Архитектура сервера баз данных
Повышение эффективности и оперативности обслуживания большого числа клиентских запросов, помимо простого увеличения ресурсов и вычислительной мощности сервера, может быть достигнуто двумя путями:
· снижением суммарного расхода памяти и вычислительных ресурсов за счёт буферизации (кэширования) и совместного использования (разделяемые ресурсы) наиболее часто запрашиваемых данных и процедур;
· распараллеливанием процесса обработки запроса – использованием разных процессоров для параллельной обработки изолированных подзапросов и (или) для одновременного обращения к частям БД, размещённым на отдельных физических носителях.
Рассмотрим архитектуры, реализующие следующие модели совместной обработки клиентских запросов.
Архитектура «один к одному»
В этом случае (Рис. 19-4) для обслуживания каждого запроса запускается отдельный серверный процесс.
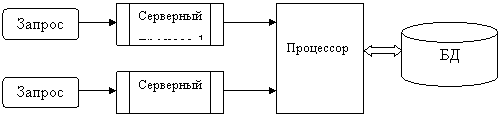 |
Рис. 19-5. Архитектура сервера «один к одному»
Таким образом, даже если от клиентов поступят совершенно одинаковые запросы, для обработки каждого из них будет запущен отдельный процесс, каждый из которых будет выполнять одинаковые действия и использовать одни и те же ресурсы.