.
В обоих языках методы, по
аналогии с C++ — функции, определённые в классе. Тело метода располагается
внутри описания класса. Поддерживаются статические методы, абстрактные методы.
В C# также есть явная реализация методов интерфейса, что позволяет классу
реализовывать методы интерфейса отдельно от собственных методов или давать
разные реализации одноимённых методов, принадлежащих двум разным интерфейсам.
В C# примитивные типы (byte, int, double, float,
bool и пр.) и структуры (struct) передаются по значению (т. н. значимые типы),
остальные типы передаются по ссылке (т. н. ссылочные типы). C# также
поддерживает явное описание передачи параметров по ссылке (ключевые слова ref и
out). При использовании out компилятор контролирует наличие в методе
присваивания значения. В Java параметры метода передаются только по значению,
но поскольку для экземпляров классов передаётся ссылка, ничто не мешает изменить
в методе экземпляр, переданный через параметр.
Виртуальность методов.
C# копирует концепцию виртуальных методов C++: виртуальный метод
должен быть явно объявлен с ключевым словом virtual,
прочие методы виртуальными не являются. C# требует явного объявления о
перекрытии виртуального метода в производном классе ключевым словом override.
Если требуется «заслонить» (shadowing) виртуальный метод, то есть просто ввести
новый метод с тем же именем и сигнатурой, требуется указать ключевое слово new
(в случае отсутствия которого компилятор выдаёт предупреждение). Запрещается
заслонять абстрактные методы. Объявление метода с ключевым словом sealed
запрещает создавать в классах-потомках новые методы с той же сигнатурой.
В Java, наоборот, все
открытые методы, кроме статических, являются виртуальными, а переопределить
метод так, чтобы механизм виртуальности не включился, невозможно. Метод всегда
виртуально перекрывает метод базового класса с теми же именем и сигнатурой,
если он есть. Ключевое слово final
позволяет запретить создание метода с такой же сигнатурой в производных
классах.
Подход Java синтаксически
проще, он гарантирует, что всегда вызывается метод именно того класса, к
которому относится объект. С другой стороны, виртуальность действительно нужна
не всегда, а накладные расходы на вызов виртуальных методов несколько больше, поскольку
эти вызовы обычно не проходят инлайн-подстановку и требуют дополнительного
обращения к таблице виртуальных методов (хотя
некоторые реализации JVM, включая реализацию Sun, реализуют инлайн-подстановку
наиболее часто вызываемых виртуальных методов).
Виртуальность всех методов
потенциально небезопасна: если программист по ошибке объявит метод, который уже
есть в базовом классе, не имея намерения его перекрывать, а просто не обратив
внимания на то, что такой метод уже есть, то новый метод перекроет одноимённый
метод в базовом классе, хотя это и не входит в намерения разработчика. В C#
подобная ошибка тоже возможна, но компилятор выдаст предупреждение, что
перекрывающий метод объявлен без new
и override. В Java 5
появился аналогичный механизм — если метод перекрывает виртуальный метод
класса-предка, компилятор выдаёт предупреждение; чтобы предупреждение не
выдавалось, необходимо отметить перекрывающий метод аннотацией «@override».
Оба языка поддерживают идею примитивных типов (которые в C# являются
подмножеством типов-значений — value types), и оба для трансляции
примитивных типов в объектные обеспечивают их автоматическое «заворачивание» в
объекты (boxing) и «разворачивание» (unboxing) (в Java — начиная с версии 1.5).
У C# имеется больше примитивных типов, чем у Java, за счёт беззнаковых целых
типов (unsigned), имеющихся парно ко всем знаковым, и специального типа decimal
для высокоточных вычислений с фиксированной запятой (в Java для этого служат
классы java.math.BigInteger и java.math.BigDecimal).
В Java отказались от
большинства беззнаковых типов ради упрощения языка. Одна из известных проблем с
такими типами — сложность определения типа результата арифметических операций
над двумя аргументами, один из которых является знаковым, другой — беззнаковым.
Независимо от того, какие правила в отношении подобных операций примет язык, в
некоторых ситуациях это приведёт к ошибкам (например, в C++ операция над
знаковым и беззнаковым значением даёт беззнаковый результат; в итоге на
16-разрядных архитектурах выражение «40000 / (-4)» даст в результате не −10000,
а 55536).
Структуры (записи).
C# позволяет создавать
пользовательские типы-значения, используя ключевое слово struct.
Это прямое наследие языка С++ от которого создатели Java сознательно
отказались. В отличие от экземпляров классов, экземпляры типов-значений
создаются не в куче, а на стеке вызовов или в составе экземпляра объекта,
в котором они объявлены, что в некоторых случаях повышает производительность
кода. С точки зрения программиста они подобны классам, но с несколькими
ограничениями: у них не может быть явного конструктора без параметров (но может
быть конструктор с параметрами), от них нельзя наследовать и они не могут явно
наследоваться от других типов (всегда неявно наследуются от класса
System.ValueType), но могут реализовывать интерфейсы. Кроме того, значения
struct-типов поддерживают логику присваивания значения (то есть переменная
этого типа содержит не ссылку, а само значение, и присваивание одной переменной
значения другой приводит не к копированию ссылки на один и тот же объект, а к
копированию значений полей одной структуры в другую). Начиная с версии 1.6, в
Java тоже имеется возможность создавать объекты на стеке, но происходит это
автоматически без участия пользователя. В Java для того чтобы от класса нельзя
было наследоваться его можно объявить финальным final,
тем самым получив частичный аналог конструкции struct
(копирование по значению при этом поддерживаться не будет всё равно).
Перечислимые типы.
Перечислимые типы в C# происходят от
примитивных целочисленных типов. Допустимым значением перечислимого типа
является любое значение лежащего в его основе примитивного, хотя для его
присваивания может потребоваться явное приведение типа. Это позволяет комбинировать
значения перечислимого типа побитовой операцией «или», если они являются
битовыми флагами.
В Java перечислимые типы
являются классами, их значения, соответственно — объектами. Тип-перечисление может
иметь методы, реализовывать интерфейсы. Единственные допустимые значения типа —
те, что перечислены в объявлении. Для комбинации их вместе как флагов требуется
специальный объект набора перечислений. Возможно задавать разные реализации
методов для каждого значения.
Массивы и коллекции.
Массивы и коллекции тоже получили выражение в
синтаксисе обоих языков, благодаря особой разновидности цикла for
(цикл по коллекции, известный также как цикл foreach).
В обоих языках массив является объектом класса Array,
но в Java он не реализует какие-либо интерфейсы коллекций, хотя по массивам
возможна итерация циклом for(:). Оба языка имеют в стандартной библиотеке
классы типичных коллекций.
В Java могут быть объявлены,
строго говоря, только одномерные массивы. Многомерный массив в Java — массив
массивов. В C# есть как настоящие многомерные массивы, так и массивы массивов, которые в C# обычно
называются «неровными», или «ступенчатыми» (jagged). Многомерные массивы всегда
«прямоугольные» (говоря в двумерной терминологии), в то время как массивы
массивов могут хранить строки разной длины (опять-таки в двумерном случае, в
многомерном аналогично). Многомерные массивы ускоряют доступ к памяти (для них
указатель разыменовывается только один раз), а неровные массивы работают
медленнее, но экономят память, когда не все строки заполнены. Многомерные
массивы требуют для своего создания лишь один вызов оператора new,
а ступенчатые требуют явно выделять память в цикле для каждой строки.
Параметризованные (обобщённые) типы.
В обоих языках типы могут
быть параметризованными, что поддерживает парадигму обобщённого программирования.
Синтаксически определение типов достаточно близко — в обоих языках оно
унаследовано от шаблонов C++, хотя и с некоторыми модификациями.
Шаблоны Java являются чисто
языковой конструкцией и реализованы лишь в компиляторе. Компилятор заменяет все
обобщённые типы на их верхние границы и вставляет соответствующее приведение
типов в те места, где используется шаблон. В результате получается байт-код,
который не содержит ссылок на обобщённые типы и их параметры. Такая техника
реализации обобщённых типов называется затиранием типов (type erasure).
Это означает, что информация об исходных обобщённых типах во время выполнения
недоступна, и обусловливает некоторые ограничения, такие как невозможность
создавать новые экземпляры массивов из аргументов обобщённого типа. Среда
выполнения Java не знакома с системой обобщённых типов, вследствие чего новым
реализациям JVM понадобились лишь минимальные обновления для работы с новым
форматом классов.
C# пошёл другим путём.
Поддержка обобщённости была интегрирована в саму виртуальную среду выполнения,
впервые появившись в .NET 2.0. Язык здесь стал лишь внешним интерфейсом для
доступа к этим возможностям среды. Как и в Java, компилятор производит
статическую проверку типов, но в дополнение к этому JIT производит проверку
корректности во время загрузки. Информация об обобщённых типах
полностью присутствует во время выполнения и позволяет полную поддержку рефлексии обобщённых типов и создание их
новых реализаций.
Подход Java требует
дополнительных проверок во время выполнения, не гарантирует, что клиент кода
будет следовать соответствию типов, и не обеспечивает рефлексии для обобщённых
типов. Java не позволяет специализировать обобщённые типы примитивными (это
можно сделать только заворачивая примитивные типы в классы), в то время как C#
обеспечивает обобщение как для ссылочных типов, так и для типов-значений,
включая примитивные. Вместо этого Java предлагает использование завёрнутых
примитивных типов в качестве параметров (напр., List<Integer>
вместо List<int>), но это
даётся ценой дополнительного выделения динамической памяти. Как в Java, так и в
C# специализации обобщённого типа на разных ссылочных типах дают одинаковый код
[2], но для C# среда выполнения динамически генерирует
оптимизированный код при специализации на типах-значениях (например, List<int>),
что позволяет их хранить и извлекать из контейнеров без операций за- и разворачивания.
· Java поддерживает импорт статических имён (import
static) из классов, позволяющий отдельно импортировать некоторые
или все статические методы и переменные класса и использовать их имена без
квалификации в импортирующем модуле. В C# импортируется только сборка и при
каждом использовании импортируемых статических имён требуется указывать класс.
· В Java константы в операторы switch должны относиться
либо к целочисленному, либо к перечислимому типу. В C# в switch можно
использовать текстовые строки.
· Java содержит конструкцию strictfp, гарантирующую
одинаковые результаты операций с плавающей точкой на всех платформах.
· C# содержит конструкции checked
и unchecked, позволяющие локально включать и выключать
динамическую проверку арифметического переполнения.
· C# поддерживает оператор перехода goto. Обычное
использование — передача управления на разные метки case
в операторе switch и выход из
вложенного цикла. В Java от использования goto сознательно отказались.
· Java поддерживает метки в циклах и позволяет
использовать их в командах break и continue, благодаря чему исключается такой
повод использования goto, как выход из вложенного цикла.
· C# поддерживает отдельное понятие именованной
типизированной константы и ключевое слово const.
В Java констант как таковых нет, вместо них используются статические переменные
класса с модификатором final — эффект от
их использования точно такой же.
Java требует от программиста
ручной реализации шаблона наблюдателя, хоть и обеспечивает
некоторый синтаксический сахар в виде анонимных вложенных классов, что позволяет определить
тело класса и тут же создать его экземпляр в одной точке кода. Эта возможность
обычно используется для создания наблюдателей.
C# предоставляет обширную
поддержку событийного программирования на уровне языка, включая делегаты .NET,
мультикастинг, специальный синтаксис для задания событий в классах, операции
для регистрации и разрегистрации обработчиков события, ковариантность делегатов и
анонимные методы с полным набором семантики замыкания.
Замыкания предлагаются к
включению в Java SE 7. Эти замыкания, как делегаты в C#, имели бы полный доступ
ко всем локальным переменным в данной области видимости, а не только доступ для
чтения к переменным, помеченным словом final
(как с анонимными вложенными классами).
C# включает перегрузку операций и задаваемое пользователем приведение типов, знакомые программирующим на
C++. C# её поддерживает с некоторыми ограничениями, обеспечивающими логическую
целостность, что при осторожном использовании помогает сделать код более
лаконичным и читаемым.
Java не включает перегрузку операций
во избежание злоупотреблений ею и для поддержания простоты языка.
C# поддерживает концепцию
«свойств» — псевдополей класса, к которым обеспечивается полностью
контролируемый доступ путём создания методов для извлечения и записи значения
поля. Описания свойств производятся с помощью конструкций get
и set.
C# также включает так
называемые индексаторы, которые можно считать особым случаем перегрузки
операций (аналогичным перегрузке operator[]
в C++), или параметризованными свойствами. Индексатор — это свойство с именем this[],
которое может иметь один или более параметров (индексов), причём индексы могут
быть любого типа. Это позволяет создавать классы, экземпляры которых ведут себя
подобно массивам:
myList[4] = 5;
string name = xmlNode.Attributes["name"];
orders = customerMap[theCustomer];
Использование свойств не
одобряется некоторыми авторитетными программистамми. В частности, Джеффри Рихтер
пишет:
«Лично мне свойства не
нравятся, и я был бы рад, если бы их поддержку убрали из Microsoft .NET
Framework и сопутствующих языков программирования. Причина в том, что свойства выглядят
как поля, на самом деле являясь методами».
Согласно общепринятому в C#
стилю именования, имена свойств визуально отличаются от полей тем, что
начинаются с прописной буквы.
C#, в отличие от Java, поддерживает
условную компиляцию с использованием директив препроцессора. В нём также есть атрибут Conditional,
означающий, что указанный метод вызывается только тогда, когда определена
данная константа компиляции. Таким путём можно вставлять в код, например,
проверки допущений (assertion checks), которые будут работать только в
отладочной версии, когда определена константа DEBUG.
В стандартной библиотеке .NET таков метод Debug.Assert().
Java версий 1.4 и выше
включает в язык возможность проверки допущений, включаемую во время выполнения.
Кроме того, конструкции if с константными условиями могут разворачиваться на
этапе компиляции.
C# использует пространства
имён (namespace), напоминающие одноимённый механизм C++. Каждый класс
относится к некоторому пространству имён, те классы, для которых пространство
имён не указано явно, относятся к безымянному пространству имён по умолчанию.
Пространства имён могут быть вложенными друг в друга.
В Java имеются пакеты,
отчасти похожие на пространства имён C#. Пакеты могут быть вложенными, каждый
описываемый класс относится к некоторому пакету, при отсутствии явного указания
пакета класс относится к глобальному безымянному пакету.
В обоих языках для обращения
к объекту, объявленному в другом пространстве имён или пакете, нужно объявить в
программе требуемый пакет (пространство имён) как используемый. Обращение к
объекту производится через квалифицированное имя, в качестве квалификатора
используется имя пакета (пространства имён). Если требуется обращение к объекту
без квалификации, программный модуль должен содержать директиву разыменования:
using в C# и import в Java.
В C# пространства имён никак
не связаны с компилированными модулями (сборками, или assembly в терминологии
Microsoft). Несколько сборок могут содержать одно и то же пространство имён, в
одной сборке может объявляться несколько пространств имён, не обязательно
вложенных. Модификаторы области видимости C# никак не связаны с пространствами
имён. В Java объявленные в одном пакете классы по умолчанию образуют единый
компилированный модуль. Модификатор области видимости protected ограничивает
область видимости полей и методов класса пределами пакета.
В Java структура файлов и
каталогов исходных текстов пакета по умолчанию связана со структурой пакета —
пакету соответствует каталог, входящим в него подпакетам — подкаталоги этого
каталога, файлы исходных текстов располагаются в каталогах, соответствующих
пакету или подпакету, в который они входят. Таким образом, дерево исходных
текстов повторяет структуру пакета. В C# местонахождение файла с исходным
текстом никак не связано с его пространством имён.
В C# классы могут
располагаться в файлах произвольным образом. Имя файла исходного кода никак не
связано с именами определяемых в нём классов. Допускается расположить в одном
файле несколько общедоступных (public) классов. Начиная с версии 2.0, C#
позволяет также разбить класс на два и более файла (ключевое слово partial).
Последняя особенность активно используется визуальными средствами построения
интерфейса: часть класса, в которой находятся поля и методы, управляемые
конструктором интерфейса, выделяются в отдельный файл, чтобы не загромождать
автоматически генерируемым кодом файл, непосредственно редактируемый
программистом.
В Java каждый файл может
содержать только один общедоступный (public) класс, причём Java требует, чтобы
имя файла совпадало с именем этого класса, что исключает путаницу в именах
файлов и классов. Более того, согласно рекомендуемому Sun соглашению об
оформлении кода, размер файла исходного кода не должен превышать 2000 строк кода, поскольку в файле большего
размера труднее разбираться. Большой размер файла также считается признаком
плохого проектного решения.
Оба языка поддерживают
механизм обработки исключений, синтаксически оформленный совершенно одинаково:
в языке имеется оператор генерации исключения throw
и блок обработки исключений try{}catch(){}finally{},
обеспечивающий перехват возникших внутри блока исключений, их обработку, а
также гарантированное выполнение завершающих действий.
Java поддерживает
проверяемые (checked) исключения: программист должен явно
указать для каждого метода типы исключений, которые метод может выбросить, эти
типы перечисляют в объявлении метода после ключевого слова throws.
Если метод использует методы, выбрасывающие проверяемые исключения, он должен
либо явно перехватывать все эти исключения, либо содержать их в собственном
описании. Таким образом, код явно содержит перечень исключений, которые могут
быть выброшены каждым методом. Иерархия типов исключений содержит также два
типа (RuntimeException и Error),
наследники которых не являются проверяемыми и не должны описываться. Они
выделены для исключений времени выполнения, которые могут возникнуть в любом
месте, либо обычно не могут быть обработаны программистом (например, ошибки
среды исполнения), и не должны указываться в объявлении throws.
C# проверяемые исключения не
поддерживает. Их отсутствие является сознательным выбором разработчиков. Андерс Хейлсберг, главный архитектор C#,
считает, что в Java они были в какой-то степени экспериментом и себя не
оправдали [2] [3].
Вопрос о пользе проверяемых
исключений дискуссионный. Подробнее см. статью Обработка исключений.
Java Native Interface (JNI) позволяет
программам вызывать из Java низкоуровневые, системно-зависимые функции
(например, библиотек winAPI). Как правило, JNI используется при написании
драйверов. При написании JNI-библиотек разработчик должен использовать
специальный API, предоставляемый бесплатно. Выпускаются также
специализированные библиотеки для взаимодействия Java с COM. В своё время MS
ввела поддержку COM-объектов в Java на уровне языка в своей JVM, что послужило причиной
отзыва Sun Microsystems лицензии на выпуск JVM у MS.
Технология Platform Invoke
(P/Invoke), реализованная в .NET, позволяет вызывать из C# внешний код, который
Microsoft называет неуправляемым. Через атрибуты в метаданных
программист может точно управлять передачей (маршалингом) параметров и результатов, избегая, таким образом,
необходимости дополнительного кода адаптации. P/Invoke предоставляет почти
полный доступ к процедурным API (таким, как Win32 или POSIX), но не даёт прямого
доступа к библиотекам классов C++.
.NET Framework предоставляет
также мост между .NET и COM,
позволяя обращаться к COM-компонентам так, как если бы они были родными
объектами .NET, что требует дополнительных усилий программиста при
использовании COM-компонент со сложными нетривиальными интерфейсами (например,
в случае передачи структуры через массив байтов). В этих случаях приходится
прибегать к unsafe коду (см. ниже) или другим обходным путям.
C# разрешает ограниченное
использование указателей, которые проектировщики языков
зачастую считают опасными. Подход C# в этом деле — требование ключевого слова unsafe
при блоках кода или методах, использующих эту возможность. Это ключевое слово
предупреждает пользователей такого кода о его потенциальной опасности. Оно
также требует явного задания компилятору опции /unsafe, которая по умолчанию
выключена. Такой «небезопасный» код используется для улучшения взаимодействия с
неуправляемым API и иногда для повышения эффективности определённых участков
кода.
C# также позволяет
программисту отключить нормальную проверку типов и другие возможности
безопасности CLR, разрешая использование переменных-указателей при условии
применения ключевого слова unsafe.
JNI, P/Invoke и unsafe-код одинаково
рискованны, чреваты дырами в безопасности системы и нестабильностью
приложения. Преимуществом управляемого unsafe-кода над P/Invoke или JNI
является то, что он позволяет программисту продолжать работать в знакомой среде
C# для выполнения задач, которые при других методах потребовали бы вызова
неуправляемого кода, написанного на другом языке.
Существуют многочисленные
реализации JVM
практически для всех присутствующих на рынке платформ. Разработкой JVM
занимаются такие корпорации, как IBM, Sun Microsystems, Bea и ряд других.
Следует отметить, что Sun выпускает свою JVM как под своей собственной
лицензией, так и под модифицированной (посредством т. н. «Classpath exception»)
лицензией GPLv2.
Java Web
Start и апплеты обеспечивают удобное, лёгкое и безопасное средство
распространения настольных приложений, причём эффективность её байткодового представления вкупе с агрессивными технологиями
сжатия, такими как pack200, делают Java
средством распространения сетевых приложений, неприхотливым к полосе
пропускания.
C# тоже является
кроссплатформенным стандартом. Его первичная платформа — Windows,
но существуют и реализации для других платформ, самая значительная из которых —
проект Mono.
Однако платформы, отличные от Windows не поддерживаются официальным производителем, и на
сегодняшний день далеки от совершенства.
Технология ClickOnce предлагает функциональность,
подобную Java Web Start, но она имеется только для клиентов Windows. Internet
Explorer на Windows умеет показывать элементы интерфейса .NET Windows Forms, что
даёт апплетоподобную функциональность, но ограничено конкретным браузером.
Развитие этих двух языков, и
также их API, двоичных форматов и сред выполнения управляется по-разному.
C# определён стандартами ECMA и ISO, которые задают синтаксис
языка, формат выполнимых модулей (известный как CLI) и библиотеку базовых
классов (Base Class Library, или BCL). Стандарты не включают многие новые
библиотеки, реализованные Microsoft поверх стандартного каркаса, такие как
библиотеки для баз данных, GUI и веб-приложений (Windows Forms,
ASP.NET
и ADO.NET).
Однако Microsoft формально согласилось не преследовать в судебном порядке
проекты сообщества за реализацию этих библиотек.
На сегодняшний день никакая
составная часть среды Java не стандартизуется Ecma, ISO, ANSI
или какой-либо другой сторонней организацией стандартов. В то время как Sun
Microsystems сохраняет неограниченные исключительные юридические
права на модификацию и лицензирование своих торговых марок Java, исходного
текста и других материалов, Sun добровольно участвует в процессе, называемом Java Community Process (JCP), который
позволяет заинтересованным сторонам предлагать изменения в любые Java-технологии
Sun (язык, инструментарий, API) через консультации и экспертные группы. По
правилам JCP, любое предложение по изменению в JDK, среде выполнения Java
или спецификации языка Java может быть односторонне отвергнуто Sun, потому что
для его одобрения требуется голос «за» со стороны Sun. От коммерческих
участников JCP требует членских взносов, в то время как некоммерческие
организации и частные лица могут участвовать в нём бесплатно.
В то время как «Java» —
торговая марка Sun trademark, и только Sun может лицензировать имя «Java»,
существуют многочисленные свободные проекты, частично совместимые с Sun Java.
Например, GNU Classpath и GNU Compiler for Java (GCJ) поставляют свободную библиотеку
классов и компилятор, частично совместимые с текущей версией Sun Java[5]. В конце 2006 года Sun объявила, что весь исходный
код Java, за исключением закрытого кода, на который они не сохраняют права,
будет выпущен к марту 2007 года в качестве свободного программного обеспечения
под видоизменённой лицензией GPL. Sun в настоящее время распространяет свою HotSpot Virtual
Machine и компилятор Java под лицензией GPL, но на стандартную среду выполнения
Java сейчас нет свободной лицензии. Поскольку Sun сохранит право собственности
на свой исходный код Java, выпуск под лицензией GPL не запретит Sun
распространять несвободные или неоткрытые версии Java, или давать на это
лицензии другим.
C#, среда выполнения CLI и
большая часть соответствующей библиотеки классов стандартизированы и могут
свободно реализовываться без лицензии. Уже реализовано несколько свободных
систем C#, в том числе Mono
и DotGNU.
В проекте Mono также реализованы многие нестандартные библиотеки Microsoft
путём изучения материалов Microsoft, аналогично GNU Classpath и Java. Целью
проекта Mono является избежать посягательств на какие-либо патенты или
копирайты, и проект может свободно распространяться и использоваться под
лицензией GPL. Microsoft в настоящее время распространяет Shared source-версию
своей среды выполнения .NET для некоммерческого использования.
Java построена на более открытой культуре с высокой
конкурентностью фирм в различных областях функциональности. Большинство
дополнительных библиотек доступно под свободными лицензиями с открытым исходным
кодом. Также Sun приветствует практику описания какой-либо функциональности в
виде спецификации (см. процесс JCP), оставляя реализацию сторонним
разработчикам (возможно, предоставляя эталонную реализацию). Таким образом,
решается вопрос независимости от производителя ПО.
Несмотря на существование Mono, C# тесно привязывает
разработчиков к платформе MS (включая ОС, БД, офисные решения). Таким образом,
пользователь программного обеспечения, написанного на .NET, часто не имеет
выбора в использовании различных компонент системы. Это приводит к так
называемому vendor-locking, при котором производитель стороннего ПО может
диктовать покупателю практически любые условия на поддержку внедренного
проекта. В то время, как пользователь приложения Java, как правило, может сам
выбрать поставщика дополнительного ПО (такого, как БД, ОС, сервера приложений и
т. д.).
Подход C# более прагматичен.
В дополнение ко вложенным уровням абстракции часто поставляются простые
вспомогательные классы; в некоторых случаях уровни абстракции вообще не
делаются.
Java старше, чем C# и
построена на большой и активной пользовательской базе, став lingua franca
во многих современных областях информатики, особенно таких, где задействованы сети. Java доминирует в курсах программирования
американских университетов и колледжей, и литературы по Java сегодня намного
больше, чем по C#. Зрелость и популярность Java привели к большему числу
библиотек и API на Java (многие из которых открытые), чем на C#.
В отличие от Java, C# — язык
относительно новый. Microsoft изучила существующие языки, такие как Java и Дельфи, и изменила некоторые
аспекты языка для лучшего соответствия нуждам некоторых типов приложений.
В отношении Java можно
услышать критику, что она медленно развивается, в ней не хватает некоторых
возможностей, которые облегчают модные шаблоны программирования и методологии.
Язык C# критикуют в том, что его разработчики, возможно, слишком спешат угодить
сиюминутным течениям в программировании за счёт фокусировки и простоты языка.
Очевидно, проектировщики Java заняли более консервативную позицию по добавлению
крупных новых возможностей в синтаксис языка, чем в других современных языках —
возможно, не желая привязать язык к течениям, которые в долгосрочной
перспективе могут завести в тупик. С выпуском Java 5.0 эта тенденция во многом
была нарушена, так как в ней ввели несколько крупных новых возможностей языка:
цикл типа foreach, автоматическое
заворачивание, методы с переменным числом параметров, перечислимые типы,
обобщённые типы и аннотации (все они присутствуют и в C#).
C#, в свою очередь, развивается
быстрее, гораздо слабее ограничивая себя в добавлении новых
проблемно-ориентированных возможностей. Особенно эта тенденция проявилась в
готовящейся к выпуску версии C# 3.0, в которой, например, появились SQL-подобные запросы.
Проблемно-ориентированные дополнения к Java рассматривались, но, по крайней
мере на сегодняшний день, были отвергнуты.
С момента появления C# он
постоянно сравнивается с Java. Невозможно отрицать, что C# и его управляемая
среда CLR многим обязаны Java и её JRE (Java Runtime Environment). Однако C# также приспособлен и
к конструкциям, чаще существующим в языках типа C++, Дельфи (который
спроектировал тот же Андерс Хейлсберг) и, в последних версиях C#,
кое-что позаимствовал также из таких динамических скриптовых языков, как Руби.
Можно спорить, является ли
разработка C# в какой-то степени результатом признания Майкрософтом того, что
среда управляемого кода, где лидирует Java, имеет множество достоинств в
растущем сетевом мире, особенно при появлении интернета на устройствах,
отличных от персональных компьютеров, и при растущей важности сетевой
безопасности. До создания C# Microsoft модифицировала Java(создав J++),
с тем, чтобы добавить возможности, работающие только на ОС Windows,
нарушив, таким образом, лицензионное соглашение Sun
Microsystems. Пока Microsoft находилась на второй фазе своей
бизнес-стратегии, известной как «Embrace, Extend, and Extinguish»,
развитие J++ было остановлено иском, поданным Sun’ом. Будучи лишенной
возможности разрабатывать клон Java с нужными ей свойствами, Microsoft создала
альтернативу, которая больше соответствовала их потребностям и видению
будущего.
Несмотря на такое
беспокойное начало, становится всё более очевидным, что два языка редко
конкурируют друг с другом на рынке. Java доминирует в мобильном секторе и имеет
много приверженцев на рынке веб-приложений. C# получил хорошее признание на
рынке настольных приложений Windows и проталкивается Майкрософтом как основной
язык приложений Windows. Благодаря ASP.NET, C# также является игроком и на
рынке веб-приложений.
Настольные приложения.
Для обоих языков имеется
набор библиотек, предоставляющих возможности построения интерфейса пользователя
для настольных приложений. В случае Java это мультиплатформенные библиотеки Swing и SWT, а также ряд менее
распространённых. В принципе, любая из них позволяет создавать
кроссплатформенные настольные приложения на Java.
Для C# на платформе Windows
основной библиотекой, реализующей графический интерфейс пользователя в
настольных приложениях, является Windows.Forms, принадлежащая Microsoft и
реализованная только для Windows, а для прочих платформ — gtk#, выполненная в
рамках проекта Mono. Попытки свободной реализации Windows.Forms предпринимались
и предпринимаются (например, в проекте DotGNU), однако
они, в силу закрытости оригинала, неизбежно страдают вторичностью и неполнотой,
вряд ли могут конкурировать с реализацией от Microsoft и потому могут
применяться разве что для запаздывающего портирования Windows-приложений на
другие платформы. Разработки, изначально базирующиеся на Windows, строятся
обычно на Windows.Forms, и их перенос на другую платформу становится
затруднительным. Разработки на C# в среде Mono, использующие gtk#, переносимы,
но их существенно меньше.
В силу особенностей языка
ручное использование графических библиотек Java несколько более затруднительно.
Архитектура графических библиотек Java более сложна для понимания начинающего
разработчика, в то же время, это заставляет его развиваться в профессиональном
плане. C# за счёт наличия встроенных средств событийного программирования
скрывает от разработчика детали обработки событий и некоторые другие моменты,
облегчая разработку интерфейса. На платформе .NET изначально широко
использовались визуальные построители интерфейса. Всё это даёт возможности для
быстрой разработки интерфейса настольных приложений при невысокой квалификации
программиста.
В последние несколько лет
Sun Microsystems сконцентрировалась на еще более широком внедрении Java на
рынок настольных приложений. В версии платформы JRE 6 (2006 год) акцент сделан
на улучшение взаимодействии с графическим окружением пользователя. Последняя
версия JVM от Sun (JDK 6 update 10) включает множество улучшений для создание
интерфейса пользователя. В частности, прозрачные формы и окна непрямоугольной формы.
Последние версии интегрированных сред разработки для Java (например, NetBeans)
также включают значительно улучшенные графические построители интерфейса
пользователя.
C#, наравне с Java, постепенно
становится популярным на нескольких операционных системах на основе Linux и
BSD.[12][13][14] Реализация проекта Mono была юридически
безболезненным процессом, поскольку CLR и язык C# стандартизированы Ecma и ISO,
и любой может их реализовывать, не беспокоясь о правовой стороне дела[15]. В то же время, следует отметить, что написанное
приложение под средой Windows может иметь значительные проблемы запуска под
другой ОС.
Серверные приложения.
На этой арене, возможно, два
языка наиболее близки к тому, чтобы считаться конкурентами. Java с её
платформой J2EE
(Java(2) Enterprise Edition) и C# с его ASP.NET соперничают в области создания
динамического веб-контента и приложений.
На этом рынке широко
используются и поддерживаются оба языка, вместе с комплектом инструментов и
сопровождающих продуктов, имеющихся для JavaEE и .NET.
Мобильные приложения.
J2ME (JavaME, Java(2)
Micro Edition) имеет очень широкую базу на рынках мобильных телефонов и КПК, где только самые
дешёвые устройства лишены KVM (урезанная Java Virtual Machine для
устройств с ограниченными ресурсами). Программы на Java, включая множество игр,
встречаются повсеместно.
В то время как почти все
телефоны включают в себя JVM, эти возможности используются большинством
пользователей не очень интенсивно. Приложения Java на большинстве телефонов
обычно состоят из систем меню, небольших игр и т. д. Полноценные приложения для
мобильных телефонов редки.
На рынке смартфонов и КПК
быстро набирает силу Windows Mobile, она же становится предпочтительной
платформой для написания тяжёлых бизнес-приложений. Windows Mobile основана на
платформе Windows CE и использует .NET Compact Framework (.NETCF) —
подмножество полной версии .NET Framework с дополнительной функциональностью
для мобильных устройств.
Прежде чем начинать создание сетевых приложений для Internet,
вы должны разобраться с адресацией компьютеров в сети с протоколом TCP/IP, на
базе которого построена сеть Internet. Все компьютеры, подключенные к сети
TCP/IP, называются узлами (в оригинальной терминологии узел - это host). Каждый
узел имеет в сети свой адрес IP, состоящий из четырех десятичных цифр в
диапазоне от 0 до 255, разделенных символом “точка “, например:
193.120.54.200
Фактически адрес IP является 32-разрядным двоичным
числом. Упомянутые числа представляют собой отдельные байты адеса IP.
Так как работать с цифрами удобно лишь компьютеру,
была придумана система доменных имен. При использовании этой системы адресам IP
ставится в соответсвие так называемый доменный адрес, такой как
www.microsoft.com.
В сети Internet имеется распределенная по всему миру
база доменных имен, в которой установлено соответствие между доменными именами
и адресами IP в виде четырех чисел.
Для работы с адресами IP в библиотеке классов Java
имеется класс InetAddress, определение наиболее интересных методов которого
приведено ниже:
public static InetAddress getLocalHost();
public static InetAddress getByName(String host);
public static InetAddress[] getAllByName(String host);
public byte[] getAddress();
public String toString();
public String getHostName();
public boolean equals(Object obj);
Рассмотрим применение этих методов.
Прежде всего, вы должны создать объект класса
InetAddress. Эта процедура выполняется не с помощью оператора new, а с
применением статических методов getLocalHost, getByName и getAllByName.
Создание
объекта класса InetAddress для локального узла.
Метод getLocalHost создает объект класса InetAddress
для локального узла, то есть для той рабочей станции, на которой выполняется
приложение Java. Так как этот метод статический, вы можете вызывать его,
ссылаясь на имя класса InetAddress:
InetAddress iaLocal;
iaLocal = InetAddress.getLocalHost();
В том случае, если вас интересует удаленный узел сети Internet
или корпоративной сети Intranet, вы можете создать для него объект класса
InetAddress с помощью методов getByName или getAllByName. Первый из них
возвращает адрес узла, а второй - массив всех адресов IP, связанных с данным
узлом. Если узел с указанным именем не существует, при выполнении методов
getByName и getAllByName возникает исключение UnknownHostException.
Заметим, что методам getByName и getAllByName можно
передавать не только имя узла, такое как “microsoft.com”, но и строку адреса IP
в виде четырех десятичных чисел, разделенных точками.
После создания объекта класса InetAddress для
локального или удаленного узла вы можете использовать другие методы этого
класса.
Метод getAddress возвращает массив из чеырех байт
адреса IP объекта. Байт с нулевым индексом этого массива содержит старший байт
адреса IP.
Метод toString возвращает текстовую строку, которая
содержит имя узла, разделитель ‘/’ и адрес IP в виде четырех десятичных чисел,
разделенных точками.
С помощью метода getHostName вы можете определить имя
узла, для которого был создан объект класса InetAddress.
И, наконец, метод equals предназначен для сравнения
адресов IP как объектов класса InetAddress.
Приложение InetAddressDemo отображает имя и адрес IP
локального узла, а затем запрашивает имя удаленного узла. Еси такой узел
существует, для него определяется и отображается на консоли список адресов IP.
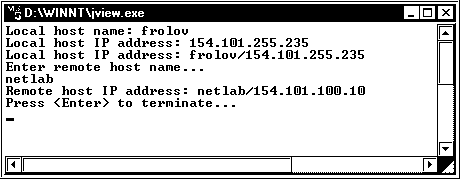
Если же указано имя несуществующего узла, возникает
исключение UnknownHostException, о чем на консоль выводится сообщение.
Исходные тексты приложения InetAddressDemo:
import java.net.*;
import java.io.*;
import java.util.*;
// =========================================================
// Класс InetAddressDemo
// Главный класс приложения
// =========================================================
public class InetAddressDemo
{ // -------------------------------------------------------
// main
// Метод, получающий управление при запуске приложения
// -------------------------------------------------------
public static void main(String args[])
{ // Массив для ввода строки с клавиатуры
byte bKbdInput[] = new byte[256];
// Введенная строка
String sIn;
// Рабочая строка
String str;
// Адрес локального узла
InetAddress iaLocal;
// Массив байт адреса локального узла
byte[] iaLocalIP;
// Массив всех адресов удаленного узла
InetAddress[] iaRemoteAll;
try
{ // Получаем адрес локального узла
iaLocal = InetAddress.getLocalHost();
// Отображаем имя локального узла на консоли
System.out.println("Local host name: " + iaLocal.getHostName());
// Определяем адрес IP локального узла
iaLocalIP = iaLocal.getAddress();
// Отображаем отдельные байты адреса IP
// локального узла
System.out.println("Local host IP address: " + (0xff & (int)iaLocalIP[0]) + "." +
(0xff & (int)iaLocalIP[1]) + "." +
(0xff & (int)iaLocalIP[2]) + "." +
(0xff & (int)iaLocalIP[3]));
// Отображаем адрес IP локального узла, полученный
// в виде текстовой строки
System.out.println("Local host IP address: " + iaLocal.toString());
// Вводим имя удаленного узла, адрес которого
// мы будет определять
System.out.println("Enter remote host name..."); System.in.read(bKbdInput);
sIn = new String(bKbdInput, 0);
// Обрезаем строку, удаляя символ конца строки
StringTokenizer st;
st = new StringTokenizer(sIn, "\r\n");
str = new String((String)st.nextElement());
// Получаем все адреса IP, свяжанные с удаленным
// узлом, имя которого мы только что ввели
iaRemoteAll = InetAddress.getAllByName(str);
// Отображаем эти адреса на консоли
for(int i = 0; i < iaRemoteAll.length; i++)
{ System.out.println("Remote host IP address: " + iaRemoteAll[i].toString());
}
System.out.println("Press <Enter> to terminate..."); System.in.read(bKbdInput);
}
catch(Exception ioe)
{ System.out.println(ioe.toString());
}
}
}
Сразу после запуска приложение создает кобъект класса
InetAddress для локального узла, вызывая для этого статический метод
getLocalHost:
iaLocal = InetAddress.getLocalHost();
Далее для созданного объекта вызывается метод
getHostName, возвращающий строку имени локального узла:
System.out.println("Local host name: " + iaLocal.getHostName());
Это имя отображается на консоли приложения.
Затем приложение определяет адрес IP локального узла,
вызывая метод getAddress:
iaLocalIP = iaLocal.getAddress();
Напомним, что этот метод возвращает массив четырех
байт адреса IP.
Адрес IP мы отображаем на консоли с помощью метода
println:
System.out.println("Local host IP address: " + (0xff & (int)iaLocalIP[0]) + "." +
(0xff & (int)iaLocalIP[1]) + "." +
(0xff & (int)iaLocalIP[2]) + "." +
(0xff & (int)iaLocalIP[3]));
Заметьте, что байты адреса записваются в массив типа
byte как знаковые величины. Для того чтобы отображить их на консоли в виде
положительных чисел, мы вначале выполняем явное преобразование к типу int, а
затем обнуляем старший байт (так как такое преобразование выполняется с
сохранением знака).
Наше приложение демонстрирует также другой способ
получения адреса IP для объекта класса InetAddress, который заключается в
вызове метода toString:
System.out.println("Local host IP address: " + iaLocal.toString());
На втором этапе приложение InetAddressDemo вводит
строку имени удаленного узла и, после удаления символа перехода на новую
строку, пытается создать для введенного имени массив объектов класса
InetAddress. Для этого приложение вызывает метод getAllByName:
iaRemoteAll = InetAddress.getAllByName(str);
Содержимое созданного массива отображается в цикле,
причем адрес IP извлекается из объектов класса InetAddress методом toString:
for(int i = 0; i < iaRemoteAll.length; i++)
{ System.out.println("Remote host IP address: " + iaRemoteAll[i].toString());
}
Класс URL в библиотеке классов Java.
Для работы с ресурсами, заданными своими адресами URL,
в библиотеке классов Java имеется очень удобный и мощный класс с названием URL.
Простота создания сетевых приложений с использованием этого класса в
значительной степени опровергает общераспространенное убеждение в сложности
сетевого программирования. Инкапсулируя в себе достаточно сложные процедуры,
класс URL предоставляет в распоряжение программиста небольшой набор простых в
использовании конструкторов и методов.
Сначала о конструкторах. Их в классе URL имеется
четыре штуки:
public URL(String spec);
Первый из них создает объект URL для сетевого ресурса,
адрес URL которого передается конструктору в виде текстовой строки через
единственный параметр spec:
public URL(String spec);
В процессе создания объекта проверяется заданный адрес
URL, а также наличие указанного в нем ресурса. Если адрес указан неверно или
заданный в нем ресурс отсутствует, возникает исключение MalformedURLException.
Это же исключение возникает при попытке использовать протокол, с которым данная
система не может работать.
Второй вариант конструктора класса URL допускает
раздельное указание протокола, адреса узла, номера порта, а также имя файла:
public URL(String protocol, String host, int port,
String file);
Третий вариант предполагает использование номера
порта, принятого по умолчанию:
public URL(String protocol, String host, String file);
Для протокола HTTP это порт с номером 80.
И, наконец, четвертый вариант конструктора допускает
указание контекста адреса URL и строки адреса URL:
public URL(URL context, String spec);
Строка контекста позволяет указывать компоненты адреса
URL, отсустсвующие в строке spec, такие как протокол, имя узла, файла или номер
порта.
Рассмотрим самые интересные методы, определенные в
классе URL.
Метод openStream.
Метод openStream позволяет создать входной поток для
чтения файла ресурса, связанного с созданным объектом класса URL:
public final InputStream openStream();
Для выполнения операции чтения из созданного таким
образом потока вы можете использовать метод read, определенный в классе InputStream
(любую из его разновидностей).
Данную пару методов (openStream из класса URL и read
из класса InputStream) можно применить для решения задачи получения содержимого
двоичного или текстового файла, хранящегося в одном из каталогов сервера Web.
Сделав это, обычное приложение Java или аплет может выполнить локальную
обработку полученного файла на компьютере удаленного пользователя.
Метод getContent.
Очень интересен метод getConten. Этот метод определяет
и получает содержимое сетевого ресурса, для которого создан объект URL:
public final Object getContent();
Практически вы можете использовать метод getContent
для получения текстовых файлов, расположенных в сетевых каталогах.
К сожалению, данный метод непригоден для получения
документов HTML, так как для данного ресурса не определен обработчик
соедржимого, предназначенный для создания объекта. Метод getContent не способен
создать объект ни из чего другого, кроме текстового файла.
Данная проблема, тем не менее, решается очень просто -
достаточно вместо метода getContent использовать описанную выше комбинацию
методов openStream из класса URL и read из класса InputStream.
Метод getHost.
С помощью метода getHost вы можете определить имя
узла, соответствующего данному объекту URL:
public String getHost();
Метод
getFile.
Метод getFile позволяет получить информацию о файле,
связанном с данным объектом URL:
public String getFile();
Метод
getPort.
Метод getPort предназначен для определения номера
порта, на котором выполняется связь для объекта URL:
public int getPort();
Метод
getProtocol.
С помощью метода getProtocol вы можете определить
протокол, с использованием которого установлено соединение с ресурсом, заданным
объектом URL:
public String getProtocol();
Метод
getRef.
Метод getRef возвращает текстовую строку ссылки на
ресурс, соответствующий данному объекту URL:
public String getRef();
Метод
hashCode.
Метод hashCode возвращает хэш-код объекта URL:
public int hashCode();
Метод
sameFile.
С помощью метода sameFile вы можете определить,
ссылаются ли два объекта класса URL на один и тот же ресурс, или нет:
public boolean sameFile(URL other);
Если объекты ссылаются на один и тот же ресурс, метод
sameFile возвращает значение true, если нет - false.
Метод equals.
Вы можете использовать метод equals для определения
идентичности адресов URL, заданных двумя объектами класса URL:
public boolean equals(Object obj);
Если адреса URL идентичны, метод equals возвращает
значение true, если нет - значение false.
Метод toExternalForm.
Метод toExternalForm возвращает текстовую строку
внешнего представления адреса URL, определенного данным объектом класса URL:
public String toExternalForm();
Метод
toString.
Метод toString возвращает текстовую строку,
представляющую данный объект класса URL:
public String toString();
Метод
openConnection.
Метод openConnection предназначен для создания канала
между приложением и сетевым ресурсом, представленным объектом класса URL:
public URLConnection openConnection();
Если вы создаете приложение, которое позволяет читать
из каталогов сервера Web текстовые или двоичные файлы, можно создать поток
методом openStream или получить содержимое текстового ресурса методом
getContent.
Однако есть и другая возможность. Вначале вы можете
создать канал, как объект класса URLConnection, вызвав метод openConnection, а
затем создать для этого канала входной поток, воспользовавшись методом
getInputStream, определенным в классе URLConnection. Такая методика позволяет
определить или установить перед созданием потока некоторые характеристики
канала, например, задать кэширование.
Однако самая интересная возможность, которую
предоставляет этот метод, заключается в организации взаимодействия приложения
Java и сервера Web.
Подробнее методика организации такого взаимодействия и
класс URLConnection будет рассмотрен позже.
В библиотеке классов Java есть очень удобное средство,
с помощью которых можно организовать взаимодействие между приложениями Java и аплетами,
работающими как на одном и том же, так и на разных узлах сети TCP/IP. Это
средство, родившееся в мире операционной системы UNIX, - так называемые сокеты
(sockets).
Что такое сокеты?
Вы можете представить себе сокеты в виде двух розеток,
в которые включен кабель, предназначенный для передачи данных через сеть.
Переходя к компьютерной терминологии, скажем, что сокеты - это программный
интерфейс, предназначенный для передачи данных между приложениями.
Прежде чем приложение сможет выполнять передачу аили
прием данных, оно должно создать сокет, указав при этом адрес узла IP, номер
порта, через который будут передаваться данные, и тип сокета.
С адресом узла IP вы уже сталкивались. Номер порта
служит для идентификации приложения. Заметим, что существуют так называемые
“хорошо известные” (well known) номера портов, зарезервированные для различных
приложений. Например, порт с номером 80 зарезервирован для использования
серверами Web при обмене данными через протокол HTTP.
Что же касается типов сокетов, то их два - потоковые и
датаграммные.
С помощью потоковых сокетов вы можете создавать каналы
передачи данных между двумя приложениями Java в виде потоков, которые мы уже
рассматривали во второй главе. Потоки могут быть входными или выходными,
обычными или форматированными, с использованием или без использования
буферизации. Скоро вы убедитесь, что организовать обмен данными между
приложениями Java с использованием потоковых сокетов не труднее, чем работать
через потоки с обычными файлами.
Заметим, что потоковые сокеты позволяют передавать
данные только между двумя приложениями, так как они предполагают создание
канала между этими приложениями. Однако иногда нужно обеспечить взаимодействие
нескольких клиентских приложений с одним серверным. В этом случае вы можете
либо создавать в серверном приложении отдельные задачи и отдельные каналы для
каждого клиентского приложения, либо воспользоваться датаграммными сокетами.
Последние позволяют передавать данные сразу всем узлам сети, хотя такая
возможность редко используется и часто блокируется администраторами сети.
Для передачи данных через датаграммные сокеты вам не
нужно создавать канал - данные посылаются непосредственно тому приложению, для
которого они предназначены с использованием адреса этого приложения в виде сокета
и номера порта. При этом одно клиентское приложение может обмениваться данными
с несколькими серверными приложениями или наоборот, одно серверное приложение -
с несколькими клиентскими.
К сожалению, датаграммные сокеты не гарантируют
доставку передаваемых пакетов данных. Даже если пакеты данных, передаваемые
через такие сокеты, дошли до адресата, не гарантируется, что они будут получены
в той же самой последовательности, в которой были переданы. Потоковые сокеты,
напротив, гарантируют доставку пакетов данных, причем в правильной
последовательности.
Причина отстутствия гарантии доставки данных при
использовании датаграммных сокетов заключается в использовании такими сокетами
протокола UDP, который, в свою очередь, основан на протоколе с
негарантированной доставкой IP. Потоковые сокеты работают через протокол
гарантированной доставки TCP.
В 23 томе “Библиотеки системного программиста”,
который называется “Глобальные сети компьютеров. Практическое введение в
Internet, E-Mail, FTP, WWW и HTML, программирование для Windows Sockets” мы уже
рассказывали про сокеты в среде операционной системы Microsoft Windows. В этой
книге вы найдете примеры приложений, составленных на языке программирования С и
работающих как с потоковыми, так и с датаграммными сокетами.
Как мы уже говорили, интерфейс сокетов позволяет
передавать данные между двумя приложениями, работающими на одном или разных
узлах сети. В процессе создания канала передачи данных одно из этих приложений
выполняет роль сервера, а другое - роль клиента. После того как канал будет
создан, приложения становятся равноправными - они могут передавать друг другу
данные симметричным образом.
Рассмотрим этот процесс в деталях.
Вначале мы рассмотрим действия приложения, которое на
момент инициализации является сервером.
Первое, что должно сделать серверное приложение, это
создать объект класса ServerSocket, указав конструктору этого класса номер
используемого порта:
ServerSocket ss;
ss = new ServerSocket(9999);
Заметим, что объект класса ServerSocket вовсе не
является сокетом. Он предназначен всего лишь для установки канала связи с
клиентским приложением, после чего создается сокет класса Socket, пригодный для
передачи данных.
Установка канала связи с клиентским приложением
выполняется при помощи метода accept, определенного в классе ServerSocket:
Socket s;
s = ss.accept();
Метод accept приостанавливает работу вызвавшей его
задачи до тех пор, пока клиентское приложение не установит канал связи с
сервером. Если ваше приложение однозадачное, его работа будет блокирована до
момента установки канала связи. Избежать полной блокировки приложения можно,
если выполнять создание канала передачи данных в отдельной задаче.
Как только канал будет создан, вы можете использовать
сокет сервера для образования входного и выходного потока класса InputStream и
OutputStream, соответственно:
InputStream is;
OutputStream os;
is = s.getInputStream();
os = s.getOutputStream();
Эти потоки можно использовать таким же образом, что и
потоки, связанные с файлами.
Обратите также внимание на то, что при создании
серверного сокета мы не указали адрес IP и тип сокета, ограничившись только
номером порта.
Что касается адреса IP, то он, очевидно, равен адресу
IP узла, на котором запущено приложение сервера. В классе ServerSocket
определен метод getInetAddress, позволяющий определить этот адрес:
public InetAddress getInetAddress();
Тип сокета указывать не нужно, так как для работы с
датаграммными сокетами предназначен класс DatagramSocket, который мы рассмотрим
позже.
Процесс инициализации клиентского приложения выглядит
весьма просто. Клиент должен просто создать сокет как объект класса Socket, указав
адрес IP серверного приложения и номер порта, используемого сервером:
Socket s;
s = new Socket("localhost",9999);
Здесь в качестве адреса IP мы указали специальный
адрес localhost, предназначенный для тестирования сетевых приложений, а в
качестве номера порта - ззначение 9999, использованное сервером.
Теперь можно создавать входной и выходной потоки. На
стороне клиента эта операция выполняется точно также, как и на стороне сервера:
InputStream is;
OutputStream os;
is = s.getInputStream();
os = s.getOutputStream();
После того как серверное и клиентское приложения
создали потоки для приема и передачи данных, оба этих приложения могут читать и
писать в канал данных, вызывая методы read и write, определенные в классах
InputStream и OutputStream.
Ниже мы представили фрагмент кода, в котором
приложение вначале читает данные из входного потока в буфер buf, а затем
записывает прочитанные данные в выходной поток:
byte buf[] = new byte[512];
int lenght;
lenght = is.read(buf);
os.write(buf, 0, lenght);
os.flush();
На базе потоков класса InputStream и OutputStream вы
можете создать буферизованные потоки и потоки для передачи форматированных данных,
о которых мы рассказывали раньше.
После завершения передачи данных вы должны закрыть
потоки, вызвав метод close:
is.close();
os.close();
Когда канал передачи данных больше не нужен, сервер и клиент
должны закрыть сокет, вызвав метод close, определенный в классе Socket:
s.close();
Серверное приложение, кроме того, должно закрыть
соединение, вызвав метод close для объекта класса ServerSocket:
ss.close();
После краткого введения в сокеты приведем описание
наиболее интересных конструкторов и методов класса Socket.
Чаще всего для создания сокетов в клиентских
приложениях вы будете использовать один из двух конструкторов, прототипы
которых приведены ниже:
public Socket(String host, int port);
public Socket(InetAddress address, int port);
Первый из этих конструкторов позволяет указывать адрес
серверного узла в виде текстовой строки, второй - в виде ссылки на объект
класса InetAddress. Вторым параметром задается номер порта, с использованием
которого будут передаваться данные.
В классе Socket определена еще одна пара
конструкторов, которая, однако, не рекомендуется для использования:
public Socket(String host, int port, boolean stream);
public Socket(InetAddress address, int port,
boolean stream);
В этих конструкторах последний параметр определяет тип
сокета. Если этот параметр равен true, создается потоковый сокет, а если false
- датаграммный. Заметим, однако, что для работы с датаграммными сокетами
следует использовать класс DatagramSocket.
Перечислим наиболее интересные, на наш взгляд, методы
класса Socket.
Прежде всего, это методы getInputStream и getOutputStream,
предназначенные для создания входного и выходного потока, соответственно:
public InputStream getInputStream();
public OutputStream getOutputStream();
Эти потоки связаны с сокетом и должны быть
использованы для передачи данных по каналу связи.
Методы getInetAddress и getPort позволяют определить
адрес IP и номер порта, связанные с данным сокетом (для удаленного узла):
public InetAddress getInetAddress();
public int getPort();
Метод getLocalPort возвращает для данного сокета номер
локального порта:
public int getLocalPort();
После того как работа с сокетом завершена, его
необходимо закрыть методом close:
public void close();
И, наконец, метод toString возвращает текстовую
строку, представляющую сокет:
public String toString();
Приложения SocketServ и SocketClient.
В качестве примера мы приведем исходные тексты двух
приложений Java, работающих с потоковыми сокетами. Одно из этих приложений
называется SocketServ и выполняет роль сервера, второе называется SocketClient
и служит клиентом.
Приложение SocketServ выводит на консоль строку
“Socket Server Application” и затем переходит в состояние ожидания соединения с
клиентским приложением SocketClient.
Приложение SocketClient устанавливает соединение с сервером
SocketServ, используя потоковый сокет с номером 9999 (этот номер выбран нами
произвольно). Далее клиентское приложение выводит на свою консоль приглашение
для ввода строк. Введенные строки отображаются на консоли и передаются
серверному приложению. Сервер, получив строку, отображает ее в своем окне и
посылает обратно клиенту. Клиент выводит полученную от сервера строку на
консоли.
Когда пользователь вводит строку “quit”, цикл ввода и
передачи строк завершается.
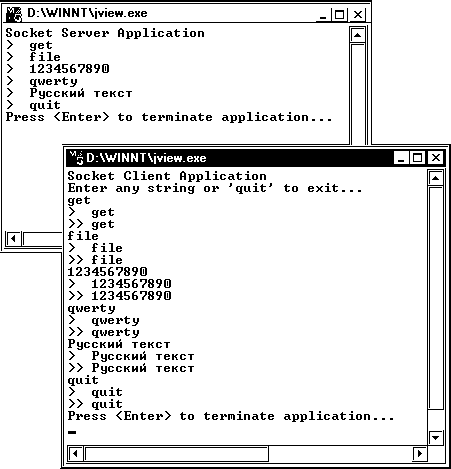
Весь процесс показан на рисунке.
Передача данных между приложениями SocketClient и
SocketServ через потоковый сокет.
Здесь в окне клиентского приложения мы ввели несколько
строк, причем последняя строка была строкой “quit”, завершившая работу
приложений.
Исходный текст серверного приложения SocketServ
приведен в листинге.
Листинг Файл
SocketServ\SocketServ.java
import java.io.*;
import java.net.*;
import java.util.*;
public class SocketServ
{ // -------------------------------------------------------
// main
// Метод, получающий управление при запуске приложения
// -------------------------------------------------------
public static void main(String args[])
{ // Массив для ввода строки с клавиатуры
byte bKbdInput[] = new byte[256];
// Объект класса ServerSocket для создания канала
ServerSocket ss;
// Сокет сервера
Socket s;
// Входной поток для приема команд от клиента
InputStream is;
// Выходной поток для передачи ответа клиенту
OutputStream os;
try
{ System.out.println("Socket Server Application"); }
catch(Exception ioe)
{ // При возникновении исключения выводим его описание
// на консоль
System.out.println(ioe.toString());
}
try
{ // Создаем объект класса ServerSocket
ss = new ServerSocket(9999);
// Ожидаем соединение
s = ss.accept();
// Открываем входной поток для приема
// команд от клиента
is = s.getInputStream();
// Открываем выходной поток для передачи
// ответа клиенту
os = s.getOutputStream();
// Буфер для чтения команд
byte buf[] = new byte[512];
// Размер принятого блока данных
int lenght;
// Цикл обработки команд, полученных от клиента
while(true)
{ // Получаем команду
lenght = is.read(buf);
// Если входной поток исчерпан, завершаем
// цикл обработки команд
if(lenght == -1)
break;
// Отображаем принятую команду на консоли сервера
// Формируем строку из принятого блока
String str = new String(buf, 0);
// Обрезаем строку, удаляя символ конца строки
StringTokenizer st;
st = new StringTokenizer(str, "\r\n");
str = new String((String)st.nextElement());
// Выводим строку команды на консоль
System.out.println("> " + str);
// Посылаем принятую команду обратно клиенту
os.write(buf, 0, lenght);
// Сбрасываем буфер выходного потока
os.flush();
}
// Закрываем входной и выходной потоки
is.close();
os.close();
// Закрываем сокет сервера
s.close();
// Закрываем соединение
ss.close();
}
catch(Exception ioe)
{ System.out.println(ioe.toString());
}
try
{ System.out.println(
"Press <Enter> to terminate application...");
System.in.read(bKbdInput);
}
catch(Exception ioe)
{ System.out.println(ioe.toString());
}
}
}
В методе main, получающем управление сразу после
запуска приложения, мы определили несколько переменных.
Массив bKbdInput размером 256 байт предназначен для
хранения строк, введенных при помощи клавиатуры.
В переменную ss класса ServerSocket будет записана
ссылка на объект, предназначенный для установления канала связи через потоковый
сокет (но не ссылка на сам сокет):
ServerSocket ss;
Ссылка на сокет, с использованием, которого будет
происходить передача данных, хранится в переменной с именем s класса Socket:
Socket s;
Кроме того, мы определили переменные is и os,
соответственно, классов InputStream и OutputStream:
InputStream is;
OutputStream os;
В эти переменные будут записаны ссылки на входной и
выходной поток данных, которые связаны с сокетом.
После отображения на консоли строки названия
приложения, метод main создает объект класса ServerSocket, указывая
конструктору номер порта 9999:
ss = new ServerSocket(9999);
Конструктор возвращает ссылку на объект, с
использованием которого можно установить канал передачи данных с клиентом.
Канал устанавливается методом accept:
s = ss.accept();
Этот метод переводит приложение в состояние ожидания
до тех пор, пока не будет установлен канал передачи данных.
Метод accept в случае успешного создания канала
передачи данных возвращает ссылку на сокет, с применением которого нужно
принимать и передавать данные.
На следующем этапе сервер создает входной и выходной
потоки, вызывая для этого методы getInputStream и getOutputStream,
соответственно:
is = s.getInputStream();
os = s.getOutputStream();
Далее приложение подготавливает буфер buf для приема
данных и определяет переменную length, в которую будет записываться размер
принятого блока данных:
byte buf[] = new byte[512];
int lenght;
Теперь все готово для запуска цикла приема и обработки
строк от клиентского приложения.
Для чтения строки мы вызываем метод read применительно
ко входному потоку:
lenght = is.read(buf);
Этот метод возвращает управление только после того,
как все данные будут прочитаны, блокируя приложение на время своей работы. Если
такая блокировка нежелательна, вам следует выполнять обмен данными через сокет
в отдельной задаче.
Метод read возвращает размер принятого блока данных
или -1, если поток исчерпан. Мы воспользовались этим обстоятельством для
завершения цикла приема данных:
if(lenght == -1)
break;
После завершения приема блока данных мы преобразуем
массив в текстовую строку str класса String, удаляя из нее символ перевода
строки, и отображаем результат на консоли сервера:
System.out.println("> " + str);
Затем полученная строка отправляется обратно
клиентскому приложению, для чего вызывается метод write:
os.write(buf, 0, lenght);
Методу write передается ссылка на массив, смещение
начала данных в этом массиве, равное нулю, и размер принятого блока данных.
Для исключения задержек в передаче данных из-за
накопления данных в буфере (при использовании буферизованных потоков)
необходимо принудительно сбрасывать содержимое буфреа метдом flush:
os.flush();
И хотя в нашем случае мы не пользуемся буферизованными
потоками, мы включили вызов этого метода для примера.
Теперь о завершающих действиях после прерывания цикла
получения, отображения и передачи строк.
Наше приложение явням образом закрывает входной и
выходной потоки данных, сокет, а также объект класса ServerSocket, с
использованием которого был создан канал передачи данных:
is.close();
os.close();
s.close();
ss.close();
Исходный текст клиентского приложения SocketClient
приведен в листинге
Листинг Файл
SocketClient\SocketClient.java
// =========================================================
// Использование потоковых сокетов.
// Приложение клиента
//
// (C) Фролов А.В, 1997
//
// E-mail: frolov@glas.apc.org
// WWW: http://www.glasnet.ru/~frolov
// или
// http://www.dials.ccas.ru/frolov
// =========================================================
import java.io.*;
import java.net.*;
import java.util.*;
public class SocketClient
{ // -------------------------------------------------------
// main
// Метод, получающий управление при запуске приложения
// -------------------------------------------------------
public static void main(String args[])
{ // Массив для ввода строки с клавиатуры
byte bKbdInput[] = new byte[256];
// Сокет для связи с сервером
Socket s;
// Входной поток для приема данных от сервера
InputStream is;
// Выходной поток для передачи данных серверу
OutputStream os;
try
{ // Выводим строку приглашения
System.out.println("Socket Client Application" + "\nEnter any string or 'quit' to exit...");
}
catch(Exception ioe)
{ // При возникновении исключения выводим его описание
// на консоль
System.out.println(ioe.toString());
}
try
{ // Открываем сокет
s = new Socket("localhost",9999);
// Создаем входной поток для приема данных от сервера
is = s.getInputStream();
// Создаем выходной поток для передачи данных серверу
os = s.getOutputStream();
// Буфер для передачи данных
byte buf[] = new byte[512];
// Размер принятого блока данных
int length;
// Рабочая строка
String str;
// Вводим команды и передаем их серверу
while(true)
{ // Читаем строку команды с клавиатуры
length = System.in.read(bKbdInput);
// Если строка не пустая, обрабатываем ее
if(length != 1)
{ // Преобразуем строку в формат String
str = new String(bKbdInput, 0);
// Обрезаем строку, удаляя символ конца строки
StringTokenizer st;
st = new StringTokenizer(str, "\n");
str = new String((String)st.nextElement());
// Выводим передаваемую строку команды
// на консоль для контроля
System.out.println("> " + str);
// Записываем строку в выходной поток,
// передавая ее таким образом серверу
os.write(bKbdInput, 0, length);
// Сбрасываем буфер выходного потока
os.flush();
// Принимаем ответ сервера
length = is.read(buf);
if(length == -1)
break;
// Отображаем принятую строку на консоли
str = new String(buf, 0);
st = new StringTokenizer(str, "\n");
str = new String((String)st.nextElement());
System.out.println(">> " + str);
// Если введена строка 'quit', завершаем
// работу приложения
if(str.equals("quit")) break;
}
}
// Закрываем входной и выходной потоки
is.close();
os.close();
// Закрываем сокет
s.close();
}
catch(Exception ioe)
{ System.out.println(ioe.toString());
}
try
{ System.out.println(
"Press <Enter> to terminate application...");
System.in.read(bKbdInput);
}
catch(Exception ioe)
{ System.out.println(ioe.toString());
}
}
}
Внутри метода main клиентского приложения SocketClient
определены переменные для ввода строки с клавиатуры (массив bKbdInput), сокет s
класса Socket для работы с сервером SocketServ, входной поток is и выходной
поток os, которые связаны с сокетом s.
После вывода на консоль приглашающей строки клиентское
приложение создает сокет, вызывая конструктор класса Socket:
s = new Socket("localhost",9999);
В процессе отладки мы запускали сервер и клиент на одном
и том же узле, поэтому в качестве адреса сервера указана строка “localhost”.
Номер порта сервера SocketServ равен 9999, поэтому мы и передали конструктору
это значение.
После создания сокета наше клиентское приложение
создает входной и выходной потоки, связанные с этим сокетом:
is = s.getInputStream();
os = s.getOutputStream();
Теперь клиентское приложение готово обмениваться
данными с сервером.
Этот обмен выполняется в цикле, условием завершения
которого является ввод пользователем строки “quit”.
Внутри цикла приложение читает строку с клавиатуры,
записывая ее в массив bKbdInput:
length = System.in.read(bKbdInput);
Количество введенных символов сохраняется в переменной
length.
Далее если пользователь ввел строку, а не просто нажал
на клавишу <Enter>, эта строка отображается на консоли и передается
серверу:
os.write(bKbdInput, 0, length);
os.flush();
Сразу после передачи сбрасывается буфер выходного
потока.
Далее приложение читает ответ, посылаемый сервером, в
буфер buf:
length = is.read(buf);
Напомним, что наш сервер посылает клиенту принятую
строку в неизменном виде.
Если сервер закрыл канал, то метод read возвращает
значение -1. В этом случае мы прерываем цикл ввода и передачи строк:
if(length == -1)
break;
Если же ответ сервера принят успешно, принятые данные
записываются в строку str, которая отображается на консоли клиента:
System.out.println(">> " + str);
Перед завершением своей работы клиент закрывает
входной и выходной потоки, а также сокет, на котором выполнялась передача
данных:
is.close();
os.close();
s.close();
Итак, мы расказали вам, как приложения Java могут
получать с сервера Web для обработки произвольные файлы, а также как они могут передавать
данные друг другу с применением потоковых или датаграммных сокетов.
Однако наиболее впечатляющие возможности открываются,
если организовать взаимодействие между приложением Java и расширением сервера
Web, таким как CGI или ISAPI. В этом случае приложения или аплеты Java могли бы
посылать произвольные данные расширению сервера Web для обработки, а затем
получать результат этой обработки в виде файла.
Методика организации взаимодействия приложений Java и
расширений сервера Web основана на применении классов URL и URLConnection.
Приложение Java, желающее работать с расширением
сервера Web, создает объект класса URL для программы расширения (то есть для
исполняемого модуля расширения CGI или библиотеки динамической компоновки DLL
расширения ISAPI).
Далее приложение получает ссылку на канал передачи
данных с этим расширением как объекта класса URLConnection. Затем, пользуясь
методами getOutputStream и getInputStream из класса URLConnection, приложение
создает с расширением сервера Web выходной и входной канал передачи данных.
Когда данные передаются приложением в выходной канал,
созданный подобным образом, он попадает в стандартный поток ввода приложения
CGI, как будто бы данные пришли методом POST из формы, определенной в документе
HTML.
Обработав полученные данные, расширение CGI записывает
их в свой стандартный выходной поток, после чего эти данные становятся доступны
приложению Java через входной поток, открытый методом getInputStream класса URLConnection.
На рисунке показаны потоки данных для описанной выше
схемы взаимодействия приложения Java и расширения сервреа Web с интерфейсом
CGI.
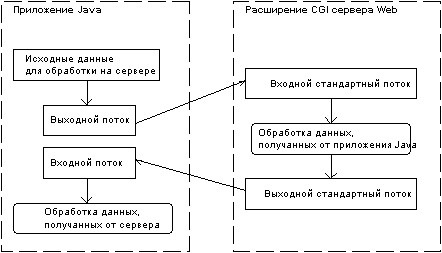
Взаимодействие приложения Java с расширением сервера
Web на базе интерфейса CGI.
Расширения ISAPI работают аналогично, однако они
получают данные не из стандратного входного потока, а с помощью вызова
специально предназначенной для этого функции интерфейса ISAPI. Вместо
стандартного потока вывода также применяется специальная функция.
Напомним, что в классе URL, рассмотренном нами в
начале этой главы, мы привели прототип метода openConnection, возвращающий для
заданного объекта класса URL ссылку на объект URLConnection:
public URLConnection openConnection();
Что мы можем получить, имея ссылку на этот объект?
Прежде всего, пользуясь этой ссылкой, мы можем
получить содержимое объекта, адресуемое соответствующим объектом URL, методом
getContent:
public Object getContent();
Заметим, что метод с таким же названием есть и в
классе URL. Поэтому если все, что вы хотите сделать, это получение содержимое
файла, адресуемое объектом класса URL, то нет никакой необходимости обращаться
к классу URLConnection.
Метод getInputStream позволяет открыть входной поток
данных, с помощью которого можно считать файл или получить данные от расширения
сервера Web:
public InputStream getInputStream();
В классе URLConnection определен также метод
getOutputStream, позволяющий открыть выходной поток данных:
public OutputStream getOutputStream();
Не следует думать, что этот поток можно использовать
для записи файлов в каталоги сервера Web. Однако для этого потока есть лучшее
применение - с его помощью можно передать данные расширению сервера Web.
Рассмотрим еще несколько полезных методов,
определенных в классе URLConnection.
Метод connect предназначен для установки соединения с
объектом, на который ссылается объект класса URL:
public abstract void connect();
Перед установкой соединения приложение может
установить различные параметры соединения. Некоторые из методов, предназначенных
для этого, приведены ниже:
// Включение или отключение кэширования по умолчанию
public void
setDefaultUseCaches(boolean defaultusecaches);
// Включение или отключение кэширования
public void setUseCaches(boolean usecaches);
// Возможность использования потока для ввода
public void setDoInput(boolean doinput);
// Возможность использования потока для вывода
public void setDoOutput(boolean dooutput);
// Установка даты модификации документа
public void setIfModifiedSince(long ifmodifiedsince);
В классе URLConnection есть методы, позволяющие
определить значения параметров, установленных только что описанными методами:
public boolean getDefaultUseCaches();
public boolean getUseCaches();
public boolean getDoInput();
public boolean getDoOutput();
public long getIfModifiedSince();
Определенный интерес могут представлять методы,
предназначенные для извлечения информации из заголовка протокола HTTP:
// Метод возвращает содержимое заголовка content-encoding
// (кодировка ресурса, на который ссылается URL)
public String getContentEncoding();
// Метод возвращает содержимое заголовка content-length
// (размер документа)
public int getContentLength();
// Метод возвращает содержимое заголовка content-type
// (тип содержимого)
public String getContentType();
// Метод возвращает содержимое заголовка date
// (дата посылки ресурса в секундах с 1 января 1970 года)
public long getDate();
// Метод возвращает содержимое заголовка last-modified
// (дата изменения ресурса в секундах с 1 января 1970 года)
public long getLastModified();
// Метод возвращает содержимое заголовка expires
// (дата устаревания ресурса в секундах с
// 1 января 1970 года)
public long getExpiration();
Другие методы, определенные в
классе URLConnection, позволяют получить все заголовки или заголовки с заданным
номером, а также другую информацию о соединении.
Наверное, сегодня уже нет необходимости объяснять, что
такое многопоточность. Все современные операционные системы, такие как Windows
95, Windows NT, OS/2 или UNIX способны работать в многопоточном режиме, повышая
общую производительность системы за счет эффективного распараллеливания
выполняемых потоков. Пока один поток находится в состоянии ожидания, например,
завершения операции обмена данными с медленным периферийным устройством, другой
может продолжать выполнять свою работу.
Пользователи уже давно привыкли запускать параллельно
несколько приложений для того чтобы делать несколько дел сразу. Пока одно из
них занимается, например, печатью документа на принтере или приемом электронной
почты из сети Internet, другое может пересчитывать электронную таблицу или
выполнять другую полезную работу. При этом сами по себе запускаемые приложения
могут работать в рамках одного потока - операционная система сама заботится о
распределении времени между всеми запущенными приложениями.
Создавая приложения для операционной системы Windows
на языках программирования С или С++, вы могли решать многие задачи, такие как
анимация или работа в сети, и без использования многопоточности. Например, для
анимации можно было обрабатывать сообщения соответствующим образом настроенного
таймера.
Приложениям Java такая методика недоступна, так как в
этой среде не предусмотрено способов периодического вызова каких-либо процедур.
Поэтому для решения многих задач вам просто не обойтись без многопоточности.
Процессы,
потоки и приоритеты.
Прежде чем приступить к разговору о многопоточности,
следует уточнить некоторые термины.
Обычно в любой многопоточной операционной системе
выделяют такие объекты, как процессы и потоки. Между ними существует большая
разница, которую следует четко себе представлять.
Процесс (process) - это объект, который создается
операционной системой, когда пользователь запускает приложение. Процессу
выделяется отдельное адресное пространство, причем это пространство физически
недоступно для других процессов. Процесс может работать с файлами или с
каналами связи локальной или глобальной сети. Когда вы запускаете текстовый
процессор или программу калькулятора, вы создаете новый процесс.
Для каждого процесса операционная система создает один
главный поток (thread), который является потоком выполняющихся по очереди
команд центрального процессора. При необходимости главный поток может создавать
другие потоки, пользуясь для этого программным интерфейсом операционной
системы.
Все потоки, созданные процессом, выполняются в
адресном пространстве этого процесса и имеют доступ к ресурсам процесса. Однако
поток одного процесса не имеет никакого доступа к ресурсам потока другого
процесса, так как они работают в разных адресных пространствах. При
необходимости организации взаимодействия между процессами или потоками, принадлежащими
разным процессам, следует пользоваться системными средствами, специально
предназначенными для этого.
Если процесс создал несколько потоков, то все они выполняются
параллельно, причем время центрального процессора (или нескольких центральных
процессоров в мультипроцессорных системах) распределяется между этими потоками.
Распределением времени центрального процессора
занимается специальный модуль операционной системы - планировщик. Планировщик
по очереди передает управление отдельным потокам, так что даже в
однопроцессорной системе создается полная иллюзия параллельной работы
запущенных потоков.
Распределение времени выполняется по прерываниям
системного таймера. Поэтому каждому потоку дается определенный интервал
времени, в течении которого он находится в активном состоянии.
Заметим, что распределение времени выполняется для
потоков, а не для процессов. Потоки, созданные разными процессами, конкурируют
между собой за получение процессорного времени.
Каким именно образом?
Приложения Java могут указывать три значения для
приоритетов потоков. Это NORM_PRIORITY, MAX_PRIORITY и MIN_PRIORITY.
По умолчанию вновь созданный поток имеет нормальный
приоритет NORM_PRIORITY. Если остальные потоки в системе имеют тот же самый
приоритет, то все потоки пользуются процессорным времени на равных правах.
При необходимости вы можете повысить или понизить
приоритет отдельных потоков, определив для них значение приоритета, соответственно,
MAX_PRIORITY или MIN_PRIORITY. Потоки с повышенным приоритетом выполняются в
первую очередь, а с пониженным - только при отсутствии готовых к выполнению
потоков, имеющих нормальный или повышенный приоритет.
Параллельные вычисления в настоящее время являются
одной из самых приоритетных задач в области информатики. Если посмотреть на
список TOP 100 (самые быстродействующие компьютеры в мире), легко заметить, что
вся верхушка списка занята системами с массовым параллелизмом, состоящим из
нескольких сотен, а то и тысяч процессорных блоков. Основная проблема
заключается в том, что собрать такую систему зачастую оказывается проще, чем
использовать, т.к. реализовать алгоритм, который будет эффективно
распараллеливать свою работу на сотнях имеющихся в наличии вычислительных
блоках, очень непросто. А от не адаптированного алгоритма толку на подобном
суперкомпьютере не будет – скорость его выполнения будет не намного выше, чем
на обычном PC.
Но программирование суперкомпьютеров и создание
эффективных параллельных алгоритмов – это отдельная и очень сложная тема. Ей
посвящено множество научных исследований, имеется большое количество интересных
статей и книг. Правда, следует признать, что эффективного и простого способа
создания параллельных программ до сих пор не существует. В этой статье мы
затронем другую тему – использование параллелизма в обычных приложениях.
Ещё несколько лет назад создатели прикладных программ
вполне обходились без параллелизма на уровне приложения. Как устроена типичная
простая программа под Windows – есть цикл обработки событий (event loop),
внутри которого реализована вся логика взаимодействия программы с
пользователем. Нажал пользователь клавишу Enter – программе пришло
соответствующее событие и вызвалась функция-обработчик для этого события. Эта
функция выполнила некоторые действия (например, сохранила введённые
пользователем данные и вывела на экран новую форму) и вернула управление в
основной цикл. После чего программа ждёт прихода следующего события. Всё
просто, красиво, удобно для программирования и… неудобно для пользователя. Дело
в том, что не все операции программа может выполнить мгновенно. Например,
копирование файла на дискетку занимает достаточно много времени. Поскольку в
это время программа не готова к приёму следующих событий, она просто не
реагирует на действия пользователя. Максимум, что можно сделать – это сменить
тип курсора на часики и вывести окошко с сообщением: "подождите
минутку". А зачастую пользователю остаётся только гадать –
"зависла" программа или всё-таки она что-то делает и стоит немного
подождать (опытные пользователи способны определить это по «косвенным
признакам» - загрузке CPU, активности диска…). А в чём заключается причина проблемы?
В том, что программа не в состоянии выполнять параллельно две операции:
копирование файла и обработку пользовательских событий.
Другой пример. Рассмотрим создание сёрверных
приложений. Классический сценарий - с каждым клиентом сёрвер устанавливает
соединение по сокету (socket); с помощью системного вызова select программа
определяет, по какому из сокетов получены данные. Дальше - цикл, который
вызывает подпрограмму-агента для обработки запроса от данного клиента.
Структура программы получается достаточно простой, но проблемы возникают и
здесь. Во-первых, проблема с эффективным использованием ресурсов сёрвера: пока
выполняется один запрос, остальные ждут. Во-вторых, если выполнение запроса
требует много времени, то время реакции сёрвера оказывается неприемлемым. Не
удаётся равномерно загрузить все ресурсы сёрвера и за счёт этого повысить
производительность. Если обработчик запроса, например, читает данные с диска,
то CPU при этом обычно простаивает, а хотелось бы использовать его для
обработки других запросов, не требующих доступа к диску.
Другая проблема связана с тем, что часто для клиента
необходимо помнить контекст, т.е. обработка текущего запроса клиента зависит от
результата предыдущих запросов. В принципе ничего страшного в этом нет: мы
можем завести специальную структуру данных и запоминать состояние для каждого
клиента. Получается этакий конечный автомат, рёбра которого соответствуют
приходящим от клиента запросам. Конечный автомат – очень гибкий и мощный
механизм, только вот программировать его – занятие не из приятных. Приходится
постоянно помнить, кто у нас в каком состоянии и куда он потом может попасть.
Опять-таки сохранение и получение текущего состояния не способствует
компактности и простоте кода программы. Было бы гораздо проще, если бы с каждым
клиентом был связан отдельный поток, в котором хранятся все данные этого
клиента и который может выполняться параллельно с потоками для других клиентов.
Параллелизм
с точки зрения ОС.
Параллельные программы появились достаточно давно.
Даже такие примитивные системы как MS-DOS, были способны параллельно выполнять
несколько программ. Конечно, если в машине всего один процессор, то полного
параллелизма, конечно, достичь не удастся. Процессор в каждый момент времени
может выполнять команды только одной программы. Тут уже задача операционной
системы обеспечить правильное планирование выполнения различных программ, так
чтобы и различные устройства (диск, процессор) использовались эффективно, и
каждой программе «честно» бы выделялся свой квант времени.
Классический алгоритм планирования выполнения программ
использует одну или несколько очередей с задачами, готовыми к выполнению.
Каждой задаче назначается свой приоритет выполнения. Обычно интерактивным
задачам (задачам, взаимодействующим с пользователями) следует назначать более
высокий приоритет по сравнению с преимущественно вычислительными задачами.
Также высокий приоритет нужен критичным по времени задачам, таким, как
управление записью на компакт диск или проигрыватель музыки. Приоритет
программы может меняться в процессе работы – давно находящейся в режиме
ожидания задаче можно поднять приоритет, а активно выполняющейся – наоборот
снизить. Это способствует более «честному» планированию задач и быстрой реакции
на команды пользователя. Планировщик задач выбирает задачу из начала списка
наиболее высокоприоритетных задач, выделяет ей квант времени для выполнения и
передаёт ей управление. Далее возможно следующее:
· Программа полностью отрабатывает свой квант времени.
Тогда планировщик заносит её в конец списка готовых к выполнению задач и
выбирает для выполнения следующую задачу с наибольшим приоритетом.
· Программа инициирует операцию, которая не может быть
немедленно выполнена (например, чтение с диска). В этом случае планировщик
переносит задачу в список ждущих задач и выбирает следующую, готовую для
выполнения. По окончании операции задача будет опять помещена в список готовых
к выполнению.
· Происходит системное прерывание или появляется задача
с большим приоритетом, готовая к выполнению. Планировщик определяет, может ли
программа продолжить работу или следует запустить более высокоприоритетный
процесс.
Подобная схема ещё называется «преимущественной
многозадачностью» (preemptive multitasking). При такой схеме никакая задача не
может полностью блокировать выполнение задач с таким же или большим
приоритетом. Некоторые старые ОС (например, Windows 95) имели более простую в
реализации модель параллелизма (называемую «не выталкивающей
многозадачностью»), когда перепланирование процессов происходит только при
желании активного процесса. Т.е. задача должна сама информировать ОС, что её
можно прервать. Естественно не правильно работающая программа при такой схеме
может полностью блокировать работу системы, что и является следствием гораздо
менее стабильной работы Win 95, по сравнению, например, с семейством Windows
NT.
Поток –
понимание параллельных процессов.
Итак, параллельные процессы используются уже
достаточно давно. Почему же их нельзя использовать для решения наших задач?
Ответ: можно, но неудобно. Дело в том, что процесс представляет собой
достаточно замкнутую систему. У процесса есть своя память (команд и данных),
свой стек, свои дескрипторы для доступа к файлам и другим устройствам и т.д.
При этом средства взаимодействия процессов между собой достаточно ограничены
предоставляемым ОС API. Обычно средства межпроцессорного взаимодействия
включают в себя очереди для обмена сообщениями между процессами, разделяемую
память (shared memory) и синхронизационные примитивы: семафоры, события,
критические секции. Т.е. если вы хотите выполнить фоновое сохранение данных на
диск, вам нужно будет создать новый процесс, использовать один из существующих
механизмов межпроцессорного взаимодействия (IPC) для передачи этому процессу
имени файла и данных, которые должны быть сохранены, после этого, опять-таки с
использованием IPC, получить от процесса уведомление о завершении операции. В
общем, простейшая операция выливается во множество строчек кода. Проблема ещё
состоит в том, что, так как с процессом связано достаточно много данных, то и
порождение процесса и переключение контекста процессов представляет собой
достаточно трудоёмкую операцию. Таким образом, использовать различные процессы
для распараллеливания работы можно только если эти работы слабо связаны с друг
другом. В этом случае процессы могут работать почти независимо друг от друга.
Если же для выполнения необходим интенсивный обмен данными, то накладные
расходы от межпроцессного взаимодействия и переключения контекстов часто
оказываются настолько большими, что всякий выигрыш от параллельной работы
процессов теряется.
Поэтому не удивительно, что почти во всех современных
операционных системах поддерживаются облегчённые процессы или потоки (threads).
На самом деле реализации потоков в разных ОС может существенно отличаться. Но мы
не будем здесь заострять на этом внимание. Определим поток как самостоятельную
активность внутри процесса. Поток имеет свой стек, но не имеет своей
собственной памяти. Вместо этого все потоки в процессе разделяют общую память
(т.е. один поток может получить доступ к данным другого потока). Это
значительно упрощает передачу данных между потоками (механизм передачи данных
ничем не отличается от передачи параметров в подпрограмму). Но при этом, в
отличие от процесса, данные которого изолированы от других процессов, данные
потока могут быть изменены любым другим потоком, что, конечно, требует
повышенного внимания при программировании многопоточных приложений и
аккуратного использования синхронизации (об этом позже).
За счёт того, что у потока гораздо меньше собственных
ресурсов, чем у процесса, создание потока требует гораздо меньше времени, чем
запуск процесса. Также переключение контекста между различными потоками в
рамках одного процесса выполняется гораздо быстрее, чем переключение между
различными процессами (все потоки внутри одного процесса имеют общую память,
поэтому при переключении контекста не надо менять таблицу отображения страниц).
Планирование выполнения потоков система осуществляет точно
так же, как планирование процессов. Точнее, во многих операционных системах,
поддерживающих потоки, единицей планирования является именно поток, а не
процесс. Важно отметить, что операционная система способна организовать
параллельное выполнение потоков: либо распределением потоков по различным
процессорным устройствам (на многопроцессорной машине), либо используя
перепланировку по истечении отведённого потоку кванта времени. В обоих случаях
надо быть готовым к тому, что выполнение потока может быть прервано в любой
момент и управление передано другому потоку (это не совсем так – есть понятие
атомарной, т.е. неделимой операции, но какая операция атомарная, а какая нет,
зависит от архитектуры системы, используемого языка, типа данных и даже опций
компилятора, по этому мы не будем здесь это обсуждать).
Создание
потоков в Java.
Механизм потоков в Java использует усовершенствованную
схему мониторов Хоара. Потоку соответствует класс java.lang.Thread. Для
создания своего потока можно либо вывести свой класс из Thread, либо
реализовать интерфейс Runnable. И в том, и в другом случае необходимо
реализовать собственный метод run(), который, собственно, и будет выполнять
нужное действие. Запустить поток на выполнение можно методом start(). Если
необходимо дождаться завершения потока, надо использовать метод join(). Ниже
приведены примеры для двух способов создания потока:
class MyThread extends Thread { public void run() { System.out.println("Thread is running"); }
}
public static void main(String args[]) { MyThread thread = new MyThread();
thread.start();
try { thread.join();
} catch (InterruptedException
x) {}}
или
class MyActivity implements Runnable { public void run() { System.out.println("Thread is running"); }
}
public static void main(Strnig args[]) { MyActivity myActivity = new MyActivity();
Thread thread = new Thread(myActivity);
thread.start();
try { thread.join();
} catch (InterruptedException x) {}
}
А что будет, если не дожидаться завершения потока?
Программа будет активна, пока работает по крайней мере один поток. Т.е.,
другими словами, программа ждёт завершения всех запущенных потоков. Иногда это
не нужно. В этом случае надо пометить поток как «демон» с помощью метода
setDaemon(true). Завершения "демонов" программа не дожидается и
просто их останавливает. Вызвать setDaemon метод нужно до запуска потока.
Ну, хорошо – потоки мы запускать научились. Всё – задача решена? Нет, на самом
деле это только начало. Как мы уже говорили, все потоки разделяют общую память.
Посмотрим, чем это чревато. Допустим, мы пишем банковскую систему для
обслуживания банкоматов, и у нас есть метод, который проверяет, достаточно ли у
клиента денег на счету и, если да, снимает запрошенную сумму со счёта и даёт
банкомату "добро" на выдачу денег:
class Account { private int balance;
public boolean withdraw(int amount) { if (amount > balance) { return false;
}
balance -= amount;
return true;
}
}
Так как банкоматов у нас много, мы решаем
реализовать параллельную обработку запросов и для этого используем потоки.
Вроде бы всё прекрасно работает (в этом и заключается одна из основных проблем
параллельного программирования – ошибки очень трудно воспроизводимы). Теперь
давайте внимательно проанализируем код. Итак, метод withdraw() может
параллельно выполняться несколькими потоками. Как мы уже отмечали, поток может
быть прерван в любой момент времени. Поэтому возможет такой сценарий:
1. Имеется два потока П1 и П2, в которых вызывается метод
withdraw() Пусть на счету находится сумма в 100уе, П1 запрашивает 80уе, а П2 –
60уе.
2. Поток П1 проверяет условие (amount < balance). Оно
истинно (80 < 100).
3. Происходит перепланировка потоком, управление получает
поток П2
4. Поток П2 проверяет условие (amount < balance). Оно
тоже истинно (60 < 100).
5. Поток П2 уменьшает баланс на затребованную величину и
возвращает true. Теперь баланс равен 40уе.
6. Управление возвращается потоку П1.
7. Он тоже уменьшает значение баланса и возвращает true.
Баланс равен… -40уе!
Н-да, так с деньгами
обращаться нельзя. Параллелизм - это конечно здорово, но целостность данных от
этого страдать не должна. Кусок кода программы, в котором недопустимо влияние
других потоков, называется критической секцией. В критическую секцию дозволено входить
только одному потоку. Остальные будут ждать, пока этот поток не покинет
критическую секцию. В языке Java для оформления критической секции
предусмотрено ключевое слово synchronized(синхронизированный). Можно объявить
синхронизированными как весь метод, так и отдельный блок операторов:
boolean synchronized withdraw(int amount) { if (amount > balance) { return false;
}
balance -= amount;
return true;
}
или
boolean withdraw(int amount) { synchronized(this) { if (amount > balance) { return false;
}
balance -= amount;
return true;
}
}
В данном случае оба способа
эквивалентны. Первый представляется более удобным, а второй обеспечивает
большую гибкость.
Что означает аргумент this в конструкции
synchronized(this)? В Java с каждым объектом неявно связан монитор – т.е.
нечто, отвечающее за синхронизацию доступа к данному объекту. Вся синхронизация
в Java осуществляется на уровне объектов. Т.е. внутри synchronized блока
блокируется данный экземпляр объекта. Метод, помеченный как synchronized,
осуществляет блокировку this объекта для методов экземпляра класса или
блокировку самого класса для статических методов. Т.е объявляя метод как
synchronized, мы говорим системе, что этот метод требует эксклюзивного доступа
к объекту. И система гарантирует, что из всех синхронизированных участков кода,
для каждого конкретного экземпляра объекта в каждый момент времени может
выполняться только один такой участок. При этом:
· Синхронизированный метод может выполняться параллельно
для разных объектов, например – метод withdraw может параллельно производить
операции с различными счетами.
· Для одного экземпляра запрещено параллельное
выполнение не только одного и того же синхронизированного метода, но и любых других
методов и синхронизированных блоков, использующих данный экземпляр объекта.
Например, если бы у нас в классе Account был синхронизированный метод deposit
(положить деньги на счёт), то и он бы не мог выполняться параллельно с методом
withdraw для данного счёта.
· Конструкция synchronized не препятствует параллельному
выполнению методов, не отмеченных как синхронизированные. Т.е., если бы в нашем
классе Account был метод deposit(), который мы забыли бы пометить как
synchronized, то он вполне мог выполняться параллельно с методом withdraw().
Причём, последствия могли бы быть не менее печальными, чем при выполнении двух
параллельных withdraw().
Итак, мы научились предотвращать
нежелательное влияние потоков друг на друга. Но этого ещё недостаточно. Часто хочется
уметь оповещать другой поток, например, о готовности данных для него. И,
соответственно, ждать прихода такого сообщения. Для этого в Java в классе
Object предусмотрены методы wait, notify, notifyAll. Для использования этих
методов поток должен быть эксклюзивным владельцем объекта, т.е. использовать
эти методы для this объекта внутри метода, объявленного как synchronized, или
внутри synchronized блока с этим объектом в качестве параметра. Эти методы
работают следующим образом:
· При выполнении метода wait система снимает блокировку
с объекта и переводит поток в режим ожидания.
· При выполнении метода notify система переводит в
точности один поток, ожидающий наступления данного события, в режим готовности.
Если такого потока нет, то выполнение этого метода не имеет никакого эффекта.
Следует заметить, что если наступления события ожидают несколько потоков, то
будет выбран любой из них. При этом, для возврата из метода wait, потоку
придётся конкурировать за доступ к данному объекту с другими потоками. Только
установив вновь эксклюзивную блокировку объекта, ожидающий поток может вновь
продолжить выполнение.
· При выполнении метода notifyAll пробуждаются все
потоки, ждущие наступления данного события.
Кажется не совсем понятным, зачем
требуется блокировать объект перед вызовом wait, чтобы потом wait снял эту
блокировку и пытался установить её вновь после получения уведомления. Но это
сделано для того, чтобы проверка условия и переход в режим ожидания выполнялись
атомарно (не делимым образом). Обычно поток, ожидающий наступления какого-то
события, проверяет переменную, связанную с этим событием. Если результат
проверки отрицательный, то поток переходит в режим ожидания. Например,
простейший класс "событие" (event), можно реализовать на Java
следующим образом:
class AutoResetEvent { // событие с автосбросом public synchronized void waitEvent() { try { while (!signaled) { // ждать наступления события wait();
}
signaled = false;
} catch (InterruptedException x) {} }
public synchronized void signalEvent() { signaled = true;
notify(); // пробудить спящий поток
}
private boolean signaled;
}
Обратите внимание, что проверка условия signaled делается
в цикле. Это необходимо, т.к., после того как signaled был установлен в true
методом signal и ждущий поток помещён в очередь готовых к выполнению процессов,
поток, вызвавший wait, ещё не стал владельцем блокировки объекта. Поэтому, если
в данный момент другой поток вызовет метод waitEvent, вполне может быть, что
именно он завладеет блокировкой и продолжит выполнение. Так как переменная
signaled имеет значение true, то этот поток не будет ждать, а сбросит signaled
в false и продолжит выполнение. А поток, выполнивший wait и завладевший наконец
блокировкой, обнаружит, что signaled сброшен. Поэтому он вынужден будет
выполнить ещё одну итерацию цикла и опять ждать наступления следующего события.
Следует также заметить, что метод wait снимает
блокировку только с одного объекта (а именно с того, для которого был позван
метод wait). Если вы заблокировали какие-либо еще объекты, то они так и
останутся заблокированными на время, пока поток находится в состоянии ожидания.
Возможно, вы того и хотели, но чаще всего это свидетельствует об ошибке в
программе. Для повышения степени параллелизма (и, соответственно,
производительности) и избежания тупиковых ситуаций следует устанавливать
блокировки на как можно более короткий срок. Следующий пример иллюстрирует проблему:
class MyClass { void synchronized foo(Object event) { synchronized(event) { wait(event);
}
}
}
В этом примере метод wait снимает блокировку с объекта
event, но собственный объект (this) остаётся заблокированным.
А вот пример реализации на Java события с ручным
(явным) сбросом:
class ManualResetEvent { // событие с автосбросом public synchronized void waitEvent() { try { while (!signaled) { // ждать наступления события wait();
}
} catch (InterruptedException x) {} }
public synchronized void resetEvent() { signaled = false;
}
public synchronized void signalEvent() { signaled = true;
notifyAll(); // пробудить все спящие потоки
}
private boolean signaled;
}
И еще один пример - реализация семафора на Java.
Семафор - это классический синхронизационный примитив, предложенный Э.В.
Дейкстрой, который можно использовать для распределения некоторого
ограниченного количества ресурсов. У классического семафора есть две операции
P(занять ресурс) и V(освободить ресурс). Операция P проверяет счётчик доступных
ресурсов и, если он больше нуля, то вычитает единицу и возвращает управление. В
противном случае поток, выполняющий операцию P, блокируется до тех пор, пока
счётчик не станет больше нуля. А операция V используется для оповещения о том,
что ресурс потоку больше не нужен. При этом счётчик доступных ресурсов
увеличивается на единицу.
class Semaphore { public synchronized void p() { while (counter == 0) { wait();
}
counter -= 1;
}
public synchronized void v() { counter += 1;
notify();
}
}
Реализация потоков в Java зависит от используемой
виртуальной машины. В некоторых случаях используется реализация потоков на
библиотечном уровне. То есть всё управление потоками осуществляется внутри
самой виртуальной машины без участия операционной системы. Такие потоки имеют
наименьшие накладные расходы, так как для переключения контекста не требуется
системных вызовов. Но такая реализация не позволяет использовать все имеющиеся
ресурсы на многопроцессорной машине и параллельно выполнять несколько потоков.
Кроме того, в большинстве случаев такая реализация использует не вытесняющую
стратегию для перепланировки потоков. То есть, для того, чтобы управление было
передано другому потоку, активный в данный момент поток должен сам захотеть
этого (например, вызов блокирующего системного метода приводит к тому, что
поток переводится в очередь ждущих потоков, а из очереди готовых к выполнению
потоков выбирается новый поток). Поэтому большинство текущих реализаций
виртуальных машин использует системные потоки (например, Win32 или pthread) для
реализации над ними потоков Java.
Вот, собственно, и всё - мы ознакомились с реализацией
параллелизма в Java! Простота конструкций, используемых в Java для управления
потоками, создаёт иллюзию, что написание многопоточных приложений ничуть не
сложнее написания обычных приложений: расставил всюду synchronized, вставил где
необходимо wait/notify, создал нужное количество потоков и всё - многопоточная
программа готова. По сравнения с библиотеками, используемыми, например, в С++
для создания и управления потоками, в Java всё кажется простым и понятным. К
сожалению, эта простота кажущаяся. Проблемы, возникающие при написании
параллельных программ, никуда не исчезли и ждут своего часа. Но об этом в
следующей главе.
Проблемы
написания параллельных программ.
Вернёмся немного назад. Как приходилось отлаживать
программы на С/C++? "Гуляющие указатели", не инициализированные
переменные, содержащие мусор, висящие ссылки и утечки памяти, не отлавливаемые
выходы индекса за границу массива… Программа "грохающаяся" в
непредсказуемом месте, потому что совсем в другом участке программы кто-то
неправильно обошёлся с указателем. Программа то работающая, то не работающая (в
зависимости от того, какой мусор встретился в памяти. Не даром для С++ создано
столько всяких СodeGuardов и BoundsCheckerов. После этого ошибки в программах
на языке Java кажутся чуть ли не самоустраняющимися - все переменные инициализированы,
выход индекса за границу массива отслеживается и пресекается мгновенно,
гуляющих и висячих указателей нет в принципе, как и утечек памяти. Программа
ведёт себе абсолютно детерминированным образом - если она
"сваливалась" на каком-то определённом наборе входных данных, то
можно быть уверенным, что, будучи запущенной ещё раз с тем же набором данных,
мы получим тот же самый результат. В общем, полное торжество защищённых
программных систем и языков.
Но вот мы написали многопоточную программу. И что мы
видим? Опять программа ведёт себя абсолютно непредсказуемым образом. Будучи
отлажена, оттестирована и запущена 1000 раз, на тысячу первый она ни с того ни
с сего виснет. Или ещё хуже - вдруг оказываются "испорченными"
данные. Попытка воспроизвести ошибку ни к чему не приводит - программа отлично
работает...до следующего падения. Случаются и не столь катастрофические, но не
менее загадочные явления - программа, прекрасно работающая на однопроцессорной
машине, на вдвое более мощной двухпроцессорной машине вдруг начинает работать
на порядок (десятичный, а не двоичный) медленнее, чем на однопроцессорной. В
общем, мы опять оказываемся в первобытном дремучем лесу отладки
недетерминировано работающей программы. С той лишь разницей, что продуктов типа
BoundsCheckerа для поиска ошибок в синхронизации очень мало, да и качество их
работы оставляет желать лучшего.
На самом деле, все ошибки, приводящие к неправильной
работе многопоточного приложения можно разбить на два класса: конкурентный
доступ (английский термин "race condition" не поддаётся разумному
переводу) и взаимные блокировки. Ошибки первого рода являются следствием
недостатка синхронизации, второго - её избытка (или неправильного применения).
С ошибками первого рода мы уже сталкивались - пример с
банковским счётом. Если два или больше потоков начинают одновременно изменять
(или даже один изменяет, а другой только смотрит) одни и те же данные, то
обычно ничего хорошего из этого не получается. Что же делать? Понаставить всюду
synchronized? Во-первых, тогда весь выигрыш от многопоточности может испариться
- если все объекты доступны только в эксклюзивном режиме, то работать в каждый
момент времени сможет только один поток. А во-вторых, чрезмерное и необдуманное
использование блокировок приводит к проблемам второго рода - тупиковым
ситуациям. Рассмотрим следующий пример:
class Pipe { // канал Queue src; // источник
Queue dst; // приёмник
void forward() { // переметить элемент из источника в приёмник synchronized(src) { // блокируем приёмник synchronized(dst) { // блокируем приёмник Object elem = src.dequeue(); // взять элемент из очереди src
dst.enqueue(elem); // и поместить в очередь dst
}
}
}
void backward() { // переместить элемент в обратном направлении – // из приёмника в источник
synchronized(dst) { // блокируем приёмник synchronized(src) { // блокируем приёмник Object elem = dst.dequeue(); // взять элемент из очереди dst
src.enqueue(elem); // и поместить в очередь src
}
}
}
}
Допустим, что с данным классом параллельно работают
несколько потоков. При этом возможен такой сценарий:
1. Поток П1 вызывает метод forward.
2. В потоке П1 выполняется первый synchronized оператор и
устанавливается блокировка src.
3. В результате перепланировки потоков управление
получает поток П2.
4. Поток П2 вызывает метод backward.
5. В результате выполнения метода backward в потоке П2
происходит блокирование объекта dst.
6. Попытка блокировать объект src не удаётся, так как
этот объект уже блокирован П1. Поток П2 переходит в режим ожидания.
7. Управление вновь получает П1 и пытается блокировать
dst. И эта попытка оканчивается неудачей, так как dst уже блокирован П2. Потоку
П1 ничего не остаётся, как ждать...потока П2, который в свою очередь ждёт П1.
Выйти из этой ситуации потоки не смогут. Поэтому она и зовётся тупиком.
В данном случае проблема решается достаточно просто:
нужно, чтобы метод backward блокировал объекты в том же порядке, что и метод
forward. Тупиковая ситуация при этом возникнуть не может. Этот простой прием,
кстати, является одним из самых основных способов предотвращения тупиковых
ситуаций - старайтесь всегда блокировать объекты в одном и том же порядке.
Можно также ассоциировать с объектами-ресурсами приоритеты, и блокировать
объекты в порядке убывания приоритета (иерархические блокировки). К сожалению,
тупиковую ситуацию можно получить, даже если у вас есть один единственный метод
с synchronized атрибутом. Рассмотрим следующий пример:
class SomeClass { void synchronized foo(SomeClass a) { ...
a.foo();
...
}
}
Теперь допустим, что у нас есть объекты класса
SomeClass о1 и о2 и два потока П1 и П2, параллельно выполняющие следующие
вызовы:
П1: o1.foo(o2);
П2: o2.foo(o1);
C большой вероятностью этот код приведёт к взаимной
блокировке: П1 блокирует о1, П2 блокирует о2 и оба будут ждать друг друга).
Что же делать? Как научиться определять возможные
блокировки и пытаться избегать их? К сожалению, Java компилятор нам тут ничем
не поможет. Придётся брать в руки карандаш и бумагу (кто там говорил о скорой
кончине последней?) и начинать рисовать граф блокировок. Вершинам в этом графе
соответствуют объекты, которые могут быть заблокированы (объект синхронизации в
synchronized блоке или экземпляр класса для synchronized метода). Конечно, этих
объектов может быть неопределённо много (например, в случае synchronized
метода, каждый экземпляр объекта данного класса может быть заблокирован). Для
начала, представим все экземпляры класса одной вершиной. Итак, вершины мы
нарисовали. Теперь внимательно изучаем код и ищем зависимости между объектами.
Для этого строим граф вызовов, т.е. определяем, какие другие методы может
позвать данный метод. Нужно построить замыкание этого отношения (т.е. иными
словами учесть не только те методы, которые могут быть непосредственно позваны,
но и методы, которые позовут эти методы, и.т.д.) Не забудьте учесть
наследование - в общем случае вызов метода базового класса или интерфейса может
привести к вызову метода любого выведенного класса, переопределяющего или
реализующего данный метод. Граф вызовов для большой программы может получиться
просто непотребно большим, поэтому лучше его не рисовать явно, а строить в уме.
Но тут главное никого не забыть. После того, как мы выяснили, кто кого может
позвать, проводим рёбра в нашем графе блокировок. Если внутри участка кода,
блокировавшего объект "x", блокируется объект "y" или
вызывается метод, который в свою очередь блокирует объект "y", то от
вершины, помеченной "x", мы проводим ребро в вершину помеченную
"y". Провели? Ну, значит, дело почти сделано. Теперь изучаем наш граф
и ищем в нём циклы. Не нашли - поздравляю: возникновение тупиковой ситуации в
вашей программе невозможно (если вы, конечно, не напутали что-то с графом).
Нашли? - ну тут возможны варианты. Помните, что мы все экземпляры данного
класса пометили одной единственной вершиной? Может так оказаться, что цикл,
существующей в нашем графе на самом деле невозможен, потому что блокируются
различные экземпляры объектов. Тут уже нужно более тонкое изучение,
использующее семантику конкретной программы.
Ещё необходимо заметить, что реализовать описанный
выше алгоритм не так просто, как кажется на первый взгляд. Для этого надо
построить не просто граф вызовов, а контекстно-зависимый граф вызовов. А это в
большом проекте может занять слишком много памяти и времени. Кроме того, из-за
представления в графе всех экземпляров объектов одной вершиной, достаточно
велик процент "белого шума" - т.е. ложных сообщений о блокировках,
что делает даже анализ найденных циклов для большого проекта нетривиальной
задачей.
К счастью, в отличие от конкурентного доступа,
тупиковая ситуация (будучи воспроизведённой под отладчиком), хорошо поддаётся
анализу. Просто смотрим список "застрявших" потоков, изучаем стек
вызова каждого такого потока и определяем, какие объекты данный поток
блокировал и какие пытается заблокировать. После чего надо только понять, как
разрушить цикл.
К сожалению, для поиска ошибок связанных с
конкурентным доступом сложно дать какие-то рекомендации. Очевидно, что каждые
разделяемые и изменяемые данные должны быть защищены от конкурентного доступа.
Но как именно это сделать - решать программисту. Как обнаружить места, где это
забыли сделать или сделали неправильно? Могу предложить только очень общий
способ. Очевидно, что синхронизация имеет смысл только в том случае, если все
потоки используют для синхронизации одни и те же объекты. Если поток П1 для
обращения к объекту o блокировал объект m1, а поток П2 для обращения к тому же
объекту о использует блокировку другого объекта m2, то ничего хорошего от такой
"синхронизации" не получится. Поэтому можете попробовать для каждого
совместно используемого объекта или переменной определить объект, который
отвечает за синхронизацию доступа к нему. Если у вас получилось больше одного
синхронизирующего объекта для какого-то совместно используемого элемента - то,
скорее всего, тут ошибка. И ещё одна рекомендация по воспроизведению ошибок.
Хотя, как мы уже говорили, даже на однопроцессорной машине поток может быть
прерван в любой момент и поэтому возможно параллельное выполнение почти любых
операторов (если только они не находятся в критической секции), на
многопроцессорной машине вероятность этого значительно больше. Кроме того, тут
так же сказывается параллелизм на уровне инструкций - инструкции, который могли
рассматриваться как атомарные в однопроцессорной конфигурации, перестают быть
такими в многопроцессорной системе. Поэтому постарайтесь прогнать свою
программу на многопроцессорной системе - возможно гораздо быстрее наткнётесь на
скрытые ошибки. Кроме того, при прогоне на многопроцессорной машине могут
проявиться проблемы с падением производительности, вызванные конфликтами
блокировок разных потоков. В этом случае придётся либо менять схему блокировок,
либо изменять распределение данных между потоками, чтобы свести к минимуму
использование глобальных (разделяемых) данных, доступ к которым требует
синхронизации.
Проблема
остановки потока.
Как мы уже видели, запуск потока в Java не представляет
собой проблемы – достаточно создать объект Thread и позвать метод start.
Однако, оказывается, что, запустив поток на выполнение, его не так-то просто
остановить. Хотя метод stop в классе Thread есть, но он помечен как deprecated
(устаревший). Т.е. пользоваться им настоятельно не рекомендуется. И на то есть
веские причины. Дело в том, что поток, остановленный в произвольный момент
времени, может оставить в некорректном состоянии системные ресурсы. Например,
если поток был владельцем каких либо блокировок, то эти объекты так и окажутся
не разблокированными. Что же делать, если «убивать» поток нельзя? Надо
заставить его совершить «харакири» - т.е. завершиться добровольно. Для этого в
потоках, которые выполняют некоторое циклическое действие, в условие цикла надо
поставить проверку того, что потоку не пора завершать работу.
Например:
class MyThread extends Thread { boolean running = true;
public void run() { while (running) { ... // делаем что-то
}
}
}
Однако обычно поток не только производит вычисления,
но и совершает операции ввода/вывода. Соответственно очень часто поток
блокирован в результате выполнения системного вызова, который не может быть
выполнен мгновенно – например, read. Чтобы заставить такой поток закончить
выполнение, надо воспользоваться методом interrupt() класса Thread. Если поток
был блокирован во время выполнения метода Object.wait(), то в потоке будет
инициирована исключительная ситуация InterruptedException. Если поток выполнял
блокирующую операцию ввода/вывода, то выполнение операции будет прервано c
помощью исключительной ситуации java.nio.channels.ClosedByInterruptException.
При этом всё равно полезно использовать флаг остановки, чтобы отличать
ситуацию, когда операция прервана в результате ошибки ввода/вывода и когда
причина – остановка потока.
Иногда в потоке стоит задержка выполнения на некоторое
время. В классе Thread имеется метод Sleep, который "усыпляет" поток
на заданное время в миллисекундах. Но если поток нужно будет останавливать, то
более правильным представляется использование метода Object.wait с задержкой. В
этом случае объекту можно послать уведомление, чтобы прервать его сон:
class MyThread extends Thread { boolean running = true;
Object timer = new Object();
static final int DELAY=1000; // одна секунда
public void run() { while (running) { ... // делаем что-то
synchronized(timer) { try { timer.wait(DELAY); // ждём заданное время,
// либо сигнала о завершении
} catch (InterruptedException x) {} }
}
}
public void terminate() { synchronized(timer) { running = false; // устанавливаем флаг завершения
timer.notify(); // и посылаем сигнал, чтобы пробудить спящий процесс.
}
}
}
Хотя поток и является более легковесным ресурсом, чем
процесс (т.е. создание и переключение потоков требует меньше времени и памяти),
но всё равно создание потока достаточно сложная операция, особенно в операционных
системах, поддерживающих потоки на уровне ядра (а только в этом случае можно
получить выигрыш от использования параллельных потоков на многопроцессорной
машине). Поэтому, если программе необходимо периодически выполнять какие-то
параллельные действия, неэффективно каждый раз создавать новый поток. Вместо
этого лучше завести пул потоков. Идея очень проста: вместо того, чтобы каждый
раз создавать новый поток, а потом его завершать, мы заводим некоторое число
готовых потоков, которые ждут момента, когда они понадобятся. После выполнения
работы поток не завершается, а опять попадает в список свободных потоков и ждёт
следующего задания. Посмотрим, как это можно реализовать:
/**
* Пул потоков
*/
public class ThreadPool { /**
* Получить экземпляр пула потоков
*/
public static ThreadPool getInstance() { return theInstance;
}
/**
* Поток для повторного использования
*/
static class PooledThread extends Thread { PooledThread next;
Object ready; // объект, используемый для ожидания нового задания
Object done; // объект, используемый для сигнализации завершения работы
boolean busy; // флажок отмечающий, что поток занят
boolean doneNotificationNeeded; // ждёт ли кто-нибудь завершения работы
Runnable task; // что нужно сделать
ThreadPool pool; // пул потоков
public void run() { try { synchronized(ready) { // блокируем ready – готовимся к ожиданию работы while (!pool.closed) { // проверяем не закрыт ли пул synchronized(done) { // блокировка ready busy = false; // мы закончили работу, начатую на предыдущей
// итерации цикла
if (doneNotificationNeeded) { // если кто-то ждёт завершения работы… done.notify();// то пошлём уведомление, что мы её закончили
}
}
ready.wait(); // ждём нового задания
if (task != null) { // если мы его получили… task.run(); // то выполняем
} else { break; // иначе завершаем работу
}
}
}
} catch (InterruptedException x) {} }
final void wakeUp(Runnable t) { // запустить задание на выполнение synchronized(ready) { // блокировать readу, чтобы можно было послать уведомление busy = true; // установить флаг занятости
doneNotificationNeeded = false;
task = t;
ready.notify(); // послать уведомление свободному потоку
}
}
final void waitCompletion() throws InterruptedException { synchronized(done) { // блокировать done для ожидания if (busy) { // если задание ещё не завершилось… doneNotificationNeeded = true; // то поставить флаг ожидания завершения
done.wait(); // и подождать
}
}
}
PooledThread(ThreadPool pool) { this.pool = pool;
ready = new Object();
done = new Object();
busy = true;
setDaemon(true); // запускаем поток как демона, чтобы не ждать его завершения
// при выходе из программы
this.start();
}
}
/**
* Найти свободный поток и запустить в нём задание на выполнение
* @param task объект реализующий интерфейс Runnable,
* метод run которого будет выполнен потоком
* @return поток, выделенный для данного задания
* (его можно использовать только в методе ThreadPool.join)
*/
public Thread start(Runnable task)
{ PooledThread thread;
synchronized (this) { // для работы со списком нужна блокировка while (availableThreadList == null) { // если список свободных потоков пуст try { if (nActiveThreads == maxThreads) { // и если достигнуто ограничение на // максимальное число потоков
deficit += 1; // то отметить, что есть задачи, ждущие выполнения
wait(); // и подождать пока какой-нибудь из потоков не освободится
} else { availableThreadList = new PooledThread(this); // создать новый поток
availableThreadList.waitCompletion(); // и дождаться момента,
// когда он стартует и будет
// готов к получению задания
}
} catch (InterruptedException x) { return null;
}
}
thread = availableThreadList; // взять поток из списка свободных
availableThreadList = thread.next;
nActiveThreads += 1; // увеличит счётчик активных потоков
}
thread.wakeUp(task); // запустить задание на выполнение
return thread;
}
/**
* Дождаться завершения задания. Поток при этом возвращается в список свободных
* @param thread поток, возвращённый методом ThreadPool.start
*/
public void join(Thread thread) throws InterruptedException
{ PooledThread t = (PooledThread)thread;
t.waitCompletion(); // дождаться завершения задания
synchronized (this) { // для работы со списком нужна блокировка t.next = availableThreadList; // добавить поток в список свободных
availableThreadList = t;
nActiveThreads -= 1; // уменьшить значение счётчика активных потоков
if (deficit > 0) { // если есть потоки ждущие уведомления… notify(); // то послать уведомление о том, что поток освободился
deficit -= 1;
}
}
}
/**
* Закрытие пула потоков. Подождать окончания работы всех активных потоков и
* завершить все свободные потоки
*/
public synchronized void close()
{ closed = true; // ставим флаг прекращения работы
while (nActiveThreads > 0) { // пока есть активные потоки try { deficit += 1; // мы нуждаемся в уведомлении о завершении потока
wait(); // ждём уведомления
} catch (InterruptedException x) {} }
while (availableThreadList != null) { // пока список свободных потоков не пуст availableThreadList.wakeUp(null); // потоку запрос на завершение
availableThreadList = availableThreadList.next; // и исключаем его из списка
}
}
/**
* Конструктор пула потоков с ограничением на максимальное число активных потоков
* @param maxThreads максимальное число одновременно работающих потоков.
*/
public ThreadPool(int maxThreads) { this.maxThreads = maxThreads;
}
/**
* Конструктор пула потоков с неограниченным числом потоков
*/
public ThreadPool() { this(Integer.MAX_VALUE);
}
PooledThread availableThreadList; // список свободных потоков
int nActiveThreads; // число активных потоков
int deficit; // количество потоков, заинтересованных в получении
// уведомления о завершении работы
int maxThreads; // ограничение на максимальное число одновременно
// работающих потоков
boolean closed; // флаг прекращения работы
static ThreadPool theInstance = new ThreadPool();
}
Обратите внимание в этом примере на то, что
уведомления посылаются не всегда, а только тогда, когда их кто-то ждёт.
Подобная оптимизация с использованием дополнительной переменной позволяет
избежать лишних вызовов notify.
Практические
примеры использования потоков.
Рассмотрим использование потоков в реальных и
достаточно простых приложениях. Рассмотрим примеры приложений под J2ME (Java
для мобильных и встроенных устройств) по причине исключительной простоты MIDP
интерфейса. Но способы работы с потоками в J2ME ничем не отличаются от других
платформ Java.
Итак, первый пример. Допустим, мы реализуем научный
калькулятор, который должен уметь рисовать графики функций. Для этого мы должны
вычислить значение функции во всех точках указанного интервала с заданным шагом.
Их может быть довольно много, а вычисление функции (особенно на слабеньком
процессоре мобильного телефона), может занимать много времени. С другой
стороны, пока мы не вычислили значение функции для всех точек, мы не сможем
определить максимум и минимум функции на этом интервале и вычислить коэффициент
для вертикального масштабирования графика функции (чтобы график поместился на
экран). Конечно, можно просто вывести на экран "Подождите
минуточку..." и заняться вычислениями. Но это не очень хорошее решение:
· Во-первых пользователь не может прервать процесс
вычислений (допустим вам в это время звонят, а у вас телефон занят
вычислениями).
· Во-вторых пользователь не знает сколько ещё времени
ему осталось ждать (если бы он знал, что график будут построен только через
час, он бы давно остановил работу и задал другой интервал или шаг).
Посмотрим, как это можно сделать. Ясно, что вычисление
функции должно производится независимо от работы остальной программы. То есть
нам нужен поток:
import javax.microedition.lcdui.*;
import javax.microedition.midlet.*;
public class Plot extends Form implements CommandListener, Runnable
{ Calculator calculator;
Gauge progressIndicator; // "градусник"
StringItem completed; // а сюда мы будем записывать строчку с процентом выполнения
Float from; // начальная точка
Float till; // конечная точка
Float dx; // шаг
Float[] values; // сюда мы будем заносить вычисленные значения функции
int percent; // процент выполнения
Thread thread; // поток, в котором будет всё делаться
boolean running; // флажок нужный для "аварийной" остановки потока
Compiler.FunctionExpression f; // вычисляемая функция
Plot(Calculator calculator, Compiler.PlotExpression expr, int screenWidth) { super("Plot"); this.calculator = calculator;
from = expr.from.evaluate(calculator.bindings);
till = expr.till.evaluate(calculator.bindings);
dx = expr.step != null
? expr.step.evaluate(calculator.bindings)
: till.Sub(from).Div(screenWidth);
f = expr.f;
int n = (int)till.Sub(from).Div(dx).toLong() + 1;
if (n < 2) { calculator.showAlert(AlertType.ERROR, "Error", "Bad interval");
return;
}
values = new Float[n];
i = 0;
x = from;
progressIndicator = new Gauge("Progress indicator", false, n, 0); completed = new StringItem("Completed:", "0%"); append(progressIndicator);
append(completed);
setCommandListener(this);
addCommand(Calculator.STOP_CMD);
Display.getDisplay(calculator).setCurrent(this);
running = true;
thread = new Thread(this);
thread.start(); // запускаем
}
public void run() { try { Float x = from;
// проверяем флажок running, чтобы остановить работу потока при выполнении команды STOP
for (int i = 0, n = values.length; running && i < n; i++) { f.arguments[0] = x;
// вычисляем значение функции в очередной точке
values[i] = f.evaluate(calculator.bindings);
int newPercent = i*100/n;
// оптимизация: обновляем индикаторы прогресса только при изменении процента выполнения
if (newPercent != percent) { progressIndicator.setValue(i);
percent = newPercent;
completed.setText(Integer.toString(newPercent) + '%');
}
x = x.Add(dx);
}
} catch (CompileError x) { calculator.showAlert(AlertType.ERROR, "Error", x.getMessage());
return;
}
if (running) { // рисуем график, только если не была выполнена команда Stop
new Graph(calculator, from, till, values);
}
}
public void commandAction(Command c, Displayable d) { if (c == Calculator.STOP_CMD) { // устанавливаем флажок для завершения потока
running = false;
Display.getDisplay(calculator).setCurrent(calculator.mainMenu);
}
}
}
Теперь рассмотрим пример написания простейшей игрушки.
Допустим, у нас должен кто-то (для определённости назовём его НЛО) перемещаться
по экрану с заданной скоростью. Рисование в MIDP выполняется в переопределённом
методе paint(Graphics g) класса Canvas. Чтобы инициировать его выполнения нужно
с помощью метода repaint попросить систему перерисовать какую-то область экрана
(или весь экран). Т.е. если у нас НЛО ползёт по экрану, нужно попросить
перерисовать прямоугольник, в котором находится НЛО. Дальше мы стираем старый
образ НЛО, вычисляем его новые координаты и рисуем его на новом месте. Осталась
самая малость - кто-то должен периодически (с периодом определяемым скоростью
движения НЛО) вызывать метод repaint. Можно конечно для этого завести поток, но
к счастью есть и более простое решение - использовать класс Timer:
import javax.microedition.lcdui.*;
import java.util.Timer;
import java.util.TimerTask;
public class GameCanvas extends Canvas implements CommandListener { class GameTask extends TimerTask { public void run() { repaint(); // запрос на перерисовку
}
}
GameCanvas(Game game) { // вычисляем интервал перерисовки (скорость движения НЛО) в зависимости от уровня
delay = MAX_DELAY - game.settings.level*MAX_DELAY/Settings.LEVELS;
// создаём таймер
timer = new Timer();
// и объект котрый будет запускаться таймером
task = new GameTask();
...
}
// запустить игру
void start() { // запускаем таймер (с нулевой задержкой и заданным интервалом в миллисекундах)
timer.schedule(task, 0, delay);
}
// приостановить игру
void stop() { // остановить таймер
timer.cancel();
}
...
static final long MAX_DELAY = 1000;
GameTask task;
Timer timer;
long delay;
}
Следует заметить, что внутри таймер реализован с
помощью потока, который осуществляет задержку с помощью метода wait(long delay).
Реализация
многопоточности в Java.
Для реализации многопоточности
должны воспользоваться классом java.lang.Thread. В этом классе определены все
методы, необходимые для создания потоков, управления их состоянием и
синхронизации.
Как пользоваться классом Thread?
Есть две возможности.
· Во-первых, вы можете создать свой дочерний класс на
базе класса Thread. При этом вы должны переопределить метод run. Ваша
реализация этого метода будет работать в рамках отдельного потока.
· Во-вторых, ваш класс может реализовать интерфейс
Runnable. При этом в рамках вашего класса необходимо определить метод run,
который будет работать как отдельный поток.
Второй способ особенно
удобен в тех случаях, когда ваш класс должен быть унаследован от какого-либо
другого класса (например, от класса Applet) и при этом вам нужна
многопоточность. Так как в языке программирования Java нет множественного
наследования, невозможно создать класс, для которого в качестве родительского
будут выступать классы Applet и Thread. В этом случае реализация интерфейса
Runnable является единственным способом решения задачи.
В классе Thread определены три поля, несколько
конструкторов и большое количество методов, предназначенных для работы с потоками.
Ниже мы привели краткое описание полей, конструкторов и методов.
С помощью конструкторов вы можете создавать потоки
различными способами, указывая при необходимости для них имя и группу. Имя
предназначено для идентификации потока и является необязательным атрибутом. Что
же касается групп, то они предназначены для организации защиты потоков друг от
друга в рамках одного приложения.
Методы класса Thread
предоставляют все необходимые возможности для управления потоками, в том числе
для их синхронизации.
Поля.
Три статических поля
предназначены для назначения приоритетов потокам.
· NORM_PRIORITY
Нормальный
public final static int NORM_PRIORITY;
· MAX_PRIORITY
Максимальный
public final static int MAX_PRIORITY;
· MIN_PRIORITY
Минимальный
public final static int MIN_PRIORITY;
Конструкторы.
Создание нового объекта Thread
public Thread();
Создвание нового объекта Thread с указанием объекта,
для которого будет вызываться метод run
public Thread(Runnable target);
Аналогично предыдущему, но дополнительно задается имя
нового объекта Thread
public Thread(Runnable target, String name);
Создание объекта Thread с указанием его имени
public Thread(String name);
Создание нового объекта Thread с указанием группы
потока и объекта, для которого вызывается метод run
public Thread(ThreadGroup group,
Runnable target);
Аналогично предыдущему, но дополнительно задается имя
нового объекта Thread
public Thread(ThreadGroup group,
Runnable target, String name);
Создание нового объекта Thread с указанием группы
потока и имени объекта
public Thread(ThreadGroup group, String name);
Методы
· activeCount
Текущее количество активных потоков в группе, к
которой принадлежит поток
public static int activeCount();
· checkAccess
Текущему потоку разрешается изменять объект Thread
public void checkAccesss();
· countStackFrames
Определение количества фреймов в стеке
public int countStackFrames();
· currentThread
Определение текущего работающего потока
public static Thread currentThread();
· destroy
Принудительное завершение работы потока
public void destroy();
· dumpStack
Вывод текущего содержимого стека для отладки
public static void dumpStack();
· enumerate
Получение всех объектов Tread данной группы
public static int enumerate(Thread tarray[]);
· getName
Определение имени потока
public final String getName();
· getPriority
Определение текущего приоритета потока
public final int getPriority();
· getThreadGroup
Определение группы, к которой принадлежит поток
public final ThreadGroup getThreadGroup();
· interrupt
Прерывание потока
public void interrupt();
· interrupted
Определение, является ли поток прерванным
public static boolean interrupted();
· isAlive
Определение, выполняется поток или нет
public final boolean isAlive();
· isDaemon
Определение, является ли поток демоном
public final boolean isDaemon();
· isInterrupted
Определение, является ли поток прерванным
public boolean isInterrupted();
· join
Ожидание завершения потока
public final void join();
Ожидание завершения потока в течение заданного
времени. Время задается в миллисекундах
public final void join(long millis);
Ожидание завершения потока в течение заданного времени.
Время задается в миллисекундах и наносекундах
public final void join(long millis, int nanos);
· resume
Запуск временно приостановленного потока
public final void resume();
· run
Метод вызывается в том случае, если поток был создан как
объект с интерфейсом Runnable
public void run();
· setDaemon
Установка для потока режима демона
public final void setDaemon(boolean on);
· setName
Устаовка имени потока
public final void setName(String name);
· setPriority
Установка приоритета потока
public final void setPriority(int newPriority);
· sleep
Задержка потока на заднное время. Время задается в
миллисекундах и наносекундах
public static void sleep(long millis);
Задержка потока на заднное время. Время задается в
миллисекундах и наносекундах
public static void sleep(long millis, int nanos);
· start
Запуск потока на выполнение
public void start();
· stop
Остановка выполнения потока
public final void stop();
Аварийная остановка выполнения потока с заданным
исключением
public final void stop(Throwable obj);
· suspend
Приостановка потока
public final void suspend();
· toString
Строка, представляющая объект-поток
public String toString();
· yield
Приостановка текущего потока для того чтобы управление было передано другому потоку
public static void yield();
Создание
дочернего класса на базе класса Thread.
Рассмотрим первый способ реализации многопоточности,
основанный на наследовании от класса Thread. При использовании этого способа вы
определяете для потока отдельный класс, например, так:
class DrawRectangles extends Thread
{ . . .
public void run()
{ . . .
}
}
Здесь определен класс DrawRectangles, который является
дочерним по отношению к классу Thread.
Обратите внимание на метод run. Создавая свой класс на
базе класса Thread, вы должны всегда определять этот метод, который и будет
выполняться в рамках отдельного потока.
Заметим, что метод run не вызывается напрямую никакими
другими методами. Он получает управление при запуске потока методом start.
Как это происходит?
Рассмотрим процедуру запуска потока на примере
некоторого класса DrawRectangles.
Вначале ваше приложение должно создать объект класса
Thread:
public class MultiTask2 extends Applet
{ Thread m_DrawRectThread = null;
. . .
public void start()
{ if (m_DrawRectThread == null)
{ m_DrawRectThread = new DrawRectangles(this);
m_DrawRectThread.start();
}
}
}
Создание объекта выполняется оператором new в методе start,
который получает управление, когда пользователь открывает документ HTML с
аплетом. Сразу после создания поток запускается на выполнение, для чего
вызывается метод start.
Что касается метода run, то если поток используется
для выполнения какой либо периодической работы, то этот метод содержит внутри
себя бесконечный цикл. Когда цикл завершается, и метод run возвращает
управление, поток прекращает свою работу нормальным, не аварийным образом. Для
аварийного завершения потока можно использовать метод interrupt.
Остановка работающего потока выполняется методом stop.
Обычно остановка всех работающих потоков, созданных аплетом, выполняется
методом stop класса аплета:
public void stop()
{ if (m_DrawRectThread != null)
{ m_DrawRectThread.stop();
m_DrawRectThread = null;
}
}
Напомним, что этот метод вызывается, когда
пользователь покидает страницу сервера Web, содержащую аплет.
Описанный выше способ создания потоков как объектов класса
Thread или унаследованных от него классов кажется достаточнао естественным.
Однако этот способ не единственный. Если вам нужно создать только один поток,
работающую одновременно с кодом аплета, проще выбрать второй способ с
использованием интерфейса Runnable.
Идея заключается в том, что основной класс аплета,
который является дочерним по отношению к классу Applet, дополнительно реализует
интерфейс Runnable, как это показано ниже:
public class MultiTask extends
Applet implements Runnable
{ Thread m_MultiTask = null;
. . .
public void run()
{ . . .
}
public void start()
{ if (m_MultiTask == null)
{ m_MultiTask = new Thread(this);
m_MultiTask.start();
}
}
public void stop()
{ if (m_MultiTask != null)
{ m_MultiTask.stop();
m_MultiTask = null;
}
}
}
Внутри класса необходимо определить метод run, который
будет выполняться в рамках отдельного потока. При этом можно считать, что код
аплета и код метода run работают одновременно как разные потоки.
Для создания потока используется оператор new. Поток
создается как объект класса Thread, причем конструктору передается ссылка на
класс аплета:
m_MultiTask = new Thread(this);
При этом, когда поток запустится, управление получит
метод run, определенный в классе аплета.
Как запустить поток?
Запуск выполняется, как и раньше, методом start.
Обычно поток запускается из метода start аплета, когда пользователь отображает
страницу сервера Web, содержащую аплет. Остановка потока выполняется методом
stop.
Синхронизация
потоков.
Рассмотрим методы синхронизации потоков одного или
нескольких процессов. Все методы основаны на создании специальных объектов синхронизации.
Эти объекты характеризуются состоянием. Различают сигнальное и несигнальное
состояние. В зависимости от состояния объекта синхронизации один поток может
узнать об изменении состояния других потоков или общих (разделяемых) ресурсов.
Небольшое замечание: функция _beginthread,
используемая в примерах, может быть заменена соответствующим эквивалентом MFC
(AfxBeginThread) или аналогичной в других диалектах языка С.
Первый пример иллюстрирует работу с несинхронизированными
потоками. Основной цикл, который является основным потоком процесса, выводит на
экран содержимое глобального массива целых чисел. Поток, названный
"Thread", непрерывно заполняет глобальный массив целых чисел:
#include <process.h>
#include <stdio.h>
int a[ 5 ];
void Thread( void* pParams )
{ int i, num = 0;
while ( 1 )
{ for ( i = 0; i < 5; i++ ) a[ i ] = num;
num++;
}
}
int main( void )
{ _beginthread( Thread, 0, NULL );
while( 1 )
printf("%d %d %d %d %d\n", a[ 0 ], a[ 1 ], a[ 2 ],
a[ 3 ], a[ 4 ] );
return 0;
}
Как видно из результата работы процесса, основной
поток (сама программа) и поток Thread действительно работают параллельно (красным
цветом обозначено состояние, когда основной поток выводит массив во время его
заполнения потоком Thread):
81751652 81751652 81751651 81751651 81751651
81751652 81751652 81751651 81751651 81751651
83348630 83348630 83348630 83348629 83348629
83348630 83348630 83348630 83348629 83348629
83348630 83348630 83348630 83348629 83348629
Запустите программу, затем нажмите "Pause"
для остановки вывода на дисплей (т.е. приостанавливаются операции ввода/вывода
основного потока, но поток Thread продолжает свое выполнение в фоновом режиме)
и любую другую клавишу для возобновления выполнения.
А что делать, если основной поток должен читать данные
из массива после его обработки в параллельном процессе? Одно из решений этой
проблемы - использование критических секций.
Критические секции обеспечивают синхронизацию подобно мьютексам (о мьютексах см. далее) за
исключением того, что объекты, представляющие критические секции, доступны в
пределах одного процесса. События, мьютексы и семафоры также можно использовать
в "однопроцессном" приложении, однако критические секции обеспечивают
более быстрый и более эффективный механизм взаимно-исключающей синхронизации.
Подобно мьютексам объект, представляющий критическую секцию, может использоваться
только одним потоком в данный момент времени, что делает их крайне полезными
при разграничении доступа к общим ресурсам. Трудно предположить что-нибудь о
порядке, в котором потоки будут получать доступ к ресурсу, можно сказать лишь,
что система будет "справедлива" ко всем потокам:
#include <windows.h>
#include <process.h>
#include <stdio.h>
CRITICAL_SECTION cs;
int a[ 5 ];
void Thread( void* pParams )
{ int i, num = 0;
while ( TRUE )
{ EnterCriticalSection( &cs );
for ( i = 0; i < 5; i++ ) a[ i ] = num;
LeaveCriticalSection( &cs );
num++;
}
}
int main( void )
<!--[if !supportLineBreakNewLine]-->
<!--[endif]-->
{ InitializeCriticalSection( &cs );
_beginthread( Thread, 0, NULL );
while( TRUE )
{ EnterCriticalSection( &cs );
printf( "%d %d %d %d %d\n",
a[ 0 ], a[ 1 ], a[ 2 ],
a[ 3 ], a[ 4 ] );
LeaveCriticalSection( &cs );
}
return 0;
}
Мьютекс (взаимоисключение, mutex) - это объект
синхронизации, который устанавливается в особое сигнальное состояние, когда не
занят каким-либо потоком. Только один поток владеет этим объектом в любой
момент времени, отсюда и название таких объектов - одновременный доступ к
общему ресурсу исключается. Например, чтобы исключить запись двух потоков в
общий участок памяти в одно и то же время, каждый поток ожидает, когда
освободится мьютекс, становится его владельцем и только потом пишет что-либо в
этот участок памяти. После всех необходимых действий мьютекс освобождается,
предоставляя другим потокам доступ к общему ресурсу.
Два (или более) процесса могут создать мьютекс с одним
и тем же именем, вызвав метод CreateMutex . Первый процесс действительно
создает мьютекс, а следующие процессы получают хэндл уже существующего объекта.
Это дает возможность нескольким процессам получить хэндл одного и того же
мьютекса, освобождая программиста от необходимости заботиться о том, кто в
действительности создает мьютекс. Если используется такой подход, желательно
установить флаг bInitialOwner в FALSE, иначе возникнут определенные
трудности при определении действительного создателя мьютекса.
Несколько процессов могут получить хэндл одного и того
же мьютекса, что делает возможным взаимодействие между процессами. Вы можете
использовать следующие механизмы такого подхода:
<!--[if
!supportLists]-->· <!--[endif]-->Дочерний
процесс, созданный при помощи функции CreateProcess может наследовать хэндл
мьютекса в случае, если при его (мьютекса) создании функией CreateMutex был
указан параметр lpMutexAttributes .
<!--[if
!supportLists]-->· <!--[endif]-->Процесс
может получить дубликат существующего мьютекса с помощью функции
DuplicateHandle .
<!--[if !supportLists]-->· <!--[endif]-->Процесс
может указать имя существующего мьютекса при вызове функций OpenMutex или
CreateMutex .
Вообще говоря, если вы синхронизируете потоки одного
процесса, более эффективным подходом является использование критических секций:
#include <windows.h>
#include <process.h>
#include <stdio.h>
HANDLE hMutex;
int a[ 5 ];
void Thread( void* pParams )
{ int i, num = 0;
while ( TRUE )
{ WaitForSingleObject( hMutex, INFINITE );
for ( i = 0; i < 5; i++ ) a[ i ] = num;
ReleaseMutex( hMutex );
num++;
}
}
int main( void )
{ hMutex = CreateMutex( NULL, FALSE, NULL );
_beginthread( Thread, 0, NULL );
while( TRUE )
<!--[if !supportLineBreakNewLine]-->
<!--[endif]-->
{ WaitForSingleObject( hMutex, INFINITE );
printf( "%d %d %d %d %d\n",
a[ 0 ], a[ 1 ], a[ 2 ],
a[ 3 ], a[ 4 ] );
ReleaseMutex( hMutex );
}
return 0;
}
А что, если мы хотим, чтобы в предыдущем примере
второй поток запускался каждый раз после того, как основной поток закончит
печать содержимого массива, т.е. значения двух последующих строк будут
отличаться строго на 1?
Событие - это объект синхронизации, состояние которого
может быть установлено в сигнальное путем вызова функций SetEvent или
PulseEvent . Существует два типа событий:
|
Тип объекта
|
Описание
|
|
Событие с ручным
сбросом
|
Это объект,
сигнальное состояние которого сохраняется до ручного сброса функцией
ResetEvent . Как только состояние объекта установлено в сигнальное, все
находящиеся в цикле ожидания этого объекта потоки продолжают свое выполнение
(освобождаются).
|
|
Событие с
автоматическим сбросом
|
Объект,
сигнальное состояние которого сохраняется до тех пор, пока не будет
освобожден единственный поток, после чего система автоматически устанавливает
несигнальное состояние события. Если нет потоков, ожидающих этого события,
объект остается в сигнальном состоянии.
|
События полезны в тех случаях, когда необходимо
послать сообщение потоку, сообщающее, что произошло определенное событие.
Например, при асинхронных операциях ввода и вывода из одного устройства, система
устанавливает событие в сигнальное состояние, когда заканчивается какая-либо из
этих операций. Один поток может использовать несколько различных событий в
нескольких перекрывающихся операциях, а затем ожидать прихода сигнала от любого
из них.
Поток может использовать функцию CreateEvent для
создания объекта события. Создающий событие поток устанавливает его начальное
состояние. В создающем потоке можно указать имя события. Потоки других
процессов могут получить доступ к этому событию по имени, указав его в функции
OpenEvent .
Поток может использовать функцию PulseEvent для
установки состояния события в сигнальное и затем сбросить состояние в
несигнальное после освобождения соответствующего количества ожидающих потоков.
В случае объектов с ручным сбросом освобождаются все ожидающие потоки. В случае
объектов с автоматическим сбросом освобождается только единственный поток, даже
если этого события ожидают несколько потоков. Если ожидающих потоков нет,
PulseEvent просто устанавливает состояние события в несигнальное:
#include <windows.h>
#include <process.h>
#include <stdio.h>
HANDLE hEvent1, hEvent2;
int a[ 5 ];
void Thread( void* pParams )
{ int i, num = 0;
while ( TRUE )
{ WaitForSingleObject( hEvent2, INFINITE );
for ( i = 0; i < 5; i++ ) a[ i ] = num;
SetEvent( hEvent1 );
num++;
}
}
int main( void )
{ hEvent1 = CreateEvent( NULL, FALSE, TRUE, NULL );
hEvent2 = CreateEvent( NULL, FALSE, FALSE, NULL );
_beginthread( Thread, 0, NULL );
while( TRUE )
{ WaitForSingleObject( hEvent1, INFINITE );
printf( "%d %d %d %d %d\n",
a[ 0 ], a[ 1 ], a[ 2 ],
a[ 3 ], a[ 4 ] );
SetEvent( hEvent2 );
}
return 0;
}
В MSDN News за июль/август 1998г. есть статья об
объектах синхронизации. Следующая таблица взята из этой статьи:
|
Объект
|
Относительная скорость
|
Доступ нескольких процессов
|
Подсчет числа обращений к ресурсу
|
Платформы
|
|
Критическая
секция
|
быстро
|
Нет
|
Нет (эксклюзивный
доступ)
|
9x/NT/CE
|
|
Мьютекс
|
медленно
|
Да
|
Нет (эксклюзивный
доступ)
|
9x/NT/CE
|
|
Семафор
|
медленно
|
Да
|
Автоматически
|
9x/NT
|
|
Событие
|
медленно
|
Да
|
Да
|
9x/NT/CE
|
Все началось вполне невинно. Мне впервые потребовалось
вычислить площадь окружности в .NET. Для этого, естественно, нужно точное
значение числа pi. В принципе константа System.Math.PI удобна, но в силу того
что ее точность составляет 20 знаков, меня беспокоила точность моих расчетов
(для полной уверенности мне хотелось получить точность в 21 знак). И я, как и
любой настоящий программист, забыл о своей первоначальной задаче и написал
программу для вычисления числа pi с любой точностью. Скачать
пример AsynchCalcPi.exe.
Все началось вполне невинно. Мне впервые потребовалось
вычислить площадь окружности в .NET. Для этого, естественно, нужно точное
значение числа pi. В принципе константа System.Math.PI удобна, но в силу того
что ее точность составляет 20 знаков, меня беспокоила точность моих расчетов
(для полной уверенности мне хотелось получить точность в 21 знак). И я, как и
любой настоящий программист, забыл о своей первоначальной задаче и написал
программу для вычисления числа pi с любой точностью.
Хотя в большинстве приложений незачем вычислять pi,
многие из них выполняют длительные операции, например печать, вызов Web-сервиса
или подсчет процентных доходов по некоему многомиллионному вкладу в банке
Pacific Northwest. Обычно пользователи готовы подождать завершения такого рода
операций, часто занимаясь в это время чем-то другим, если могут наблюдать за
ходом выполнения операции. Поэтому даже в моем маленьком приложении есть
индикатор прогресса (progress bar). Мой алгоритм вычисляет 9 знаков числа pi за
один проход. Как только появляется новый набор цифр, программа обновляет текст
и изменяет индикатор прогресса.
Ниже приведен код, обновляющий пользовательский
интерфейс (UI) по мере вычисления знаков pi:
void ShowProgress(string pi, int totalDigits, int digitsSoFar) { _pi.Text = pi;
_piProgress.Maximum = totalDigits;
_piProgress.Value = digitsSoFar;
}
void CalcPi(int digits) { StringBuilder pi = new StringBuilder("3", digits + 2);
// Отобразить ход выполнения
ShowProgress(pi.ToString(), digits, 0);
if( digits > 0 ) { pi.Append(".");
for( int i = 0; i < digits; i += 9 ) { int nineDigits = NineDigitsOfPi.StartingAt(i+1);
int digitCount = Math.Min(digits - i, 9);
string ds = string.Format("{0:D9}", nineDigits); pi.Append(ds.Substring(0, digitCount));
// Отобразить ход выполнения
ShowProgress(pi.ToString(), digits, i + digitCount);
}
}
}
Конечно, проблема в том, что это приложение -
однопоточное, поэтому пока вычисляется pi, ничего не рисуется. Раньше я с этим
не сталкивался, так как при установке свойств TextBox.Text и ProgressBar.Value
соответствующие элементы управления перерисовываются в процессе записи свойств
(хотя я заметил, что это лучше удается индикатору прогресса, чем текстовому
полю). Однако, после того как я перевел приложение в фоновый режим, а потом
вновь сделал его активным, мне нужно было отрисовать всю клиентскую область,
для чего служит событие формы Paint. Поскольку никакие другие события не
обрабатываются, пока не закончится обработка текущего (т. е. события Click
кнопки Calc), нам не суждено наблюдать за выполнением вычислений. Значит, на
самом деле нужно освободить UI-поток от выполнения длительной операции и
реализовать ее как асинхронную. А для этого нужен еще один поток.
На тот момент обработчик события Click выглядел так:
void _calcButton_Click(object sender, EventArgs e) { CalcPi((int)_digits.Value);
}
Не забудьте, проблема в том, что до тех пор, пока
CalcPi не вернет управление, поток не выйдет из обработчика Click, а значит,
форма не сможет обрабатывать событие Paint (или любое другое). Решить эту
проблему можно, например, запустив другой поток:
using System.Threading;
…
int _digitsToCalc = 0;
void CalcPiThreadStart() { CalcPi(_digitsToCalc);
}
void _calcButton_Click(object sender, EventArgs e) { _digitsToCalc = (int)_digits.Value;
Thread piThread = new Thread(new ThreadStart(CalcPiThreadStart));
piThread.Start();
}
Теперь, вместо того чтобы ждать завершения CalcPi,
создается новый поток. Метод Thread.Start настроит новый поток как готовый к
запуску и немедленно вернет управление, что позволит UI-потоку вернуться к
своей работе. Тогда, если пользователь захочет вмешаться в работу приложения
(перевести его в фоновый режим, вновь сделать активным, изменить размер его
окна или даже закрыть), UI-поток сможет свободно обрабатывать все эти события,
а рабочий поток - независимо вычислять pi. Получим два потока, выполняющие свои
задачи.
Возможно, вы обратили внимание, что в
CalcPiThreadStart - входную точку рабочего потока - никакие аргументы не
передаются. Вместо этого записывается число знаков в поле _digitsToCalc и
вызывается входная точка потока, которая в свою очередь вызывает CalcPi. Это не
слишком удобно и является одной из причин, предподчительнее для асинхронных
вычислений использовать делегаты. Делегаты поддерживают передачу аргументов,
что избавляет меня от возни с лишним временным полем и промежуточной функцией
между моими двумя функциями.
На случай, если вы не знакомы с делегатами, сообщу,
что это просто объекты, вызывающие статические функции, или функции экземпляра.
В C# они объявляются по синтаксису объявления функций. Скажем, делегат,
вызывающий CalcPi, выглядит так:
delegate void CalcPiDelegate(int digits);
Теперь, когда у меня есть делегат, я могу создать
экземпляр, синхронно вызывающий функцию CalcPi:
void _calcButton_Click(object sender, EventArgs e) { CalcPiDelegate calcPi = new CalcPiDelegate(CalcPi);
calcPi((int)_digits.Value);
}
Конечно, мне не нужен синхронный вызов CalcPi; я хочу
вызывать ее асинхронно. Однако до этого нам придется поглубже разобраться в
работе делегатов. Приведенная выше строка объявления делегата на самом деле
объявляет новый класс, производный от MultiCastDelegate, с тремя функциями -
Invoke, BeginInvoke и EndInvoke, как показано здесь:
class CalcPiDelegate : MulticastDelegate { public void Invoke(int digits);
public void BeginInvoke(int digits, AsyncCallback callback,
object asyncState);
public void EndInvoke(IAsyncResult result);
}
Когда ранее
создавался экземпляр CalcPiDelegate и вызывал его как функцию, на самом
деле вызываллась синхронная функция Invoke, в свою очередь вызывавшую функцию
CalcPi. А BeginInvoke и EndInvoke позволяют асинхронно вызывать функцию и
получать результаты ее работы. Поэтому, чтобы вызвать CalcPi в другом потоке
нужно вызвать BeginInvoke так:
void _calcButton_Click(object sender, EventArgs e) { CalcPiDelegate calcPi = new CalcPiDelegate(CalcPi);
calcPi.BeginInvoke((int)_digits.Value, null, null);
}
Заметьте: в качестве двух последних аргументов
BeginInvoke передается null. Эти аргументы нужны, если вы хотите получить
результат выполнения функции позже (функция EndInvoke предназначена еще и для
этого). А поскольку CalcPi напрямую обновляет UI, эти аргументы нам не нужны.
В Microsoft Windows® XP нижележащая подсистема
поддержки окон, на которой построена Windows Forms, очень надежна. Настолько надежна,
что сумела справиться с нарушением первой заповеди программирования в Windows:
"Не работай с окном из потока, его не создавшего".
Однако, поскольку длительные операции в
Windows-приложениях - не редкость, у всех UI-классов в Windows Forms (т. е. у
классов, производных от System.Windows.Forms.Control) есть свойство, которое
можно использовать из любого потока для безопасного обращения к окну. Это
свойство называется InvokeRequired и возвращает true, если вызывающий поток
должен передать управление потоку, создавшему объект, до вызова методов этого
объекта. Простое выражение Assert в функции ShowProgress сразу выявляет ошибку
в описанном подходе:
using System.Diagnostics;
void ShowProgress(string pi, int totalDigits, int digitsSoFar) { // Проверим, в том ли потоке мы находимся
Debug.Assert(_pi.InvokeRequired == false);
...
}
В документации .NET по этому вопросу все достаточно
четко. В ней говорится: "Есть четыре метода элемента управления, которые
можно безопасно вызывать из любого потока: Invoke, BeginInvoke, EndInvoke и
CreateGraphics. Чтобы вызывать любые другие методы, используйте invoke-методы,
передающие вызовы в поток элемента управления". Значит, при задании
свойств элемента управления я нарушаю это правило. А исходя из имен первых трех
функций (Invoke, BeginInvoke и EndInvoke), которые разрешено вызывать,
становится ясным, что мне нужен еще один делегат - он будет выполняться в
UI-потоке. Если бы я был озабочен блокировкой рабочего потока (как в случае с
UI-потоком), мне бы пришлось воспользоваться асинхронными методами BeginInvoke
и EndInvoke. Но, поскольку рабочий поток всего лишь обслуживает UI-поток, мы
обойдемся более простым синхронным методом Invoke, который определен так:
public object Invoke(Delegate method);
public object Invoke(Delegate method, object[] args);
Первая перегруженная версия Invoke принимает экземпляр
делегата, содержащего метод, который нужно вызвать в UI-потоке. Никаких
аргументов она не предполагает. Однако функция, вызываемая для обновления UI
(ShowProgress), принимает три аргумента, поэтому нам потребуется вторая
перегруженная версия. Чтобы аргументы передавались корректно, нам понадобится
еще один делегат для метода ShowProgress. Применение метода Invoke гарантирует,
что вызовы ShowProgress и обращения к окну будут происходить в корректном
потоке (не забудьте заменить оба вызова ShowProgress в CalcPi):
delegate
void ShowProgressDelegate(string pi, int totalDigits, int digitsSoFar);
void CalcPi(int digits) { StringBuilder pi = new StringBuilder("3", digits + 2);
// Готовимся к асинхронному отображению индикатора прогресса
ShowProgressDelegate showProgress =
new ShowProgressDelegate(ShowProgress);
// Отобразить ход выполнения
this.Invoke(showProgress, new object[] { pi.ToString(), digits, 0});
if( digits > 0 ) { pi.Append(".");
for( int i = 0; i < digits; i += 9 ) { ...
// Отобразить ход выполнения
this.Invoke(showProgress,
new object[] { pi.ToString(), digits, i + digitCount}); }
}
}
Метод Invoke наконец-то позволил мне безопасно
использовать многопоточность в приложении Windows Forms. UI-поток порождает
рабочий, который выполняет длительную операцию и возвращает управление
UI-потоку, когда возникает необходимость в обновлении пользовательского
интерфейса.
Вызов Invoke не слишком удобен, а поскольку он дважды
встречается в функции CalcPi, мы можем облегчить себе жизнь и изменить
ShowProgress, чтобы она сама выполняла асинхронный вызов. Если ShowProgress вызывается
из корректного потока, она обновляет элементы управления, в ином случае она
использует Invoke для вызова самой себя в нужном потоке. Вернемся к предыдущей,
более простой версии CalcPi:
void ShowProgress(string pi, int totalDigits, int digitsSoFar) { // Убедимся, что мы в корректном потоке
if( _pi.InvokeRequired == false ) { _pi.Text = pi;
_piProgress.Maximum = totalDigits;
_piProgress.Value = digitsSoFar;
}
else { // Показывать ход выполнения операции асинхронно
ShowProgressDelegate showProgress =
new ShowProgressDelegate(ShowProgress);
this.Invoke(showProgress,
new object[] { pi, totalDigits, digitsSoFar}); }
}
void CalcPi(int digits) { StringBuilder pi = new StringBuilder("3", digits + 2);
// Показать ход выполнения
ShowProgress(pi.ToString(), digits, 0);
if( digits > 0 ) { pi.Append(".");
for( int i = 0; i < digits; i += 9 ) { ...
// Показать ход выполнения
ShowProgress(pi.ToString(), digits, i + digitCount);
}
}
}
Так как вызов Invoke - синхронный и нам не нужно его
возвращаемое значение (ведь ShowProgress не возвращает значение), здесь лучше
использовать BeginInvoke, чтобы рабочий поток не завис:
BeginInvoke(showProgress, new object[] { pi, totalDigits, digitsSoFar});
BeginInvoke всегда предпочтительнее, если возвращаемое
назначение не требуется, поскольку при использовании этого метода рабочий поток
сразу же возвращается к своей работе, что исключает вероятность взаимной
блокировки.
Многозадачность (multitasking) означает способность
компьютера одновременно выполнять сразу несколько программ, например, слушать
музыку во время игры в любимую игрушку.
Ясное дело, что если ваш компьютер не оснащен несколькими
процессорами, то операционная система всего лишь распределяет свои
вычислительные ресурсы между разными программами, создавая впечатление их
параллельного выполнения.
Такое распределение ресурсов возможно, поскольку
компьютер не всегда занят работой, например, при наборе текста, и процессор
большую часть времени находится в состоянии бездействия.
К примеру, даже если очень быстро набирать символы на
клавиатуре и на ввод одного символа тратить всего 1/20 секунды, то даже это
будет огромный интервал для процессора. Ведь современные процессоры могут
обрабатывать миллионы запросов в секунду.
Многозадачность может быть реализована двумя
способами: или операционная система прерывает выполнение задачи, или управление
операционной системе возвращается по усмотрению самой программы, например,
после выполнения определенной задачи.
Первый способ называется вытесняющей
многозадачностью (preemptive multitasking), а второй - кооперативной
(или невытесняющей) многозадачностью (cooperative multitasking).
Кооперативная многозадачность применяется в ранних
версия Windows и Mac OS 9, а вытесняющая - в UNIX, Linux, Windows NT/2000/XP и
Mac OS X.
Вытесняющая многозадачность работает гораздо
эффективнее кооперативной, но ее сложнее реализовать. Даже более того, некорректно
написанная программа в режиме кооперативной многозадачности способна поглотить
все вычислительные ресурсы системы.
Многопоточные программы развивают идею многозадачности
на более низком уровне: отдельные программы способны выполнять одновременно несколько
задач. Каждая задача обычно сокращенно называется потоком (thread) или
полностью - потоком управления (thread of control).
Программы, способные запускать более одного потока,
называются многопоточными (multithreaded). Каждый поток выполняется в отдельном
контексте, т.е. создается видимость того, что каждый поток имеет собственный
процессор с регистрами, памятью и своим кодом.
В чем же заключается разница между несколькими
процессами и несколькими потоками? Существенное различие состоит в том, что каждый
процесс имеет набор собственных переменных, тогда как потоки обращаются к одним
и тем же данным.
С технической точки зрения гораздо проще создавать и
уничтожать отдельные потоки, чем запускать новые процессы. Именно по этой
причине все современные операционные системы поддерживают многопоточноть. Более
того, процессы взаимодействуют гораздо медленнее и с большими ограничениями,
чем потоки.
Многопоточность имеет очень большое практическое
значение. К примеру, браузер должен обладать возможностью одновременной
загрузки нескольких файлов, а почтовая программа должна позволять читать старые
сообщения во время получения новых.
Одним из преимуществ языка программирования Java
является то, что в нем используется специальный поток для сбора мусора в
фоновом режиме, который избавляет программистов от необходимости управлять
памятью.
Программы с графическим пользовательским интерфейсом используют отдельный поток
для сбора интерфейсных событий в среде операционной системы. Во многих языках
программирования для использования инструментов многопоточности необходимо
загружать внешние пакеты. В языке Java все средства, необходимые для
многопоточного программирования, являются встроенными, что значительно
облегчает решение таких задач.
Тема 5.
Графический интерфейс пользователя в Java
Обзор графических интерфейсов семейства Java. Особенности графического интерфейса Java программ для мобильных устройств.
Графический интерфейс языка Java
подробно рассмотрим подробно на примере приложения типа Applet
выполняемого Java-машиной встроенной в каждый современный браузер,
например Internet Explorer.
Исходный текст нашего аплета
начинается со строки, подключающей оператором import библиотеку классов
java.applet.Applet.
Оператор import должен
располагаться в файле исходного текста перед другими операторами (за
исключением операторов комментария). В качестве параметра оператору import
передается имя подключаемого класса из библиотеки классов. Если же необходимо
подключить все классы данной библиотеки, вместо имени класса указывается символ
"*".
Напомним, что библиотека
java.applet.Applet содержит классы, необходимые для создания аплетов, то есть
разновидности приложений Java, встраиваемых в документы HTML и работающих под
управлением браузера Internet.
Еще одна библиотека классов,
которая нам скоро понадобится, это java.awt. С ее помощью аплет может выполнять
в своем окне рисование различных изображений или текста. Преимущества данного
метода перед использованием для рисования традиционного программного интерфейса
операционной системы заключаются в том, что он работает на любой компьютерной
платформе.
Далее в исходном тексте
аплета определяется класс типа public с именем HelloApplet. Напомним, что это
имя должно обязательно совпадать с именем файла, содержащего исходный текст этого
класса.
public class HelloApplet extends Applet
{ . . .
}
Определенный нами класс
HelloApplet с помощью ключевого слова extends наследуется от класса Applet. При
этом методам класса HelloApplet становятся доступными все методы и данные класса,
за исключением определенных как private. Класс Applet определен в библиотеке
классов java.applet.Applet, которую мы подключили оператором import.
Методы в
классе HelloApplet.
Создавая файл
HelloApplet.java, мастер проектов системы Java NetBeans определила в классе
HelloApplet несколько методов, заменив таким образом некоторые методы базового
класса Applet.
Метод init.
Метод init определен в
базовом классе Applet, от которого наследуются все аплеты. Определение его
таково, что этот метод ровным счетом ничего не делает.
Когда вызывается метод init
и зачем он нужен?
Метод init вызывается тогда,
когда браузер загружает в свое окно документ HTML с оператором <APPLET>,
ссылающимся на данный аплет. В этот момент аплет может выполнять инициализацию,
или, например, создавать потоки, если он работает в многопоточном режиме.
Существует контрпара для
метода init - метод destroy. О нем мы расскажем ниже.
Перед удалением аплета из памяти
вызывается метод destroy, который определен в базовом классе Applet как пустая
заглушка. Мастер проектов добавляет в исходный текст класса переопределение
метода destroy, которое вы можете при необходимости изменить.
Методу destroy обычно
поручают все необходимые операции, которые следует выполнить перед удалением
аплета. Например, если в методе init вы создавали какие-либо потоки, в методе
destroy их нужно завершить.
Метод start вызывается после
метода init в момент, когда пользователь начинает просматривать документ HTML с
встроенным в него аплетом.
Вы можете модифицировать
текст этого метода, если при каждом посещении пользователем страницы с аплетом
необходимо выполнять какую-либо инициализацию.
Дополнением к методу start
служит метод stop. Он получает управление, когда пользователь покидает страницу
с аплетом и загружает в окно браузера другую страницу. Заметим, что метод stop
вызывается перед методом destroy.
Кроме файла исходного текста
аплета мастер проектов создал файл документа HTML HelloApplet.tmp.html,
представленный в листинге.
<applet
name="HelloApplet"
code="HelloApplet"
codebase="file:/e:/sun/vol3/src/HelloApplet"
width="500"
height="600"
align="Top"
alt="If you had a java-enabled
browser, you would see an applet here.">
</applet>
С помощью оператора
<applet> наш аплет встраивается в этот документ. Оператор <APPLET>
используется в паре с оператором </APPLET> и имеет следующие параметры:
|
Параметр
|
Описание
|
|
ALIGN
|
Выравнивание окна аплета относительно
окружающего его текста. Возможны следующие значения:
LEFT
- выравнивание влево относительно окружающего текста;
CENTER
- центрирование;
RIGHT
- выравнивание вправо относительно окружающего текста;
TOP
- выравнивание по верхней границе;
MIDDLE
- центрирование по вертикали;
BOTTOM
- выравнивание по нижней границе
|
|
ALT
|
С помощью этого параметра можно задать
текст, который будет отображаться в окне аплета в том случае, если браузер не
может работать с аплетами Java
|
|
CODE
|
Имя двоичного файла, содержащего байт-код
аплета. По умолчанию путь к этому файлу указывается относительно каталога с
файлом HTML, в который встроен аплет. Такое поведение может быть изменено
параметром CODEBASE
|
|
CODEBASE
|
Базовый адрес URL аплета, то есть путь к
каталогу, содержащему аплет
|
|
HEIGHT
|
Ширина окна аплета в пикселах
|
|
WIDTH
|
Высота окна аплета в пикселах
|
|
HSPACE
|
Зазор слева и справа от окна аплета
|
|
VSPACE
|
Зазор сверху и снизу от окна аплета
|
|
NAME
|
Идентификатор аплета, который может быть
использован другими аплетами, расположенными в одном и том же документе HTML,
а также сценариями JavaScript
|
|
TITLE
|
Строка заголовка
|
Дополнительно между операторами <APPLET> и
</APPLET> вы можете задать параметры аплета. Для этого используется
оператор <PARAM>, который мы рассмотрим позже.
В нашем случае идентификатор NAME и имя двоичного
файла заданы мастером проекта как "HelloApplet":
name="HelloApplet"
code="HelloApplet"
Параметр CODEBASE задает путь к каталогу локального
диска:
codebase="file:/e:/sun/vol3/src/HelloApplet"
Когда вы будете размещать документ HTML на сервере, параметр
CODEBASE необходимо изменить или удалить, если этот документ и аплет
располагаются в одном каталоге. В любом случае, если параметр CODEBASE задан,
он должен указывать адрес URL каталога с аплетом.
import java.applet.Applet;
import java.awt.*;
public class HelloApplet extends Applet
{ public String getAppletInfo()
{ return "HelloJava Applet";
}
public void paint(Graphics g)
{ g.drawString("Hello, Java world!", 20, 20);
}
}
Если запустить аплет на выполнение, в его окне будет
нарисована строка "Hello, Java world".
Наиболее интересен для нас
метод paint, который выполняет рисование в окне аплета. Вот его исходный текст:
public void paint(Graphics g)
{ g.drawString("Hello, Java world!", 20, 20);
}
Если посмотреть определение класса Applet, которое
находится в файле Java \java\applet\Applet.java, то в нем нет метода paint. В
каком же классе определен этот метод?
Рассмотрим иерархию классов JAVA на примере библиотеки java.applet.
Вы увидите иерархию классов:
java.lang.Object
|
+---java.awt.Component
|
+---java.awt.Container
|
+---java.awt.Panel
|
+---java.applet.Applet
Из этой иерархии видно, что класс java.applet.Applet произошел от класса java.awt.Panel. Этот класс, в свою очередь, определен в библиотеке
классов java.awt и произошел
от класса java.awt.Container.
Продолжим наши исследования. В классе
java.awt.Container снова нет метода paint, но сам этот класс создан на базе
класса java.awt.Component.
Но и здесь метода paint нет. Этот метод определен в
классе java.awt.Component, который, в свою очередь, произошел от класса
java.lang.Object и реализует интерфейс java.awt.image.ImageObserver.
Таким образом, мы проследили иерархию классов от
класса java.applet.Applet, на базе которого создан наш аплет, до класса
java.lang.Object, который является базовым для всех классов в Java.
Метод paint определен в классе java.awt.Component, но
так как этот класс является базовым для класса Applet и для нашего класса
HelloApplet, мы можем переопределить метод paint.
Метод paint вызывается, когда необходимо перерисовать
окно аплета. Если вы создавали приложения для операционной системы Windows, то
наверняка знакомы с сообщением WM_PAINT, которое поступает в функцию окна
приложения при необходимости его перерисовки.
Перерисовка окна приложения Windows и окна аплета
обычно выполняется асинхронно по отношению к работе приложения или аплета. В
любой момент времени аплет должен быть готов перерисовать содержимое своего
окна.
Такая техника отличается о той, к которой вы,
возможно, привыкли, создавая обычные программы для MS-DOS. Программы MS-DOS сами
определяют, когда им нужно рисовать на экране, причем рисование может
выполняться из разных мест программы. Аплеты, так же как и приложения Windows,
выполняют рисование в своих окнах централизованно. Аплет делает это в методе
paint, а приложение Windows - при обработке сообщения WM_PAINT.
Обратите внимание, что методу paint в качестве
параметра передается ссылка на объект Graphics:
public void paint(Graphics g)
{ . . .
}
По своему смыслу этот объект
напоминает контекст отображения, с которым хорошо знакомы создатели приложений
Windows. Контекст отображения - это как бы холст, на котором аплет может
рисовать изображение или писать текст. Многочисленные методы класса Graphics
позволяют задавать различные параметры холста, такие, например, как цвет или
шрифт.
Наше приложение вызывает
метод drawString, который рисует текстовую строку в окне аплета:
g.drawString("Hello, Java world!", 20, 20);
Вот прототип этого метода:
public abstract void drawString(String str,
int x, int y);
Через первый параметр методу
drawString передается текстовая строка в виде объекта класса String. Второй и
третий параметр определяют, соответственно, координаты точки, в которой
начнется рисование строки.
В какой координатной
системе?
Аплеты используют систему
координат, которая соответствует режиму отображения MM_TEXT, знакомому тем, кто
создавал приложения Windows. Начало этой системы координат расположено в левом
верхнем углу окна аплета, ось X направлена слева направо, а ось Y - сверху
вниз.
Базовый класс Applet
содержит определение метода getAppletInfo, возвращающее значение null. В нашем
классе HelloApplet, который является дочерним по отношению к классу Applet, мы переопределили
метод getAppletInfo из базового класса следующим образом:
public String getAppletInfo()
{ return "HelloJava Applet";
}
Теперь метод getAppletInfo
возвращает текстовую информацию об аплете в виде объекта класса String.
Этой информацией могут
воспользоваться другие аплеты или сценарии JavaScript, например, для
определения возможности взаимодействия с аплетом.
В предыдущем разделе мы
привели простейший пример аплета, который выполняет рисование текстовой строки
в своем окне. Теперь мы расскажем вам о том, что и как может рисовать аплет.
Способ, которым аплет
выполняет рисование в своем окне, полностью отличается от того, которым
пользуются программы MS-DOS. Вместо того чтобы обращаться напрямую или через
драйвер к регистрам видеоконтроллера, аплет пользуется методами из класса
Graphics. Эти методы инкапсулируют все особенности аппаратуры, предоставляя в
распоряжение программиста средство рисования, которое пригодно для любой
компьютерной платформы.
Для окна аплета создается
объект класса Graphics, ссылка на который передается методу paint. Раньше мы
уже пользовались этим объектом, вызывая для него метод drawString, рисующий в
окне текстовую строку. Объект, ссылка на который передается методу paint, и
есть контекст отображения. Сейчас мы займемся контекстом отображения вплотную.
Проще всего представить себе
контекст отображения как полотно, на котором рисует художник. Точно так же как
художник может выбирать для рисования различные инструменты, программист,
создающий аплет Java, может выбирать различные методы класса Graphics и
задавать различные атрибуты контекста отображения.
В качестве базового для
класса Graphics (полное название класса java.awt.Graphics) выступает класс
java.lang.Object.
Прежде всего мы приведем
прототипы конструктора этого класса и его методов с краткими комментариями.
Полное описание вы сможете найти в электронной документации, которая входит в
комплект Java WorkShop.
Далее мы рассмотрим
назначение основных методов, сгруппировав их по выполняемым функциям.
Конструктор.
· Graphics
protected Graphics();
Методы.
· clearRect
Стирание содержимого прямоугольной области
public abstract void clearRect(int x, int y,
int width, int height);
· clipRect
Задание области ограничения вывода
public abstract void clipRect(int x, int y,
int width, int height);
· copyArea
Копирование содержимого прямоугольной области
public abstract void copyArea(int x, int y,
int width, int height, int dx, int dy);
· create
Создание контекста отображения
public abstract Graphics create();
public Graphics create(int x, int y,
int width, int height);
· dispose
Удаление контекста отображения
public abstract void dispose();
· draw3DRect
Рисование прямоугольной области с трехмерным
выделением
public void draw3DRect(int x, int y,
int width, int height, boolean raised);
· drawArc
Рисование сегмента
public abstract void drawArc(int x, int y,
int width, int height,
int startAngle, int arcAngle);
Рисование сегмента
· drawBytes
Рисование текста из массива байт
public void drawBytes(byte data[],
int offset, int length, int x, int y);
· drawChars
Рисование текста из массива символов
public void drawChars(char data[],
int offset, int length, int x, int y);
· drawImage
Рисование растрового изображения
public abstract boolean drawImage(Image img,
int x, int y,
Color bgcolor, ImageObserver observer);
public abstract Boolean drawImage(Image img,
int x, int y,
ImageObserver observer);
public abstract Boolean drawImage(Image img,
int x, int y,
int width, int height, Color bgcolor,
ImageObserver observer);
public abstract Boolean drawImage(Image img,
int x, int y,
int width, int height,
ImageObserver observer);
· drawLine
Рисование линии
public abstract void drawLine(int x1, int y1,
int x2, int y2);
· drawOval
Рисование овала
public abstract void drawOval(int x, int y,
int width, int height);
· drawPolygon
Рисование многоугольника
public abstract void drawPolygon(
int xPoints[],
int yPoints[], int nPoints);
public void drawPolygon(Polygon p);
· drawRect
Рисование прямоугольника
public void drawRect(int x, int y,
int width, int height);
· drawRoundRect
Рисование прямоугольника с круглыми углами
public abstract void drawRoundRect(
int x, int y,
int width, int height,
int arcWidth, int arcHeight);
· drawString
Рисование текстовой строки
public abstract void drawString(String str,
int x, int y);
· fill3DRect
Рисование заполненного
прямоугольника с трехмерным выделением
public void fill3DRect(int x, int y,
int width, int height, boolean raised);
· fillArc
Рисование заполненного сегмента круга
public abstract void fillArc(int x,
int y, int width,
int height, int startAngle,
int arcAngle);
· fillOval
Рисование заполненного овала
public abstract void fillOval(int x, int y,
int width, int height);
· fillPolygon
Рисование заполненного многоугольника
public abstract void fillPolygon(
int xPoints[],
int yPoints[], int nPoints);
· fillPolygon
Рисование заполненного многоугольника
public void fillPolygon(Polygon p);
public abstract void fillRect(int x, int y,
int width, int height);
· fillRoundRect
Рисование заполненного прямоугольника с круглыми
углами
public abstract void fillRoundRect(
int x, int y,
int width, int height,
int arcWidth, int arcHeight);
· finalize
Прослеживание вызова метода dispose
public void finalize();
· getClipRect
Определение границ области ограничения вывода
public abstract Rectangle getClipRect();
· getColor
Определение цвета, выбранного в контекст отображения
public abstract Color getColor();
· getFont
Определение шрифта, выбранного в контекст отображения
public abstract Font getFont();
· getFontMetrics
Определение метрик текущего шрифта
public FontMetrics getFontMetrics();
· getFontMetrics
Определение метрик заданного шрифта
public abstract FontMetrics
getFontMetrics(Font f);
· setColor
Установка цвета для рисования в контексте отображения
public abstract void setColor(Color c);
· setFont
Установка текущего шрифта в контексте отображения
public abstract void setFont(Font font);
· setPaintMode
Установка режима рисования
Метод setPaintMode устанавливает в контексте
отображения режим рисования, при котором выполняется замещение изображения
текущим цветом, установленном в контексте отображения.
public abstract void setPaintMode();
· setXORMode
Установка маски для
рисования
Задавая маску для
рисования при помощи метода setXORMode, вы можете выполнить при рисовании
замещение текущего цвета на цвет, указанный в параметре метода, и наоборот,
цвета, указанного в параметре метода, на текущий.
Все остальные цвета
изменяются непредсказуемым образом, однако эта операция обратима, если вы
нарисуете ту же самую фигуру два раза на одном и том же месте.
public abstract void setXORMode(Color c1);
· translate
Сдвиг начала системы координат
Метод translate сдвигает начало системы координат в
контексте отображения таким образом, что оно перемещается в точку с
координатами (x, y), заданными через параметры метода:
public abstract void translate(int x, int y);
· toString
Получение текстовой строки, представляющей данный
контекст отображения
public String toString();
Изменяя атрибуты контекста отображения, приложение
Java может установить цвет для рисования графических изображений, таких как
линии и многоугольники, шрифт для рисования текста, режим рисования и маску.
Возможен также сдвиг начала системы координат.
Изменение цвета, выбранного в контекст отображения,
выполняется достаточно часто. В классе Graphics для изменения цвета определен
метод setColor, прототип которого представлен ниже:
public abstract void setColor(Color c);
В качестве параметра методу setColor передается ссылка
на объект класса Color, с помощью которого можно выбрать тот или иной цвет.
Как задается цвет?
Для этого можно использовать несколько способов.
Прежде всего, вам доступны статические объекты,
определяющие фиксированный набор основных цветов:
|
Объект
|
Цвет
|
|
public
final static Color black;
|
черный
|
|
public final
static Color blue;
|
голубой
|
|
public
final static Color cyan;
|
циан
|
|
public
final static Color darkGray;
|
темно-серый
|
|
public
final static Color gray;
|
серый
|
|
public
final static Color green;
|
зеленый
|
|
public final
static Color lightGray;
|
светло-серый
|
|
public
final static Color magenta;
|
малиновый
|
|
public
final static Color orange;
|
оранжевый
|
|
public
final static Color pink;
|
розовый
|
|
public
final static Color red;
|
красный
|
|
public final
static Color white;
|
белый
|
|
public
final static Color yellow;
|
желтый
|
Этим набором цветов пользоваться очень просто:
public void paint(Graphics g)
{ g.setColor(Color.yellow);
g.drawString("Hello, Java world!", 10, 20);
. . .
}
Здесь мы привели
фрагмент исходного текста метода paint, в котором в контексте отображения
устанавливается желтый цвет. После этого метод drawString выведет текстовую
строку " Hello, Java world!" желтым цветом.
Если необходима более
точная установка цвета, вы можете воспользоваться одним из трех конструкторов
объекта Color:
public Color(float r, float g, float b);
public Color(int r, int g, int b);
public Color(int rgb);
Первые два конструктора
позволяют задавать цвет в виде совокупности значений трех основных цветовых
компонент - красной, желтой и голубой (соответственно, параметры r, g и b). Для
первого конструктора диапазон возможных значений компонент цвета находится в
диапазоне от 0.0 до 1.0, а для второго - в диапазоне от 0 до 255.
Третий конструктор
также позволяет задавать отдельные компоненты цвета, однако они должны быть
скомбинированы в одной переменной типа int. Голубая компонента занимает биты от
0 до 7, зеленая - от 8 до 15, красная - от 16 до 23.
Ниже мы привели пример
выбора цвета с помощью конструктора, передав ему три целочисленных значения
цветовых компонент:
g.setColor(new Color(0, 128, 128));
В классе Color определено еще несколько методов,
которые могут оказаться вам полезными:
|
Метод
|
Описание
|
|
public Color brighter ();
|
Установка более светлого варианта того же цвета
|
|
public Color darker ();
|
Установка более темного варианта того же цвета
|
|
public boolean
equals (Object obj);
|
Проверка равенства цветов текущего объекта и объекта, заданного
параметром
|
|
public int getBlue ();
|
Определение голубой компоненты цвета (в диапазоне от 0 до 255)
|
|
public int getRed ();
|
Определение красной компоненты цвета (в диапазоне от 0 до 255)
|
|
public int getGreen ();
|
Определение зеленой компоненты цвета (в диапазоне от 0 до 255)
|
|
getHSBColor (float
h, float s, float b);
|
Определение компонент оттенка, насыщенности и яркости (схема HSB)
|
|
public int getRGB ();
|
Определение компонент RGB для цвета, выбранного в контекст
отображения
|
|
public static int
HSBtoRGB (float hue, float saturation, float brightness);
|
Преобразование цветового представления из схемы HSB в схему RGB
|
|
public static float[]
RGBtoHSB (int r, int g, int b, float hsbvals[]);
|
Преобразование, обратное выполняемому предыдущей функцией
|
|
public String toString ();
|
Получение текстовой строки названия цвета
|
Второй способ установки
цвето фона и изображения заключается в вызове методов setBackground и
setForeground, например:
setBackground(Color.yellow);
setForeground(Color.black);
Здесь мы устанавливаем для окна аплета желтый цвет
фона и черный цвет изображения.
С помощью метода
setFont из класса Graphics вы можете выбрать в контекст отображения шрифт,
который будет использоваться методами drawString, drawBytes и drawChars для
рисования текста. Вот прототип метода setFont:
public abstract void setFont(Font font);
В качестве параметра методу setFont следует передать
объект класса Font.
Приведем краткое перечисление полей, конструкторов и
методов этого класса.
Поля класса.
· name
protected String name;
· size
protected int size;
· style
protected int style;
Битовые маски стиля шрифта.
· BOLD
public final static int BOLD;
· ITALIC
public final static int ITALIC;
· PLAIN
public final static int PLAIN;
Конструкторы.
public Font(String name,
int style, int size);
Методы.
· equals
Сравнение шрифтов
public boolean equals(Object obj);
· getFamily
Определение названия семейства шрифтов
public String getFamily();
· getFont
Получение шрифта по его характеристикам
public static Font getFont(String nm);
public static Font getFont(String nm,
Font font);
· getName
Определение названия шрифта
public String getName();
· getSize
Определение размера шрифта
public int getSize();
· getStyle
Определение стиля шрифта
public int getStyle();
· hashCode
Получение хэш-кода шрифта
public int hashCode();
· isBold
Определение жирности шрифта
public boolean isBold();
· isItalic
Проверка, является ли шрифт наклонным
public boolean isItalic();
· isPlain
Проверка, есть ли шрифтовое выделение
public boolean isPlain();
· toString
Получение текстовой строки для объекта
public String toString();
Создавая шрифт конструктором Font, вы должны указать
имя, стиль и размер шрифта.
В качестве имени можно указать, например, такие строки
как Helvetica или Courier. Учтите, что в системе удаленного пользователя,
загрузившего ваш аплет, может не найтись шрифта с указанным вами именем. В этом
случае браузер заменит его на наиболее подходящий (с его точки зрения).
Стиль шрифта задается
масками BOLD, ITALIC и PLAIN, которые можно комбинировать при помощи логической
операции "ИЛИ":
|
Маска
|
Описание
|
|
BOLD
|
Утолщенный шрифт
|
|
ITALIC
|
Наклонный шрифт
|
|
PLAIN
|
Шрифтовое выделение не используется
|
Что же касается размера шрифта, то он указывается в
пикселах.
Ряд методов класса
Graphics позволяет определить различные атрибуты контекста отображения,
например, цвет, выбранный в контекст отображения или метрики текущего шрифта,
которым выполняется рисование текста.
Рассмотрим методы,
позволяющие определить атрибуты контекста отображения.
С помощью метода
clipRect, о котором мы расскажем чуть позже, вы можете определить в окне аплета
область ограничения вывода прямоугольной формы. Вне этой области рисование
графических изображений и текста не выполняется.
Метод getClipRect
позволяет вам определить координаты текущей области ограничения, заданной в
контексте отображения:
public abstract Rectangle getClipRect();
Метод возвращает ссылку
на объект класса Rectangle, который, в частности, имеет поля класса с именами
x, y, height и width. В этих полях находится, соответственно, координаты
верхнего левого угла, высота и ширина прямоугольной области.
Метод getColor
возвращает ссылку на объект класса Color, представляющий текущий цвет,
выбранный в контекст отображения:
public abstract Color getColor();
С помощью метода
getFont, возвращающего ссылку на объект класса Font, вы можете определить
текущий шрифт, выбранный в контекст отображения:
public abstract Font getFont();
Несмотря на то, что вы
можете заказать шрифт с заданным именем и размером, не следует надеяться, что
навигатор выделит вам именно такой шрифт, какой вы попросите. Для правильного
размещения текста и других изображений в окне аплета вам необходимо знать
метрики реального шрифта, выбранного навигатором в контекст отображения.
Метрики текущего шрифта
в контексте отображения вы можете узнать при помощи метода getFontMetrics,
прототип которого приведен ниже:
public FontMetrics getFontMetrics();
Метод getFontMetrics возвращает ссылку на объект
класса FontMetrics. Ниже мы привели список наиболее важных методов этого
класса, предназначенных для получения отдельных параметров шрифта:
|
Метод
|
Описание
|
|
public Font getFont();
|
Определение шрифта, который описывается данной метрикой
|
|
public int
bytesWidth(byte data[], int off, int len);
|
Метод возвращает ширину строки символов, расположенных в массиве байт
data. Параметры off и len задают, соответственно, смещение начала строки в
массиве и ее длину
|
|
public int
charsWidth(char data[], int off, int len);
|
Метод возвращает ширину строки символов, расположенных в массиве
символов data. Параметры off и len задают, соответственно, смещение начала
строки в массиве и ее длину
|
|
public int
charWidth(char ch);
|
Метод возвращает ширину заданного символа
|
|
public int
charWidth(int ch);
|
Метод возвращает ширину заданной строки символов
|
|
public int getAscent();
|
Определение расстояния от базовой линии до верхней выступающей части
символов
|
|
public int getDescent();
|
Определение расстояния от базовой линии до нижней выступающей части
символов
|
|
public int getLeading();
|
Расстояние между строками текста
|
|
public int getHeight();
|
Определение полной высоты символов, выполняется по формуле:
getLeading() + getAscent() + getDescent()
|
|
public int getMaxAdvance();
|
Максимальная ширина символов в шрифте
|
|
public int getMaxAscent();
|
Максимальное расстояние от базовой линии до верхней выступающей части
символов для символов данного шрифта
|
|
public int getMaxDescent();
|
Максимальное расстояние от базовой линии до нижней выступающей части
символов для символов данного шрифта
|
|
public int[] getWidths();
|
Массив, в котором хранятся значения ширины первых 256 символов в
шрифте
|
|
public int
stringWidth(String str);
|
Ширина строки, передаваемой методу в качестве параметра
|
|
public String toString();
|
Текстовая строка, представляющая данную метрику шрифта
|
Обратите внимание на
метод stringWidth, позволяющий определить ширину текстовой строки. Заметим, что
без этого метода определение ширины текстовой строки было бы непростой задачей,
особенно если шрифт имеет переменную ширину символов.
Для определения полной
высоты строки символов вы можете воспользоваться методом getHeight.
Метод getFontMetrics с
параметром типа Font позволяет определить метрики любого шрифта, передаваемого
ему в качестве параметра:
public abstract FontMetrics
getFontMetrics(Font f);
В отличие от нее метод getFontMetrics без параметров
возвращает метрики текущего шрифта, выбранного в контекст отображения.
В этом разделе мы
опишем методы класса Graphics, предназначенные для рисования элементарных
геометрических фигур, таких как линии, прямоугольники, окружности и так далее.
Для того чтобы нарисовать прямую тонкую сплошную
линию, вы можете воспользоваться методом drawLine, прототип которого приведен
ниже:
public abstract void drawLine(int x1,
int y1,int x2, int y2);
Концы линии имеют
координаты (x1, y1) и (x2, y2).
К сожалению, в
контексте отображения не предусмотрены никакие атрибуты, позволяющие нарисовать
пунктирную линию или линию увеличенной толщины.
Среди методов класса
Graphics есть несколько, предназначенных для рисования прямоугольников. Первый из
них, с именем drawRect, позволяет нарисовать прямоугольник, заданный
координатами своего левого верхнего угла, шириной и высотой:
public void drawRect(int x, int y,
int width, int height);
Параметры x и y задают,
соответственно, координаты верхнего левого угла, а параметры width и height -
высоту и ширину прямоугольника.
В отличие от метода
drawRect, рисующего только прямоугольную рамку, метод fillRect рисует
заполненный прямоугольник. Для рисования и заполнения прямоугольника
используется цвет, выбранный в контекст отображения.
Прототип метода
fillRect приведен ниже:
public abstract void fillRect(int x, int y,
int width, int height);
Метод drawRoundRect
позволяет нарисовать прямоугольник с закругленными углами:
public abstract void drawRoundRect(int x,
int y, int width,
int height, int arcWidth, int arcHeight);
Параметры x и y определяют координаты верхнего левого
угла прямоугольника, параметры width и height задают, соответственно его ширину
и высоту.
Размеры эллипса, образующего закругления по углам, вы
можете задать с помощью параметров arcWidth и arcHeight. Первый из них задает
ширину эллипса, а второй - высоту.
Метод fillRoundRect позволяет нарисовать заполненный
прямоугольник с закругленными углами .
Назначение параметров этого метода аналогично
назначению параметров только что рассмотренного метода drawRoundRect:
public abstract void fillRoundRect(int x,
int y,
int width, int height,
int arcWidth, int arcHeight);
Метод fill3Drect предназначен для рисования
выступающего или западающего прямоугольника:
public void fill3DRect(int x, int y,
int width, int height, boolean raised);
Если значение параметра
raised равно true, рисуется выступающий прямоугольник, если false - западающий.
Назначение остальных параметров аналогично назначению параметров метода
drawRect.
Для рисования
многоугольников в классе Graphics предусмотрено четыре метода, два из которых
рисуют незаполненные многоугольники, а два - заполненные.
Первый метод рисует
незаполненный многоугольник, заданный массивами координат по осям X и Y:
public abstract void drawPolygon(
int xPoints[],
int yPoints[], int nPoints);
Через параметры xPoints
и yPoints передаются, соответственно, ссылки на массивы координат по оис X и Y.
Параметр nPoints задает количество точек в массивах.
В этом многоугольнике шесть вершин с координатами от
(x0, y0) до (x5, y5), причем для того чтобы он стал замкнутым, координаты
первой и последней вершины совпадают.
Второй метод также рисует незаполненный многоугольник,
однако в качестве параметра методу передается ссылка на объект Polygon:
public void drawPolygon(Polygon p);
Класс Polygon достаточно прост. Приведем описание его
полей, конструкторов и методов:
Поля
класса.
· npoints
Количество вершин
public int npoints;
· xpoints
Массив координат по оси X
public int xpoints[];
· ypoints
Массив координат по оси Y
public int ypoints[]
Конструкторы.
public Polygon ();
public Polygon(int xpoints[],
int ypoints[], int npoints);
Методы.
· addPoint
Добавление вершины
public void addPoint(int x, int y);
· getBoundingBox
Получение координат охватывающего прямоугольника
public Rectangle getBoundingBox();
· inside
Проверка, находится ли точка внутри многоугольника
public boolean inside(int x, int y);
Ниже мы показали
фрагмент кода, в котором создается многоугольник, а затем в него добавляется
несколько точек. Многоугольник рисуется методом drawPolygon:
Polygon p = new Polygon();
p.addPoint(270, 239);
p.addPoint(350, 230);
p.addPoint(360, 180);
p.addPoint(390, 160);
p.addPoint(340, 130);
p.addPoint(270, 239);
g.drawPolygon(p);
Если вам нужно
нарисовать заполненный многоугольник (рис. 7), то для этого вы можете
воспользоваться методами, приведенными ниже:
public abstract void fillPolygon(
int xPoints[],
int yPoints[], int nPoints);
public void fillPolygon(Polygon p);
Первый из этих методов
рисует многоугольник, координаты вершин которого заданы в массивах, второй -
получая объект класса Polygon в качестве параметра.
Для рисования окружностей и овалов вы можете
воспользоваться методом drawOval:
public abstract void drawOval(
int x, int y,
int width, int height);
Параметры этого методы задают
координаты и размеры прямоугольника, в который вписывается рисуемый овал
Метод fillOval
предназначен для рисования заполненного овала. Назначение его параметров
аналогично назначению параметров метода drawOval:
public abstract void fillOval(
int x, int y,
int width, int height);
Метод drawArc
предназначен для рисования незаполненного сегмента. Прототип этого метода
приведен ниже:
public abstract void drawArc(
int x, int y,
int width, int height,
int startAngle, int arcAngle);
Параметры x, y, width и
height задают координаты прямоугольника, в который вписан сегмент.
Параметры startAngle и
arcAngle задаются в градусах. Они определяют, соответственно, начальный угол и
угол разворота сегмента.
Для того чтобы
нарисовать заполненный сегмент, вы можете воспользоваться методом fillArc:
public abstract void fillArc(int x, int y,
int width, int height,
int startAngle, int arcAngle);
Если для окна аплета задать
область ограничения, то рисование будет возможно только в пределах этой
области. Область ограничения задается методом clipRect, прототип которого мы
привели ниже:
public abstract void clipRect(
int x, int y,
int width, int height);
Параметры x, y, width и height задают координаты
прямоугольной области ограничения.
Метод copyArea позволяет скопировать содержимое любой
прямоугольной области окна аплета:
public abstract void copyArea(
int x, int y,
int width, int height, int dx, int dy);
Параметры x, y, width и
height задают координаты копируемой прямоугольной области. Область копируется в
другую прямоугольную область такого же размера, причем параметры dx и dy
определяют координаты последней.
В этом разделе мы
приведем исходные тексты аплета Draw, в которых демонстрируется использование
различных функций рисования.
В верхней части окна мы вывели список вех шрифтов, доступных
аплету, а также примеры оформления строки Test string с использованием этих
шрифтов.
В нижней части окна нарисовано несколько
геометрических фигур.
Исходные тексты аплета Draw вы найдете в листинге.
import java.applet.*;
import java.awt.*;
public class draw extends Applet
{ Toolkit tk;
String szFontList[];
FontMetrics fm;
int yStart = 20;
int yStep;
String parm_TestString;
public void init()
{ tk = Toolkit.getDefaultToolkit();
szFontList = tk.getFontList();
parm_TestString =
getParameter("TestString"); }
public String getAppletInfo()
{ return "Name: draw";
}
public void paint(Graphics g)
{ int yDraw;
Dimension dimAppWndDimension = getSize();
g.clearRect(0, 0,
dimAppWndDimension.width - 1,
dimAppWndDimension.height - 1);
g.setColor(Color.yellow);
g.fillRect(0, 0,
dimAppWndDimension.width - 1,
dimAppWndDimension.height - 1);
g.setColor(Color.black);
g.drawRect(0, 0,
dimAppWndDimension.width - 1,
dimAppWndDimension.height - 1);
fm = g.getFontMetrics();
yStep = fm.getHeight();
for(int i = 0; i < szFontList.length; i++)
{ g.setFont(new Font("Helvetica", Font.PLAIN, 12));
g.drawString(szFontList[i], 10,
yStart + yStep * i);
fm = g.getFontMetrics();
yStep = fm.getHeight();
g.setFont(new Font(szFontList[i],
Font.PLAIN, 12));
g.drawString(parm_TestString,
100, yStart + yStep * i);
}
yDraw = yStart + yStep * szFontList.length
+ yStep;
Polygon p = new Polygon();
p.addPoint(70, yDraw);
p.addPoint(150, yDraw + 30);
p.addPoint(160, yDraw + 80);
p.addPoint(190, yDraw + 60);
p.addPoint(140, yDraw + 30);
p.addPoint(70, yDraw + 39);
g.drawPolygon(p);
g.setColor(Color.red);
g.drawRect(10, yDraw + 85, 200, 100);
g.setColor(Color.black);
g.drawArc(10, yDraw + 85,
200, 100, -50, 320);
}
public String[][] getParameterInfo()
{ String[][] info =
{ { "TestString", "String", "Test string"
}
};
return info;
}
}
При инициализации аплета метод init извлекает список
доступных шрифтов и принимает значение параметра TestString, передаваемое
аплету в документе HTML.
Извлечение
списка шрифтов.
Процедура извлечения списка доступных шрифтов
достаточно проста и выполняется следующим образом:
Toolkit tk;
String szFontList[];
. . .
tk = Toolkit.getDefaultToolkit();
szFontList = tk.getFontList();
Аплет вызывает
статический метод getDefaultToolkit из класса Toolkit и затем, пользуясь полученной ссылкой, извлекает
список шрифтов, записывая его в массив szFontList.
Для чего еще можно
использовать класс Toolkit?
Класс Toolkit является
абстрактным суперклассом для всех реализаций AWT. Порожденные от него классы
используются для привязки различных компонент конкретных реализаций.
Создавая свои аплеты,
вы будете редко прибегать к услугам этого класса. Однако в нем есть несколько
полезных методов, прототипы которых мы перечислим ниже:
· getDefaultToolkit
Получение ссылки на Toolkit
public static Toolkit getDefaultToolkit();
· getColorModel
Определение текущей цветовой
модели, выбранной в контекст отображения
public abstract ColorModel getColorModel();
· getFontList
Получение списка шрифтов, доступных аплету
public abstract String[] getFontList();
· getFontMetrics
Получение метрик заданного шрифта
public abstract FontMetrics
getFontMetrics(Font font);
· getImage
Получение растрового изображения по имени файла
public abstract Image
getImage(String filename);
· getImage
Получение растрового изображения по адресу URL
public abstract Image getImage(URL url);
· getScreenResolution
Определение разрешения экрана в точках на дюйм
public abstract int getScreenResolution();
· getScreenSize
Размеры экрана в пикселах
public abstract Dimension getScreenSize();
· prepareImage
Подготовка растрового изображения для вывода
public abstract boolean prepareImage(
Image image,
int width, int height,
ImageObserver observer);
· sync
Синхронизация состояния Toolkit
public abstract void sync();
Наиболее интересны, с нашей
точки зрения, методы getFontList, getScreenResolution и getScreenSize, с
помощью которых аплет может, соответственно, получить список шрифтов,
определить разрешение и размер экрана. Последние два параметра позволяют
сформировать содержимое окна аплета оптимальным образом исходя из объема
информации, который может в нем разместиться.
Получение
значения параметров.
До сих пор наши аплеты
не получали параметров из документов HTML, в которые мы их встраивали.
Конечно, все константы,
текстовые строки, адреса URL и другую информацию можно закодировать
непосредственно в исходном тексте аплета, однако, очевидно, это очень неудобно.
Пользуясь операторами
<PARAM>, расположенными в документе HTML сразу после оператора
<APPLET>, можно передать аплету произвольное количество параметров,
например, в виде текстовых строк:
<applet
code=MyApplet.class
id=MyApplet
. . .
width=320
height=240 >
<param name=ParamName1 value="Value 1">
<param name=ParamName2 value="Value 2">
<param name=ParamName3 value="Value 3">
<param name=ParamName4 value="Value 4">
. . .
</applet>
Здесь через параметр
NAME оператора <PARAM> передается имя параметра аплета, а через параметр
VALUE - значение соответствующего параметра.
Как параметр может
получить значение параметров?
Для получения значения
любого параметра аплет должен использовать метод getParameter. В качестве
единственного параметра этому методу передается имя параметра аплета в виде
строки типа String, например:
parm_TestString = getParameter("TestString");
Обычно в аплете также
определяется метод getParameterInfo, возвращающий информацию о параметрах. Вот
исходный текст этого метода для нашего аплета Draw:
public String[][] getParameterInfo()
{ String[][] info =
{ { "TestString", "String", "Test string"
}
};
return info;
}
Метод getParameterInfo возвращает массив массивов текстовых строк. Первая
строка указывает имя параметра, вторая - тип передаваемых через него данных, а третья
- значение параметра по умолчанию.
Первым делом метод
paint определяет размеры окна аплета, вызывая для этого метод getSize:
Dimension dimAppWndDimension = getSize();
Метод getSize
возвращает ссылку на объект класса Dimension, хранящий высоту и ширину объекта:
· height
Высота
public int height;
· width
Ширина
public int width;
В классе Dimension
предусмотрено три конструктора и один метод:
public Dimension();
public Dimension(Dimension d);
public Dimension(int width, int height);
· toString
Получение строки,
представляющей класс
public String toString();
После определения
размеров окна аплета метод paint стирает содержимое всего окна:
g.clearRect(0, 0,
dimAppWndDimension.width - 1,
dimAppWndDimension.height - 1);
Далее в контексте
отображения устанавливается желтый цвет:
g.setColor(Color.yellow);
Этим цветом заполняется
внутренняя область окна аплета, для чего применяется метод fillRect:
g.fillRect(0, 0,
dimAppWndDimension.width - 1,
dimAppWndDimension.height - 1);
Затем метод paint
устанавливает в контексте отображения черный цвет и рисует тонкую черную рамку
вокруг окна аплета:
g.setColor(Color.black);
g.drawRect(0, 0,
dimAppWndDimension.width - 1,
dimAppWndDimension.height - 1);
На следующем этапе мы получаем метрики текущего
шрифта, выбранного в контекст отображения:
fm = g.getFontMetrics();
Пользуясь этими метриками, мы определяем высоту
символов текущего шрифта и записываем ее в поле yStep:
yStep = fm.getHeight();
После этого метод paint
запускает цикл по всем шрифтам, установленным в системе:
for(int i = 0; i < szFontList.length; i++)
{ . . .
}
Количество доступных шрифтов
равно размеру массива szFontList, которое вычисляется как szFontList.length.
Метод paint выписывает
в окне аплета название каждого шрифта, устанавливая для этого шрифт Helvetica
размером 12 пикселов:
g.setFont(new Font("Helvetica", Font.PLAIN, 12));
g.drawString(szFontList[i],
10, yStart + yStep * i);
Смещение каждой новой строки с названием шрифта
вычисляется исходя из высоты символов установленного шрифта:
fm = g.getFontMetrics();
yStep = fm.getHeight();
После названия шрифта
метод paint рисует в окне аплета текстовую строку parm_TestString, полученную
через параметр с именем "TestString":
g.setFont(new Font(szFontList[i],
Font.PLAIN, 12));
g.drawString(parm_TestString,
100, yStart + yStep * i);
Перед тем как перейти к рисованию геометрических
фигур, метод paint запоминает в поле yDraw координату последней строки названия
шрифта, сделав отступ высотой yStep :
int yDraw;
yDraw = yStart +
yStep * szFontList.length + yStep;
Первая фигура, которую рисует наш аплет, это многоугольник.
Мы создаем многоугольник как объект класса Polygon:
Polygon p = new Polygon();
В этот объект при помощи метода addPoint добавляется
несколько точек:
p.addPoint(70, yDraw);
p.addPoint(150, yDraw + 30);
p.addPoint(160, yDraw + 80);
p.addPoint(190, yDraw + 60);
p.addPoint(140, yDraw + 30);
p.addPoint(70, yDraw + 39);
После добавления всех точек метод paint рисует
многоугольник, вызывая для этого метод drawPolygon:
g.drawPolygon(p);
Затем мы устанавливаем в контексте отображения красный
цвет и рисуем прямоугольник:
g.setColor(Color.red);
g.drawRect(10, yDraw + 85, 200, 100);
Затем метод paint вписывает в этот прямоугольник
сегмент окружности:
g.setColor(Color.black);
g.drawArc(10, yDraw + 85, 200, 100, -50, 320);
Документ HTML для
аплета Draw не имеет никаких особенностей. Он представлен в листинге.
<applet
name="draw"
code="draw"
codebase="file:/e:/Sun/Articles/vol4/src/draw"
width="250"
height="350"
align="Top"
alt="If you had a java-enabled browser,
you would see an applet here."
>
<param name="TestString" value="Test string">
<hr>If your browser recognized the applet tag,
you would see an applet here.<hr>
</applet>
Тема 6. Работа с
базами данных в Java
Разумеется, что организовать
доступ к базам данных из современного языка программирования в наше время не
представляет никакой сложности. Более того, и сами языки программирования более
всего оцениваются разработчиками по типу и возможностям заложенных в них
средств доступа к базам данных, удобству и полноте интерфейсов. В этом смысле
Java не представляет исключения. Уже в версии JDK1.1 появился пакет классов
java.sql, обеспечивающий больщинство функций, известных к тому времени
разработчикам ODBC-приложений. В этом пакете содержится ряд замечательных
классов, например: java.sql.CallableStatement, который обеспечивает выполнение
на Java хранимых процедур; java.sql.DatabaseMetaData, который исследует базу
данных на предмет ее реляционной полноты и целостности с получением самых
разнообразных данных о типах и содержимом таблиц, колонок, индексов, ключей и
т.д.; наконец, - java.sql.ResultSetMetaData, с помощью которого можно выводить
в удобном виде всю необходимую информацию из таблиц базы данных или печатать
сами метаданные в виде названий таблиц и колонок.
Однако, коренное
отличие Java от других традиционных языков программирования заключается в том,
что одни и те же функции доступа к базам данных, с помощью универсальности и
кроссплатформенности Java, можно организовать чрезвычайно гибко, используя все
преимущества современных объектно-ориентированных технологий, WWW и
Intranet/Internet. Рассмотрим по порядку все варианты использования
Java-программ при взаимодействии с базами данных.
JDBC (Java Database
Connectivity) является не протоколом, а интерфейсом и основан на спецификациях
SAG CLI (SQL Access Group Call Level Interface - интерфейс уровня вызова группы
доступа SQL). Сам по себе JDBC работать не может и использует основные
абстракции и методы ODBC. Хотя в стандарте JDBC API и предусмотрена возможность
работы не только через ODBC, а и через использование прямых линков к базам
данных по двух- или трех-звенной схеме (см. Рис.1), эту схему используют гораздо
реже, чем повсеместно используемый JDBC-ODBC-Bridge занимающий центральное
место в общей схеме взаимодействия интерфейсов (см. Рис. 2).
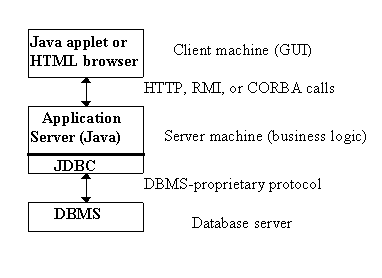
Рис. 1. Непосредственный доступ к базе данных по
3-х-звенной схеме
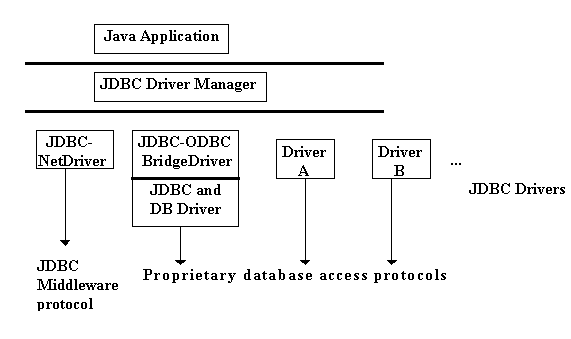
Рис. 2. Схема взаимодействия интерфейсов
Даже беглого взгляда на
Рис. 2 вполне достаточно, чтобы понять - общая схема взаимодействия интерфейсов
в Java удивительным образом напоминает столь всем знакомую схему ODBC с ее
гениальным изобретением драйвер-менеджера к различным СУБД и единого
универсального пользовательского интерфейса. JDBC Driver Manager - это основной
ствол JDBC-архитектуры. Его первичные функции очень просты - соединить
Java-программу и соответствующий JDBC драйвер и затем выйти из игры.
Естественно, что ODBC был взят в качестве основы JDBC из-за его популярности
среди независимых поставщиков программного обеспечения и пользователей. Но
тогда возникает законный вопрос - а зачем вообще нужен JDBC и не легче ли было
организовать интерфейсный доступ к ODBC-драйверам непосредственно из Java?
Ответом на этот вопрос может быть только однозначное нет. Путь через
JDBC-ODBC-Bridge, как ни странно, может оказаться гораздо короче.
1. ODBC нельзя использовать непосредственно из Java,
поскольку он основан на C-интерфейсе. Вызов из Java C-кода нарушает целостную
концепцию Java, пробивает брешь в защите и делает программу трудно-переносимой.
2. Перенос ODBC C-API в Java-API нежелателен. К
примеру, Java не имеет указателей, в то время как в ODBC они используются.
3. ODBC слишком сложен для понимания. В нем смешаны
простые и сложные вещи, причем сложные опции иногда применяются для самых
простых запросов.
4. Java-API необходим, чтобы добиться абсолютно чистых
Java решений. Когда ODBC используется, то ODBC-драйвер и ODBC менеджер должны
быть инсталлированы на каждой клиентской машине. В то же время, JDBC драйвер
написан полностью на Java и может быть легко переносим на любые платформы от сетевых
компьютеров до мэйнфреймов.
JDBC API - это
естественный Java-интерфейс к базовым SQL абстракциям и, восприняв дух и
основные абстракции концепции ODBC, он реализован, все-таки, как настоящий
Java-интерфейс, согласующийся с остальными частями системы Java.
В отличие от интерфейса
ODBC, JDBC организован намного проще. Главной его частью является драйвер,
поставляемый фирмой JavaSoft для доступа из JDBC к источникам данных. Этот
драйвер является самым верхним в иерархии классов JDBC и называется DriverManager.
Согласно, установившимся правилам Internet, база данных и средства ее
обслуживания идентифируются при помощи URL.
jdbc::
где под понимается имя
конкретного драйвера, или некоего механизма установления соединения с базой
данных, например, ODBC. В случае применения ODBC, в URL-строку подставляется
именно эта аббревиатура, а в качестве используется обычный DSN (Data Source
Name), т.е. имя ODBC-источника из ODBC.INI файла. Например:
jdbc:odbc:dBase
В некоторых случаях вместо ODBC может быть использовано
имя прямого сетевого сервиса к базе данных, например:
jdbc:dcenaming:accounts-payable,
или
jdbc:dbnet://ultra1:1789/state
В последнем случае
часть URL //ultra1:1789/state представляет собой и описывает имя хоста, порт и соответствующий
идентификатор для доступа к соответствующей базе данных.
Однако, как уже
говорилось выше, чаще всего, все-таки используется механизм ODBC благодаря его
универсальности и доступности. Программа взаимодействия между драйвером JDBC и
ODBC разработана фирмой JavaSoft в сотрудничестве с InterSolv и называется
JDBC-ODBC-Bridge. Она реализована в виде JdbcOdbc.class (для платформы Windows
JdbcOdbc.dll) и входит в поставку JDK1.1. Помимо JdbcOdbc-библиотек должны
существовать специальные драйвера (библиотеки), которые реализуют
непосредственный доступ к базам данных через стандартный интерфейс ODBC. Как
правило эти библиотеки описываются в файле ODBC.INI. На внутреннем уровне
JDBC-ODBC-Bridge отображает медоды Java в вызовы ODBC и тем самым позволяет
использовать любые существующие драйверы ODBC, которых к настоящему времени
накоплено в изобилии.
Рассмотрим типичное
приложение на Java c доступом к типичному реляционному серверу или даже к
обычной dBase-таблице.
// Следующий код на Java используется как пример. Простой подстановкой
// соответствующих значений url, login, и password, и, затем подстановкой
// SQL операторов вы можете посылать их в базу данных.
//--------------------------------------
//
// Module: SimpleSelect.java
//
// Описание: Эта программа для ODBC API интерфейса. Java-приложение
// будет присоединяться к JDBC драйверу, посылать select оператор
// и показывать результаты в таблице
//
// Продукт: JDBC к ODBC Мост
//
// Автор: Karl Moss (С.Дунаев модификация для работы с кириллицей)
//
// Дата: Апрель 1997
//
// Copyright: 1990-1996 INTERSOLV, Inc.
// This software contains confidential and proprietary
// information of INTERSOLV, Inc.
//--------------------------------------
import java.net.URL;
import java.sql.*;
import java.io.*;
class SimpleSelect {
public static void main (String args[]) { String url = "jdbc:odbc:dBase";
String query = "SELECT * FROM my_table";
try {
// Загрузка jdbc-odbc-bridge драйвера
Class.forName ("sun.jdbc.odbc.JdbcOdbcDriver");
DriverManager.setLogStream(System.out);
// Попытка соединения с драйвером. Каждый из
// зарегистрированных драйверов будет загружаться, пока
// не будет найден тот, который сможет обработать этот URL
Connection con = DriverManager.getConnection(url, "", "");
// Если не можете соединиться, то произойдет exception
// (исключительная ситуация). Однако, если вы попадете
// в следующую строку программы, значит, вы успешно соединились с URL
// Проверки и печать сообщения об успешном соединении
//
checkForWarning (con.getWarnings ());
// Получить DatabaseMetaData объект и показать
// информацию о соединении
DatabaseMetaData dma = con.getMetaData ();
//System.out.println("nConnected to " + dma.getURL()); //System.out.println("Driver " + //dma.getDriverName());
//System.out.println("Version " + //dma.getDriverVersion());
//System.out.println("");
// Создать Оператор-объект для посылки
// SQL операторов в драйвер
Statement stmt = con.createStatement ();
// Образовать запрос, путем создания ResultSet объекта
ResultSet rs = stmt.executeQuery (query);
// Показать все колонки и ряды из набора результатов
dispResultSet (rs);
// Закрыть результирующий набор
rs.close();
// Закрыть оператор
stmt.close();
// Закрыть соединение
con.close();
}
catch (SQLException ex) {
// Случилось SQLException. Перехватим и
// покажем информацию об ошибке. Заметим, что это
// может быть множество ошибок, связанных вместе
//
//System.out.println ("n*** SQLException caught ***n");
while (ex != null) { //System.out.println ("SQLState: " + // ex.getSQLState ());
//System.out.println ("Message: " + ex.getMessage ()); //System.out.println ("Vendor: " + //ex.getErrorCode ());
ex = ex.getNextException ();
//System.out.println (""); }
}
catch (java.lang.Exception ex) {
// Получив некоторые другие типы exception, распечатаем их.
ex.printStackTrace ();
}
}
//----------------------------------
// checkForWarning
// Проверка и распечатка предупреждений. Возврат true если
// предупреждение существует
//----------------------------------
private static boolean checkForWarning (SQLWarning warn)
throws SQLException { boolean rc = false;
// Если SQLWarning объект был получен, показать
// предупреждающее сообщение.
if (warn != null) { System.out.println ("n *** Warning ***n"); rc = true;
while (warn != null) { //System.out.println ("SQLState: " + //warn.getSQLState ());
//System.out.println ("Message: " + //warn.getMessage ());
//System.out.println ("Vendor: " + //warn.getErrorCode ());
//System.out.println (""); warn = warn.getNextWarning ();
}
}
return rc;
}
//----------------------------------
// dispResultSet
// Показать таблицу полученных результатов
//----------------------------------
private static void dispResultSet (ResultSet rs)
throws SQLException, IOException
{ // Объявление необходимых переменных и
// константы для желаемой таблицы перекодировки данных
int i, length, j;
String cp1 = new String("Cp1251"); // Получить the ResultSetMetaData. Они будут использованы
// для печати заголовков
ResultSetMetaData rsmd = rs.getMetaData ();
// Получить номер столбца в результирующем наборе
int numCols = rsmd.getColumnCount ();
// Показать заголовок столбца
for (i=1; i<=numCols; i++) { if (i > 1) System.out.print(","); //System.out.print(rsmd.getColumnLabel(i));
}
System.out.println("");
// Показать данные, загружая их до тех пор, пока не исчерпается
// результирующий набор
boolean more = rs.next ();
while (more) {
// Цикл по столбцам
for (i=1; i<=numCols; i++) {
// Следующая группа операторов реализует функции перекодировки
// строк из таблицы базы данных в желаемый формат, потому что в
// различных базах символы могут быть закодированы произвольным
// образом. Если использовать стандартный метод - getString - на выходе
// получается абракадабра. Строки нужно сначала перевести в Unicode,
// затем конвертировать в строку Windows и убрать лидирующие нули
InputStream str1 = rs.getUnicodeStream(i);
byte str2[];
byte str3[];
int sizeCol = rsmd.getColumnDisplaySize(i);
str2 = new byte[sizeCol+sizeCol];
str3 = new byte[sizeCol+sizeCol];
length = str1.read(str2);
// Здесь нужно убрать нули из строки, которые предваряют каждый
// перекодированный символ
k=1;
for (j=1; j<sizeCol*2; j++) {if (str2[j] != 0) { str3[k]=str2[j]; k=k+1; } }
String str = new String(str3,cp1);
System.out.print(str);
}
System.out.println("");
// Загрузка следующего ряда в наборе
more = rs.next ();
}
}
}
В этой простой
программе, приводимой во множестве руководств, мною произведено одно небольшое
изменение, позволяющее использовать ее для работы с различными базами данных, содержащих
таблицы с полями в кириллической кодировке. Дело в том, что хотя Java
автоматически производит преобразования из Unicode и обратно в соответствии с
установленными на вашей машине языковыми спецификациями (так называемые
locale), эти преобразования не всегда действуют по отношению к кириллическим
фонтам, особенно, когда кириллические строки прописаны не непосредственно в
Java-программе, а передаются из внешних источников, например из баз данных
через несколько промежуточных слоев. Та же проблема, как мы увидим далее,
возникает и при использовании сервлетов, работающих в тесной взаимоувязке с
Web-серверами.
Тема 7. Платформы
CDC и CLDC
Java 2
Micro Edition - подмножество технологий фирмы
Sun Microsystems, основанное на концепции Java-платформы и предназначенное для
выполнения приложений, написанных на языке Java, на устройствах бытовой
электроники, например мобильных телефонах, персональных органайзерах, цифровых
телевизионных ресиверах и т. п. Основой J2ME является виртуальная машина,
способная исполнять байт-код языка Java.
J2ME задумана для того,
чтобы обеспечить эффективное исполнение Java-приложений на устройствах бытовой
электроники, отличительной особенностью которых является ограниченная
вычислительная мощность, небольшой объем памяти, малый размер дисплея, питание
от портативной батареи, а также низкоскоростные и недостаточно надежные
коммуникационные возможности. Типичный современный мобильный телефон содержит
внутри 32-разрядный RISC-процессор с тактовой частотой 50 МГц, имеет объем
оперативной памяти около 4 Мбайт, цветной дисплей размером 4 дюйма и оснащен
возможностью GPRS-соединения с интернетом со скоростью максимум 172 кбит/с
(которое при этом фундаментально ненадежно, скорость передачи данных может
неожиданно упасть или соединение может быть вообще полностью потеряно).
J2ME специфицирует две
базовые конфигурации, которые определяют требования к виртуальной машине (иначе
говоря, определяют подмножество стандартного языка Java, которое виртуальная
машина способна выполнять), а также минимальный набор базовых классов. В
настоящее время в J2ME имеется две конфигурации: CLDC (Connected Limited Device
Configuration - конфигурация устройства с ограниченными коммуникационными возможностями)
и CDC (Connected Device Configuration - конфигурация устройства с нормальными
коммуникационными возможностями).
J2ME также определяет
несколько так называемых профилей (profiles), которые дополняют и расширяют
упомянутые выше конфигурации, в частности определяют модель приложения
(программы на языке Java, совместимой с конкретным профилем), возможности
графического интерфейса (то есть отображения информации на дисплее устройства и
способы получения команд от пользователя), включая коммуникационные функции
(например, доступ к интернету) и пр.
В настоящее время самой
распространенной конфигурацией является CLDC, для которой разработан профиль
MIDP (Mobile Information Device Profile - профиль для мобильного устройства с
информационными функциями). MIDP определяет понятие мидлета (MIDlet) -
компактного приложения на языке Java, имеющего небольшой размер, что делает его
пригодным для передачи по сети и установки на мобильном устройстве. Другим
популярным профилем для J2ME/CLDC является DoJa, разработанный фирмой NTT
DoCoMo для ее собственного сервиса iMode. iMode весьма распространен в Японии и
в меньшей степени в Европе и на Дальнем Востоке.
Конфигурация CLDC
успешно используется в большинстве современных мобильных телефонов и
портативных органайзеров. По данным компании Sun Microsystems к концу 2004 года
в мире было выпущено более 570 миллионов мобильных устройств с поддержкой этой
конфигурации Java. Это делает J2ME доминирующей технологией Java в мире. Объемы
производства мобильных телефонов значительно превышают количество других
компьютерных устройств, способных исполнять приложения на Java (например,
персональных компьютеров).
Java 2 Platform, Micro Edition
(J2ME) предлагает прекрасные средства для разработчиков, переносящих сетевое и
платформно-независимое мировоззрение на ограниченные по памяти и мощности
процессора устройства. Разработчик Soma Ghost объясняет основы мира J2ME,
показывая вам, строительные блоки платформы и демонстрируя пример приложения.
Персональные и интеллектуальные
устройства сегодня стали необходимостью нашей жизни. Эти устройства, среди
которых сотовые телефоны, двунаправленные пейджеры, смарт-карты, персональные
компьютерные записные книжки и палмтопы, имеют тенденцию быть
специализированными, ограниченными по ресурсам сетевыми устройствами, а не теми
настольными компьютерами универсального назначения, которые мы знали до
настоящего времени. Специально для этого огромного потребительского сектора
Java 2 Platform, Micro Edition (J2ME) предоставляет изобилие передовых технологий
Java.
Развитие Java VM: От
настольных компьютеров до микроустройств.
Микроустройства, для которых
предназначена J2ME, имеют 16-ти или 32-х разрядные микропроцессоры с
минимальным полным объемом памяти равным примерно 128 Кб. Они соответствуют
конфигурации Connected Limited Device Configuration (CLDC), сохраняя такие
традиции Java, как переносимость кода в любое время и в любое место, гибкость
размещения, безопасную работу в сети и устойчивость кода. Необходимой
составляющей J2ME CDLC является облегченная JVM, называемая K Virtual Machine
(KVM). KVM разработана для ограниченных по ресурсам сетевых устройств, имеющих
небольшую память.
Другая конфигурация J2ME -
Connected Device Configuration (CDC) предназначена для развитых потребительских
электронных и встраиваемых устройств, таких как интеллектуальные коммуникаторы,
современные "интеллектуальные" пейджеры, персональные цифровые
помощники (PDA) и интерактивные цифровые телевизионные приставки. Обычно эти
устройства работают на 32-х разрядном микропроцессоре/микроконтроллере и имеют
более 2 Мб общей памяти для хранения виртуальной машины и библиотек. CDC
содержит C Virtual Machine (CVM). В этой статье мы рассмотрим архитектуры CLDC
и KVM. Дополнительная информация о CDC и CVM находится в разделе Ресурсы, расположенном
ниже.
KVM адаптирован под особенности
небольших устройств следующим образом:
· Размеры VM и библиотек классов уменьшены до объема в
50-80 Кб объектного кода;
· Объем используемой памяти уменьшен до десятков
килобайт;
· Производительность оптимизирована для устройств на
16-ти и 32-х разрядных процессорах;
· Архитектура является переносимой, с небольшим
количеством зависящего от аппаратуры и/или от платформы кода;
· Многопоточность и сборка мусора является независимой
от системы;
· Компоненты виртуальной машины могут быть
сконфигурированы для конкретных устройств, увеличивая таким образом гибкость.
Архитектура и
конфигурация J2ME.
Архитектура J2ME основана на
семействах и категориях устройств. Категория определяет конкретный тип
устройства; сотовые телефоны, простые пейджеры и персональные организаторы
являются разными категориями. Семейство устройств образуется группой категорий,
имеющих сходные требования к объему памяти, а мощности процессора. Все вместе
сотовые телефоны, простые пейджеры и простые персональные организаторы образуют
одно семейство малых отображающих устройств.
На рисунке 3 показана взаимосвязь
между семействами и категориями устройств в контексте J2ME.
Рис. 3. Семейства и категории устройств
Для того, чтобы поддержать
гибкость и настраиваемость размещения, требуемые семейством ограниченных по
ресурсам устройств, архитектура J2ME спроектирована модульной и масштабируемой.
Эта модульность и масштабируемость определяется технологией J2ME в завершенной
прикладной модели времени исполнения, имеющей четыре программных уровня,
строящихся над операционной системой устройства.
На рисунке 4 показана архитектура
J2ME.
Рис. 4. Архитектура J2ME
· Уровень Java Virtual Machine: Этот уровень
представляет собой реализацию виртуальной машины Java, которая адаптирована под
операционную систему конкретного устройства и поддерживает конкретную
конфигурацию J2ME.
· Уровень конфигурации: Уровень конфигурации определяет
минимальный набор функций JVM и библиотек классов Java, доступных для
определенной категории устройств. В некоторой степени конфигурация определяет
общие свойства и особенности платформы Java и библиотек, которые в
предположении разработчиков должны быть доступны для всех устройств,
принадлежащих конкретной категории. Этот уровень менее видим для пользователей,
но является очень важным для разработчиков профилей.
· Уровень профиля: Уровень профиля определяет
минимальный набор API, доступный для конкретного семейства устройств. Профили
создаются для конкретной конфигурации. Приложения создаются для конкретного
профиля и являются, таким образом, переносимыми на любое устройство,
поддерживающее этот профиль. Устройство может поддерживать несколько профилей.
Этот уровень является наиболее видимым для пользователей и поставщиков
приложений.
· Уровень MIDP: Уровень Mobile Information Device
Profile (MIDP) представляет собой набор Java API, предназначенный для решения
таких вопросов как пользовательский интерфейс, персистентное хранение и сетевые
функции.
Уровни Java Virtual Machine, конфигурации и профиля вместе образуют Connected Limited Device
Configuration (CDLC). Профиль MID
и CDLC обеспечивают стандартную среду времени исполнения, позволяющую новым
приложениям и службам динамически размещаться на пользовательских устройствах.
Программирование
J2ME при помощи MIDP API: Строительные блоки.
Комбинация CLDC и MIDP
обеспечивает законченную среду для создания приложений для сотовых телефонов и
простых двунаправленных пейджеров.
Ядром MIDP является
мидлет-приложение. Это приложение расширяет класс MIDlet таким образом, чтобы
управляющее приложением программное обеспечение могло управлять мидлетом,
извлекать свойства из описателя размещения, информировать об изменениях
состояния и вызывать их.
Все мидлеты расширяют класс
MIDlet - интерфейс между средой времени исполнения (менеджер приложений) и
кодом мидлет-приложения. Класс MIDlet обеспечивает API для запуска, остановки,
перезапуска и завершения мидлет-приложения.
Управляющее приложением
программное обеспечение может управлять активностью нескольких мидлетов в среде
времени исполнения. Кроме того, мидлет может сам вызывать некоторые изменения
состояния и информировать управляющее приложением программное обеспечение об
этих изменениях.
Полный набор классов MIDP API
может быть разделен на две категории:
· MIDP API для пользовательского интерфейса: Эти API
разработаны так, что взаимодействие с пользователем основывается на
последовательности экранов, каждый из которых предоставляет пользователю
определенное количество информации. Команды предоставляются пользователю
поэкранно. API дает возможность приложению определять, какой экран отображать
следующим, какие вычисления выполнять и какие запросы передавать сетевой
службе.
· MIDP API для управления базой данных: Эти API
организуют и управляют базой данных устройства, которая содержит информацию,
остающуюся персистентной между многочисленными вызовами мидлета.
CLDC API используется для
управления строками, объектами и целыми числами. Также предоставляется
подмножество Java 2 API для выполнения операций ввода/вывода и сетевых
коммуникаций.
На рисунке 5 показаны
строительные блоки J2ME.
Рис. 5. Строительные блоки J2ME
Взаимосвязь между Java API Standard Edition и Java API Micro Edition показана на рисунке 6.
Рис. 6. Взаимосвязь между J2ME API и J2SE API
Обработка событий в
J2ME.
Обработка событий в J2ME в
отличие от обработки событий в версии платформы Java для настольных компьютеров
основывается на последовательности экранов. Каждый экран содержит определенное
количество данных.
Команды предоставляются
пользователю поэкранно. Объект Command инкапсулирует название и информацию,
относящуюся к семантике действия. Объект Command используется главным образом
для предоставления пользователю набора возможных действий. Дальнейшее поведение
определяется в объекте CommandListener, связанном с экраном.
Каждый объект Command содержит
три порции информации: метку, тип и приоритет. Метка используется для
визуального представления команды; тип и приоритет используются системой для
определения того, как объект Command отображается на конкретный
пользовательский интерфейс.
На рисунке 7 показан механизм
обработки событий в J2ME.
Рис. 7. Обработка событий в J2ME
Разработка
пользовательских интерфейсов.
Хотя MIDP API поддерживает
ограниченный профиль, он предоставляет полный набор элементов пользовательского
интерфейса. Ниже перечислены основные из них:
· Alert действует как экран, информирующий пользователя
об исключительной ситуации или об ошибке.
· Choice реализует набор из предопределенного числа
возможностей выбора действий.
· ChoiceGroup предоставляет группу связанных возможностей
выбора действий.
· Form выступает как контейнер для других элементов
пользовательского интерфейса.
· List предоставляет список действий.
· StringItem действует как строка, предназначенная
только для отображения.
· TextBox представляет собой экран, позволяющий
пользователю вводить и редактировать текст.
· TextField позволяет пользователю вводить и
редактировать текст. В Form можно разместить несколько TextField.
· DateField представляет собой редактируемый компонент
для представления информации о дате и времени. DateField может быть расположен
в Form.
· Ticker работает как прокручиваемый текст.
Полный список элементов
пользовательского интерфейса доступен в документации по MIDP API, которая
прилагается к J2ME Wireless Toolkit (для дополнительной информации см. раздел
Ресурсы, расположенный ниже).
Управление базой
данных устройства.
MIDP предоставляет набор классов
и интерфейсов для организации и управления базой данных устройства:
RecordStore, RecordComparator и RecordFilter. RecordStore состоит из набора
записей, остающихся персистентными между различными вызовами мидлета. Сравнение
записей в RecordStore или извлечение набора записей из RecordStore
обеспечивается интерфейсами RecordComparator и RecordFilter.
Разработка
J2ME-приложений.
В предыдущих разделах был дан
обзор J2ME. В этом разделе мы познакомимся с практическими деталями платформы,
разработав реальное приложение - интерфейс телефона.
Пример приложения:
Телефонный календарь.
Одной из замечательных
возможностей в J2ME является возможность манипулирования датой в ограниченной
по ресурсам среде. Элемент пользовательского интерфейса DateField, предлагаемый
J2ME, представляет собой редактируемый компонент для представления календарной
информации (то есть, даты и времени). В этом разделе мы разработаем
J2ME-приложение, отображающее прокручиваемый календарь на сотовом телефоне,
используя функции DateField и Date.
Пример реализации приложения –
календарь.
// Import of API classes
import
javax.microedition.midlet.*;
import
javax.microedition.lcdui.*;
import java.util.*;
//A first MIDlet
with simple text and a few commands.
public class
PhoneCalendar extends MIDlet
implements CommandListener, ItemStateListener
{
//The commands
private Command
exitCommand;
//The display for
this MIDlet
private Display
display;
// Display items
e.g Form and DateField
Form displayForm;
DateField date;
public
PhoneCalendar() {
display = Display.getDisplay(this);
exitCommand = new
Command("Exit", Command.SCREEN, 1);
date = new DateField("Select to
date", DateField.DATE);
}
// Start the MIDlet
by creating the Form and
// associating the
exit command and listener.
public void
startApp() {
displayForm = new
Form("Quick Calendar");
displayForm.append(date);
displayForm.addCommand(exitCommand);
displayForm.setCommandListener(this);
displayForm.setItemStateListener(this);
display.setCurrent(displayForm);
}
public void itemStateChanged(Item item)
{
// Get the values from changed item
}
// Pause is a no-op
when there is no background
// activities or
record stores to be closed.
public void
pauseApp() { }
// Destroy must
cleanup everything not handled
// by the garbage
collector.
public void
destroyApp (boolean unconditional) { }
// Respond to
commands. Here we are only implementing
// the exit
command. In the exit command, cleanup and
// notify that the
MIDlet has been destroyed.
public void
commandAction (
Command c,
Displayable s) {
if (c ==
exitCommand) {
destroyApp(false);
notifyDestroyed();
}
}
}
Мидлет PhoneCalendar, определенный выше, расширяет ItemListener и CommandListener. Это дает
возможность мидлету проследить изменение элемента на экране и среагировать на
команду пользователя. Пользовательский интерфейс начинается с определения
экрана телефона и присоединения к нему объекта Form. Form выступает как
контейнер и может содержать много элементов пользовательского интерфейса.
Функция commandAction() работает как обработчик команд в J2ME и определяет
действия, которые необходимо выполнить для конкретной команды.
Размещение J2ME.
Вы можете загрузить эмулятор от
Sun, позволяющий вам протестировать J2ME-приложения на настольном компьютере.
Если вы избегаете этих графических излишеств, то вы можете разместить J2ME из
командной строки.
Размещение в среде
эмулятора.
Размещение и выполнение
J2ME-приложения в среде эмулятора включает этапы установки и конфигурирования
эмулятора. J2ME Wireless Toolkit предоставляет среду эмулятора для разработки и
размещения Java-приложений в ограниченные по ресурсам устройства. Вот
последовательность необходимых действий:
1. Установите J2ME Wireless Toolkit (см. раздел Ресурсы).
Программа установки подскажет вам все необходимые действия. Выберите режим
standalone для запуска этих примеров. Выберите режим integrated, если вы хотите
работать с IDE.
2. Создайте новый проект, используя пользовательский
интерфейс KToolbar. Укажите имя класса.
3. Поместите класс, указанный на шаге 2, в каталог
C:\[J2ME Installation directory]\apps\[Project Name]\src.
4. Откомпилируйте проект.
5. Выберите DefaultGrayPhone в качестве устройства по
умолчанию в J2ME Wireless Toolkit->Default Device Selection.
6. Запустите проект.
Набор программ также позволяет
предоставляет возможность спакетировать проект в jar-файл и jad-файл. Двойной
щелчок на jad-файле разместит приложение, указанное в jar-файле.
Размещение из
командной строки.
Доступно также большое количество
ключей командной строки.
1. Создайте файл классов:
C:\J2ME\apps\PhoneCalendar>
javac _ tmpclasses _ootclasspath
C:\J2ME\lib\midpapi.zip
-classpath tmpclasses;
classes src\*.java
2.
Создайте файл декларации - manifest.mf:
MIDlet-1:
PhoneCalendar,
PhoneCalendar.png,
PhoneCalendar
MIDlet-Name: Phone
Calendar
MIDlet-Vendor: Sun
Microsystems
MIDlet-Version: 1.0
MicroEdition-Configuration:
CLDC-1.0
MicroEdition-Profile:
MIDP-1.0
3. Создайте jar-файл:
C:\J2ME\apps\PhoneCalendar>jar
cfm .\bin\
PhoneCalendar.jar
manifest.mf -C classes . _ res .
4. Создайте jad-файл:
MIDlet-1:
PhoneCalendar,
PhoneCalendar.png,
PhoneCalendar
MIDlet-Jar-Size:
4490
MIDlet-Jar-URL:
F:\J2ME\apps\PhoneCalendar\bin\
PhoneCalendar.jar
MIDlet-Name:
PhoneCalendar
MIDlet-Vendor: Sun
Microsystems
MIDlet-Version: 1.0
5.
Запустите jad-файл:
C:\J2ME\bin>
emulator -Xdescriptor:
C:\J2ME\apps\PhoneCalendar
\bin\PhoneCalendar.jad
J2ME является
значительным шагом вперед в беспроводной технологии по сравнению с
существующими программными моделями в направлении к переносимой,
предназначенной для сети виртуальной машины Java. Гибкость при разработке и
размещении J2ME-приложений эффективно ответит на увеличивающиеся требования в
беспроводном мире.
1. Скомпилируется ли этот код? Если да - что будет
выведено на экран и почему? Если нет – какие вы видите ошибки?
public class Main {
private static String str;
protected Main() {
System.out.println(str);
}
protected
static void main(String[] args) {
Main.str
= "Hello World!!!";
Main
main = new Main();
}
}
2. Скомпилируется ли этот код? Если нет - какие
библиотеки надо подключить, чтобы он скомпилировался? Что этот код делает? Что
будет выведено на экран?
Содержание файла
D:\текст.txt: это простая
строка
public class Main {
protected Main() {
}
public
static void main(String[] args) {
String
fileName = "D:\\текст.txt";
try
{
FileReader file = new FileReader(fileName);
int
c;
while((c = file.read())!=-1)
System.out.print((char)c);
}
catch(IOException ioexec)
{
System.out.println(ioexec.getMessage());
}
}
}
3. Объявлен класс MyClass, что он
концептуально представляет? Какую библиотеку надо подключить, чтобы этот код
запустился? Какой объект завершит выполнение функции start первым?
public class MyClass extends Thread {
private
int d;
private
String name;
public
MyClass(String _name, int _d) {
name =
_name;
d = _d;
}
public void
run() {
for (int
i=0; i<1000; i+=d) {
System.out.println(name + " " + i);
}
}
}
public class Main {
protected Main() {
}
public
static void main(String[] args) {
MyClass
t1 = new MyClass("first", 1);
MyClass
t2 = new MyClass("second", 100);
t1.setPriority(Thread.NORM_PRIORITY);
t2.setPriority(Thread.MIN_PRIORITY);
t2.start();
t1.start();
}
}
4. Какие
модификаторы позволяют обращаться к элементу из классов того же пакета?
public
protected
по умолчанию
private
5.
Может ли
класс не иметь ни одного конструктора?
Да
Нет
6. Как записывается
заголовок метода main?
public int main()
public int main(String[]
args)
public static void main(String[] args)
public void main()
7. Сколько
комментариев в следующем примере кода:
int x = 0; /* text // text /*
int y=1; // text */ // text */
8. Как создать
массив, эквивалентный объявляемому ниже, но без заведения переменной?
int x[][]=new int[2][3];
new
int[2][3]
{{0, 0}, {0, 0},
{0, 0}}
{{0, 0, 0}, {0,
0, 0}}
new int[][]{{0,
0, 0}, {0, 0, 0}}
new int[][]{{0,
0}, {0, 0}, {0, 0}}
9. Какие преимущества дает многопоточная архитектура?
a. упрощается программа, если ее алгоритм требует выполнения
нескольких действий одновременно (например, обслуживание запросов)
b. программа выполняется быстрее
c. можно более полно использовать аппаратные ресурсы для
каждой задачи
d. если различные задачи требуют разных аппаратных ресурсов,
причем, все они могут управляться центральным процессором без перегрузки, то за
счет распределенной работы суммарное время выполнения уменьшится
e. за счет управления приоритетами потоков можно
настроить систему так, что, выполняя меньшее количество действий, она будет
совершать больше полезной работы для пользователя
f. за счет управления приоритетами потоков можно добиться
ускорения работы программы
10.
Что такое демон-поток?
a. поток, который постоянно работает и выполняет некие
периодические действия
b. поток, который не может существовать без обычных
потоков, так как без них виртуальная машина прекращает свою работу
c.
поток, который
автоматически останавливается виртуальной машиной, когда программа больше не
нуждается в нем
11.
Какие источники могут использоваться классами стандартных входных потоков java
в качестве источника данных?
a. файл – представляется объектом класса File
b. массив – представляется массивом byte[] или char[]
c.
строка –
представляется объектом String
d. сетевое соединение – входной поток получается вызовом
getInputStream() у объекта класса java.net.Socket
e.
сетевое
соединение – объект класса java.net.URL
12.
Необходимо написать метод, который получает в качестве параметра значение угла в
градусах типа double и вычисляет его косинус. Какой из приведенных вариантов
верен?
a. double getCos(double angle){
return Math.cos(angle);
}
b. double getCos(double angle){
return Math.cos(angle * Math.PI /
180);
}
c. double getCos(double angle){
return Math.cos(angle * PI / 180);
}
13. Какое значение будет выведено на консоль в представленном фрагменте кода?
String str1 = "abc";
String str2 = "abc";
System.out.println(str1 == str2);
a. true
b. false
14.
Если имеется переменная типа абстрактный класс, можно ли с ее помощью
обращаться к абстрактным методам этого класса?
a. можно
b. можно, но если ее значение будет равно null, то
возникнет ошибка времени исполнения
c. нельзя
15.
В данном случае выберите все правильные ответы.
private void say(int digit){
switch(digit){
case 1:
System.out.print("ONE");
break;
case 2:
System.out.print("TWO");
case 3:
System.out.print("TREE");
default:System.out.print("Unknown value");
}
}
a. digit = 1 ONE
b. digit = 0 TWO TREE
c. digit = 2 TWO
Unknown value
d. digit = 3 TREE
Unknown value
16. Что такое J2ME? Поясните архитектуру J2ME. Дайте
характеристику устройствам, для которых предназначена J2ME.
1. Что не
хватает для компиляции исходника Midlet`a?
1. public class
MainClass {
2. private Display
display = Display.getDisplay(this);
3. private Command
exitCommand = new Command("Exit", Command.EXIT, 1);
4. private Form Welcome
= new Form("Титле Форм");
5.
6. public void
commandAction(Command command, Displayable displayable) {
7. if (command ==
exitCommand) {
8. display.setCurrent(null);
9. destroyApp(true);
10. notifyDestroyed();
11. }
12. }
13. public void startApp() {
14. Welcome.append("Здарово! ХВАТИТ СИДЕТЬ В БАШЕ :-)");
15. Welcome.addCommand(exitCommand);
16. Welcome.setCommandListener(this);
17. }
18. public void pauseApp() {
19. }
20. public void destroyApp(boolean unconditional)
{
21. }
22. }
2. К
предыдущему заданию добавить кнопку «New». При
нажатии, добавлялась новая строка: «Смайлик убери!»
3. К
предыдущему заданию добавить кнопку «Delete». При
нажатии, удаляла первую строку.
4. Назвать
основные методы для Midlet`a и прокомментировать их.
5. Вспомнить не
меньше 4 основные объекты управления мидлета.
Помнить! Что display – объект экрана.
Пример:
|
Объект
|
Описание
|
Пример
применения
|
|
TextBox
|
Ввод строки с клавиатуры
|
…
TextBox
Text = new TextBox("Название строки",
"", 256, TextField.ANY);
…
display.setCurrent(Text);
…
String str
= Text.getString(); // результат ввода
|
|
|
|
|
6. Что выведет
на экран программа?
1. import java.lang.*;
2.
3. public class Main implements Runnable{
4. private
int i;
5. public Main(int
i) {
6. this.i = i;
7. }
8. public static void main(String[] args) {
9. for (int
i = 0; i < 10; i++) {
10. Thread t = new Thread(new Main(i),
"Поток №" + i);
11. t.run();
12. }
13. while(true){}
14. }
15. public void
run() {
16. while (true) {
17. System.out.println("Поток №" + i);
18. }
19. }
20. }
7. Как
запустить несколько потоков?
8. Доработать предыдущую
программу. По завершению по «Timeout».
9. Что такое J2ME? Поясните архитектуру J2ME. Дайте
характеристику устройствам, для которых предназначена J2ME.
1. Ноутон П., Шилдт Г. Java 2: Пер. с
англ.— СПь.: БХВ-Петербург, 2001, — 1072 с.
2. Хабибуллин И.Ш. Самоучитель Java.
— СПб.: БХВ-Петербург, 2002, — 464 с.
3. Дмитриева М.В. Самоучитель
JavaScript. — СПб.: БХВ-Петербург, 2003, — 512 с.
4. Вебер Д. Технология Java в
подлиннике: пер с англ. — СПб.: ВНV—Санкт-Петербург, 1997. —1104 с.