Голиков В.А.
Основы программирования на С++
Голиков В.А. Основы программирования на С++ / Московская финансово-промышленная академия. – 79 с.
© Голиков В.А.
© Московская финансово-промышленная академия
Содержание
2. ИНТЕГРИРОВАННАЯ СРЕДА РАЗРАБОТКИ MICROSOFT VISUAL C++ 6.0
2.1. Создание проекта и выполнение программы в Visual C++ 6.0
2.2. Расширения файлов при работе в Visual C++ 6
2.3. Поиск и устранение ошибок в программе
2.5. Основные правила написания и оформления программ
4.3. Порядок вычисления выражений
5.5. Выход из цикла – break, переход на конец цикла – continue
5.7. Операция "запятая" и цикл for
5.8. Оператор перехода на метку goto
7. ПРОИЗВОДНЫЕ (ПОЛЬЗОВАТЕЛЬСКИЕ) ТИПЫ
8.2. Стековая, или локальная, память.
8.3. Динамическая память, или куча
ВВЕДЕНИЕ
Язык С++ (произносится «си-плюс-плюс») является расширением языка С и предназначен для разработки объектно-ориентированных программ. Объектно-ориентированный подход к программированию уместен при создании крупномасштабных многофункциональных программных продуктов. Для написания эффективных объектно-ориентированных программ необходимо свободное владение языком программирования в полном объеме, глубокие знания принципов проектирования и отладки программ, возможностей стандартной и других библиотек и т.д., что выходит за рамки данного курса. В данной дисциплине мы остановимся на процедурном программировании, характерном для языка С (программа, написанная на процедурном языке, состоит из совокупности функций или подпрограмм), но при этом будем использовать средства языка С/С++.
В настоящее время язык С и объектно-ориентированные языки его группы (прежде всего C++, а также Java и C#) являются основными в практическом программировании. Достоинство языка С - это, прежде всего, его простота и лаконичность. Язык С легко учится. Главные понятия языка С, такие, как статические и локальные переменные, массивы, указатели, функции и т.д., максимально приближены к архитектуре реальных компьютеров. Так, указатель - это просто адрес памяти, массив - непрерывная область памяти, локальные переменные - это переменные, расположенные в аппаратном стеке, статические - в статической памяти. Программист, пишущий на С, всегда достаточно точно представляет себе, как созданная им программа будет работать на любой конкретной архитектуре. Другими словами, язык С предоставляет программисту полный контроль над компьютером.
В данном пособии будут приведены лишь основные понятия языка С и C++.
Для разработки программ использовался компилятор Microsoft Visual C ++ 6.0.
1. СТРУКТУРА С++ ПРОГРАММЫ
Любая программа на С++ (программисты используют термин проект) состоит из файлов, которые включают в себя функции, описания и директивы препроцессора. Файлы транслируются С-компилятором независимо друг от друга и затем объединяются программой-построителем задач, в результате чего создается файл с программой, готовой к выполнению. Файлы, содержащие тексты С-программы, называются исходными.
В языке С исходные файлы бывают двух типов:
· заголовочные, или h-файлы;
· файлы реализации, или C-файлы.
Имена заголовочных файлов имеют расширение «.h». Имена файлов реализации имеют расширения «.c» для языка С и «.cpp», «.cxx» или «.cc» для языка C++.
К сожалению, в отличие от языка С, программисты не сумели договориться о едином расширении имен для файлов, содержащих программы на C++. Мы будем использовать расширение «.h» для заголовочных файлов и расширение «.cpp» для файлов реализации.
1.1. Заголовочные файлы
Заголовочные файлы содержат только описания. Прежде всего, это прототипы функций. Прототип функции описывает имя функции, тип возвращаемого значения, число и типы ее аргументов. Сам текст функции в h-файле не содержится. Также в h-файлах описываются имена и типы внешних переменных, константы, новые типы, структуры и т.п. В общем, h-файлы содержат лишь интерфейсы, т.е. информацию, необходимую для использования программ, уже написанных другими программистами (или тем же программистом раньше). Заголовочные файлы лишь сообщают информацию о других программах. При трансляции заголовочных файлов, как правило, никакие объекты не создаются. Например, в заголовочном файле нельзя определить глобальную переменную. Строка описания
int x;
определяющая целочисленную переменную x, является ошибкой. Вместо этого следует использовать описание
extern int x;
означающее, что переменная x определена где-то в файле реализации (в каком – неизвестно). Слово extern (внешняя) лишь сообщает информацию о внешней переменной, но не определяет эту переменную.
1.2. Файлы реализации
Файлы реализации, или C-файлы, содержат тексты функций и определения глобальных переменных. Говоря упрощенно, С-файлы содержат сами программы, а h-файлы – лишь информацию о программах.
Представление исходных текстов в виде заголовочных файлов и файлов реализации необходимо для создания больших проектов, имеющих модульную структуру. Заголовочные файлы служат для передачи информации между модулями. Файлы реализации – это отдельные модули, которые разрабатываются и транслируются независимо друг от друга и объединяются при создании выполняемой программы.
Файлы реализации могут подключать описания, содержащиеся в заголовочных файлах. Сами заголовочные файлы также могут использовать другие заголовочные файлы. Заголовочный файл подключается с помощью директивы препроцессора #include. Например, заголовочный файл <iostream.h>, содержащий описания набора классов для управления операцией ввода-вывода включаются с помощью строки
#include <iostream.h>
(iostream – от слов input/output, -stream – поток ввода/вывода). Имя h-файла записывается в угловых скобках, если этот h-файл является частью стандартной С-библиотеки и расположен в одном из системных каталогов. Имена h-файлов, созданных самим программистом в рамках разрабатываемого проекта и расположенных в текущем каталоге, указываются в двойных кавычках, например,
#include «abcd.h».
1.3.
Препроцессор
Препроцессор – это программа предварительной обработки текста непосредственно перед трансляцией. Команды препроцессора называются директивами. Директивы препроцессора содержат символ диез # в начале строки. Препроцессор используется в основном для подключения h-файлов. В С также очень часто используется директива #define для задания символических имен констант. Так, строка
#define PI 3.14159265
задает символическое имя PI для константы 3.14159265. После этого имя PI можно использовать вместо числового значения. Препроцессор находит все вхождения слова PI в текст и заменяет их на константу. Таким образом, препроцессор осуществляет подмену одного текста другим. Необходимость использования препроцессора всегда свидетельствует о недостаточной выразительности языка. Так, в любом Ассемблере средства препроцессирования используются довольно интенсивно. В С по возможности следует избегать чрезмерного увлечения командами препроцессора – это затрудняет понимание текста программы и зачастую ведет к трудно исправляемым ошибкам. В C++ можно обойтись без использования директив #define для задания констант. Например, в C++ константу PI можно задать с помощью нормального описания
const double PI = 3.14159265.
2. ИНТЕГРИРОВАННАЯ СРЕДА РАЗРАБОТКИ MICROSOFT VISUAL C++ 6.0
Интегрированная среда разработки (Integrated Development Environment, IDE) — это программный продукт, объединяющий текстовый редактор, компилятор, отладчик и справочную систему.
Любая, даже самая маленькая программа в среде Visual C++ всегда оформляется как отдельный проект. Проект — это набор взаимосвязанных исходных файлов и включаемых (заголовочных) файлов, компиляция и компоновка которых позволяет создать исполняемую программу. Рабочая область проекта может содержать любое количество различных проектов, сгруппированных вместе для согласованной разработки: от отдельного приложения до библиотеки функций или целого программного пакета. Для решения наших учебных задач каждая программа будет воплощаться в виде одного проекта, поэтому рабочая область проекта у нас всегда будет содержать лишь один проект.
Главное окно Visual C++ является частью Microsoft Developer Studio — интегрированной среды, общей для Visual C++, Visual J++, Visual FoxPro и некоторых других продуктов.
Developer Studio позволяет строить проекты разных типов, ориентированные на различные сферы применения. Эта студия создана на Windows-платформе, поэтому почти все типы проектов являются оконными Windows-приложениями с соответствующим графическим интерфейсом.
Разработчики студии предусмотрели работу и с так называемыми консольными приложениями. При запуске консольного приложения операционная система создает консольное окно, через которое идет ввод-вывод программы. Внешне это напоминает работу в операционной системе MS-DOS. Этот тип приложения больше всего подходит для изучения C/C++, так как компилируемые программы не смешиваются с «толстым слоем» системных приложений Windows.
2.1. Создание проекта и выполнение программы в Visual C++ 6.0
Вызов Visual C++ 6.0 осуществляется через меню «Пуск» -> «Программы» -> «Microsoft Visual C++ 6.0» ->Microsoft Visual C++ 6.0 (рис.2.1)(на вашем компьютере путь может быть другим):
Рис.2.1
При запуске Visual C++ 6 окно, появившееся на экране будет выглядеть следующим образом (рис. 2.2.).
Приступая к работе над новой программой, необходимо создать проект. Это делается следующим образом:
1. В пункте меню File (Файл) выберите команду New (Новый) (рис. 2.3).
Рис.2.3
2. В появившемся диалоговом окне перейдите на вкладку Projects (Проекты). Укажите тип создаваемого проекта, выделив один из элементов списка (в нашем случае будем выбирать Win32 Console Application (Консольное приложение Win32) (рис. 2. 4).
3. В поле Project name (Имя проекта) введите имя проекта, например, Window(рис. 2. 4).
4. В поле Location (Расположение) задайте путь к папке, в которой будет создан проект (рис. 2.4).
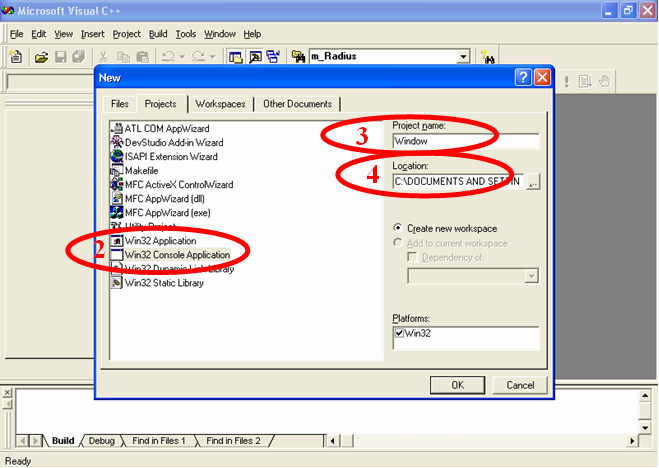
Рис.2.4
5. Нажмите ОК. В появившемся окне (рис. 2.5) выберите An empty project (Пустой проект) и нажмите Finish (Закончить). Нажмите ОК.
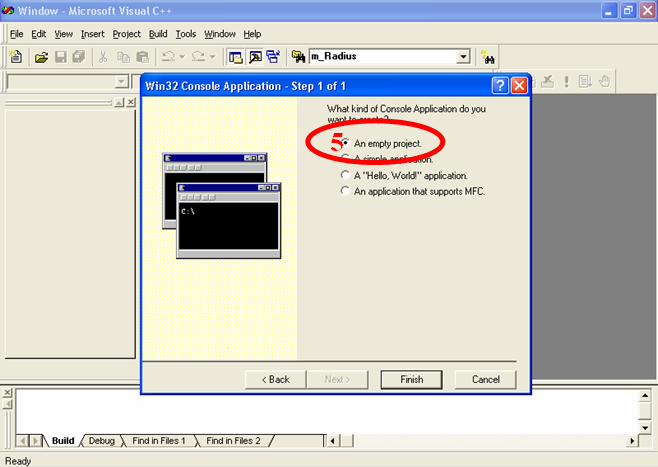
Рис.2.5
6. Выполните команду меню Project ► Add To Project ► New (Проект ► Добавить к проекту ► Новый) (рис. 2.6).
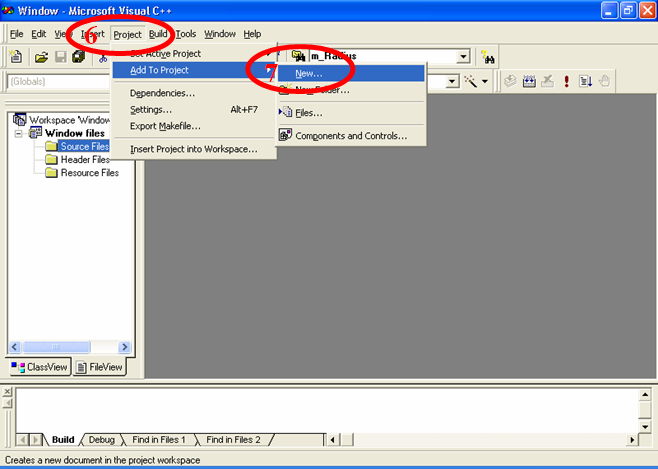
Рис.2.6
7. Откроется окно (рис.2.7), в котором необходимо выбрать из списка C++ Source File (Исходный файл C++). Задайте имя файла в поле File name (Имя файла), например Win. Нажмите ОК.
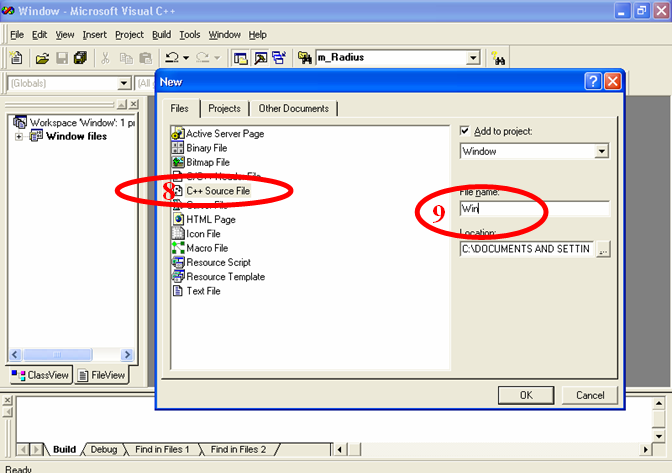
Рис.2.7
8. Теперь наберите в области редактирования программу на языке C++, которая выведет на экран строку: It is my first program!!!
Код программы
// Это моя первая программа на языке C++!!!
#include <iostream.h>
void main()
{
cout << "It is my first program!!!";
}
внимание:
С символа // начинаются комментарии к программе, которые занимают одну строку, а таким образом /*... */ — выделяется блок комментариев.
Набранная программа будет выглядеть так (рис.2.8).
9. Выполните написанную программу, нажав на кнопку компиляции Compile (Компиляция) (сочетание клавиш для выполнения этой операции – Ctrl + F7) и кнопку компоновки Build (Компоновка) («горячая» клавиша F7) из меню Build (Компоновка), а затем на кнопку выполнения Execute Program (Выполнить программу) (сочетание клавиш Ctrl + F5). Кроме того, для выполнения программы можно воспользоваться панелью инструментов Build (рис.2.8).
Если в программе были допущены ошибки, то сообщения о них появятся в окне сообщений.
После этого появится окно с результатами выполнения программы (рис.2.9).
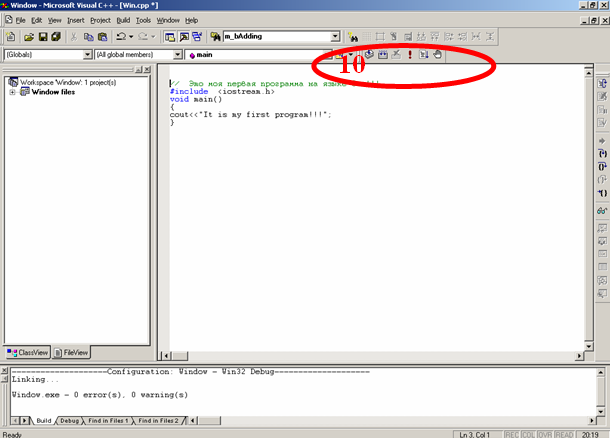
Рис.2.8
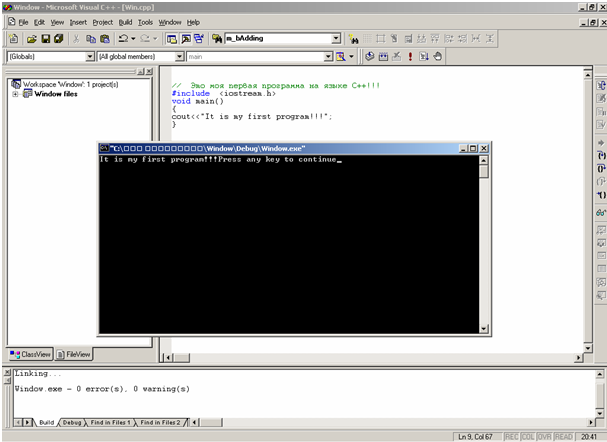
Рис.2.9
внимание:
Компиляция — это процесс преобразования исходной программы на языке программирования в машинные коды. В результате создается объектный модуль.
Компоновка (связывание) — это процесс связывания вместе (сбор в одно целое) всех частей одной программы (объектных, библиотечных модулей), в результате, которого создается готовый к выполнению загрузочный (выполняемый) модуль.
2.2. Расширения файлов при работе в Visual C++ 6
В процессе работы с программой при создании проектов появляется много дополнительных файлов.
В табл. 2.1 представлено описание некоторых типов этих файлов.
Таблица 2.1
Расширения файлов в процессе работы в MS Visual C++ 6
|
Тип файла |
Описание |
|
DSW |
Файл рабочей области |
|
ОРТ |
Файл конфигурации рабочей области |
|
NCB |
Файл справочной информации для утилиты ClassView |
|
DSP |
Файл проекта |
|
СРР |
Исходный файл C++ |
|
Н |
Файл-заголовок C++ |
|
RC |
Исходный файл ресурсов |
|
ТХТ |
Текстовый файл |
|
APS |
Файл справочной информации для утилиты ResourceView |
|
BSC |
Файл справочной информации для утилиты Browser |
|
CLW
|
Файл справочной информации для утилиты ClassWizard (мастер классов), которая предназначена для создания и редактирования классов. В процессе работы мастер классов обращается к информации о классах, определенных в программе. Эти данные хранятся в файле с расширением. clw |
|
МАК
|
Внешний mak-файл (содержит вызовы компилятора и редактора). Этот файл служит для автоматической сборки проекта с помощью утилиты NMake без использования IDE (по параметрам, заданным в командной строке) |
|
PLG |
Файл протокола разработки |
|
OBJ |
Объектный программный файл |
|
RES |
Объектный файл ресурсов |
|
EXE |
Загрузочный файл приложения |
|
DLL |
Загрузочный файл динамической библиотеки (DLL) |
2.3. Поиск и устранение ошибок в программе
Создание программ очень редко обходится без ошибок. Устранение синтаксических ошибок, как правило, не представляет особой проблемы, а вот для выявления и устранения логических можно воспользоваться отладкой программы. Преимущество ее использования состоит в том, что программа может выполняться по шагам, от оператора к оператору. На каждом шаге выполнения программы можно просмотреть информацию о текущем состоянии элементов программы.
Итак, создадим новый проект, в котором будут допущены ошибки. Сам текст программы понятен пока не будет, но наша цель познакомиться с методами поиска программных ошибок в IDE 6 версии. Ниже приводится текст программы, в процессе выполнения которой появляется вопрос: «Вы хотели бы ввести и вывести массив чисел?» Если ответ положительный, то программа предлагает ввести значения элементов массива и распечатывает их, в противном случае она прекращает свою работу.
Код программы
//Программа, содержащая ошибки
#include <iostream.h>
void pr (int i, char continu, int ar[], int l);
void main ()
{
int i, SIZE = 5;
char continu = 0;
int ar[5];
Cout<<"\nWould you like to input and output a number array? (Y/N)";
cin>> continue;
if ( continu == 'Y')
for (i =0; i < size, i++)
{ cout<<\n Input a member of the array\n";
cin>> ar[i];
}
pr (i, continue, ar);
return 0;
}
void pr (int i, char continue, int ar[], int l)
{
for (i = 0; i < last; i++)
cout<< ar[i] <<endl;
Откомпилируйте программу.
Сообщения об ошибках и предупреждения отображаются в окне сообщений (Output — нижнее окно IDE).
Если растянуть окно сообщений за его верхнюю границу, то можно будет увидеть весь перечень ошибок, допущенных в программе.
Каждое сообщение начинается с имени файла, за которым в круглых скобках указан номер строки с ошибкой. Если дважды щелкнуть на сообщении об ошибке, то в области редактирования слева появится синяя стрелочка, указывающая на ошибочную строку.
После номера строки, за двоеточием, идет слово error или warning и номер ошибки.
error — ошибка,
warning — предупреждение.
Разница между error и warning состоит в том, что программы с предупреждениями могут быть выполнены, а программы с ошибками обязательно требуют исправлений.
Предупреждение может появиться, например, в том случае, когда переменной типа int (целое число) в результате некорректного программирования было присвоено дробное значение, тогда выдается предупреждение и автоматически производится округление. Это не означает, что в программе допущена ошибка, но произошло неправильное вычисление, на которое необходимо указать программисту.
В конце каждой строки сообщения дается краткое описание обнаруженной ошибки. Приступим к исправлению ошибок.
1. Первая буква в слове Cout () была ошибочно введена в верхнем регистре. Исправьте ее на маленькую букву. В строке, в которой второй раз встречается слово cout вставьте кавычки ". Сохраните файл и выполните повторную компиляцию.
2. Воспользуйтесь полосой прокрутки в окне сообщений, чтобы подняться вверх (если это необходимо), и дважды щелкните на первом сообщении об ошибке.
В строке, помеченной синей стрелочкой, и далее в программе вместо имени переменной continu, которое применил программист, ошибочно использовалось слово continue. Однако это слово является зарезервированным словом языков C/C++, поэтому заменим continue на continu в теле всей программы. Для этого необходимо выделить первое слово continue, выполнить Edit ► Replace (Правка ► Заменить). Откроется окно, в поле Find what (Найти) которого будет слово continue, а в поле Replace with (Заменить) нужно набрать слово continu.
3. Языки C/C++ чувствительны к регистру символов, поэтому идентификаторы (имена) size и SIZE — это два разных слова, а в описании переменных использовалось SIZE = 5; Итак, замените size на SIZE в строке программы. Выполните компиляцию.
4. Помните, что после двойного щелчка на сообщении об ошибке в окне редактирования появится стрелочка напротив ошибочного оператора, что существенно облегчает отладку программы. Следующее сообщение говорит о том, что в скобках возле слова for следует ввести точку с запятой после SIZE, а не запятую.
5. Остались всего три ошибки.
Первая ошибка говорит о том, что в скобках после слова рг указаны только три параметра, в то время как в других случаях в скобках после этого слова встречаются четыре параметра. Поэтому после аг следует через запятую набрать SIZE.
Вторая ошибка заключается в том, что тип void, стоящий перед main, надо заменить на int т.к. функция main возвращает значение. Третья ошибка говорит о том, что переменная last не была описана, а вместо нее использовалась переменная 1. Замените last на букву 1. Исправленная программа будет выглядеть так:
#include <iostream.h>
void pr (int i, char continu, int ar[], int l);
int main ()
{
int i, SIZE = 5;
char continu = 0;
int ar[5];
cout<<"\nWould you like to input and output a number array? (Y/N)";
cin>> continu;
if ( continu == 'Y')
for (i =0; i <SIZE; i++)
{ cout<<"\n Input a member of the array\n";
cin>> ar[i];
}
pr (i, continu, ar,SIZE);
return 0;
}
void pr (int i, char continu, int ar[], int l)
{
for (i = 0; i < l; i++)
cout<< ar[i]<<endl;
}
Вновь откомпилируйте программу.
В результате получили 0 ошибок и 0 предупреждений.
Выполните программу, нажав кнопку Execute Program (Выполнить программу).
Для ответа на вопрос Would you like to input and output a number array? (Хотите ли Вы ввести и вывести массив чисел?) наберите на клавиатуре Y (от англ. yes — да) и нажмите Enter. На приглашение Input a member of the array (Введите значения в массив) введите целое число и нажмите Enter, и так пять раз.
В результате выполнения программы на экран будут выведены в столбик значения элементов массива:
1
2
3
4
5
Press any key to continue
Фраза Press any key to continue предлагает нажать на любую клавишу для завершения работы программы.
2.4. Отладка программы
Для поиска неочевидных логических ошибок служит встроенный в Visual C++ отладчик (Debugger), при помощи которого можно выполнять трассировку, т. е. выполнить программу пошагово, строка за строкой, при этом можно получать и анализировать значения переменных в любой момент выполнения программы.
Нажмите на кнопку F10, чтобы начать пошаговую отладку. На экране появятся дополнительные окна и желтая стрелка (индикатор трассировки), указывающая на строку программы, которая будет выполнена на следующем шаге.
В окне переменных в процессе пошагового выполнения программы будут отражаться переменные и их значения. В окне просмотра можно набрать в поле Name (Имя) имя интересующей переменной, а в поле Value (Значение) появится ее значение. Окна можно закрывать с помощью крестика, разворачивать по горизонтали при помощи треугольника либо переносить с помощью двух вертикальных черточек.
Обратите внимание, что эти окна появляются только при запуске отладчика.
Красным цветом отражается последнее присвоенное числовое значение. Теперь проделайте следующее.
Знак плюс + рядом с именем переменной в левом нижнем окне означает массив значений. Если щелкнуть на этом знаке, то значения элементов массива раскроются.
Если необходимо выяснить, чему на данном этапе выполнения программы равна какая-либо переменная, то следует набрать ее имя в поле Name. Например, нужно узнать, чему равна переменная SIZE, для этого наберите слово SIZE в поле Name и нажмите Enter.
Для перехода к следующей строке кода нажмите клавишу F10.
Для остановки отладки необходимо выполнить команду: Debug ► Stop Debugging (Отладка ► Остановить отладку).
Наиболее часто применяемые команды отладчика — это Step Over (Внешний переход) («горячая» клавиша F10) и Step Into (Внутренний переход) («горячая» клавиша F11). Различия между ними проявляются только тогда, когда в программе встречается вызов функции. Если выбрать Step Into, то отладчик войдет в функцию, а если Step Over , то выполнит ее как одну команду и перейдет к следующей строке.
При необходимости прервать в определенном месте выполнение программы используют точки останова (Breakpoint). Чтобы их установить, необходимо щелкнуть мышью в нужном месте откомпилированной программы и нажать на кнопку Insert/Remove Breakpoint (Вставить/Удалить точку останова).
Слева от помеченного оператора появится коричневая точка — точка останова.
При выборе команды отладчика Go (Перейти) («горячая» клавиша F5) программа будет выполняться до точки останова.
Чтобы снять точку останова, следует установить курсор на строке с точкой останова и нажать кнопку Insert/Remove Breakpoint.
2.5. Основные правила написания и оформления программ
При написании программ на C/C++ необходимо придерживаться некоторых правил:
1. Каждая программа должна начинаться с комментария, объясняющего ее назначение. Блок комментариев начинается с символов /* и заканчивается */. Комментарии в одну строку оформляются при помощи символов //. Комментарии внутри программы облегчают ее понимание. Также при помощи комментариев разработчики оформляют для себя заметки.
2. Программа должна быть разделена на логические блоки отступами, пробелами и комментариями.
3. Буквы i, j, k,
4. Языки С и C++ чувствительны к регистру буквы, т. е. компилятор распознает прописные и строчные буквы.
5. Хотя длина строки в C++ не ограничена, текст программы не должен выходить за пределы ширины экрана для того, чтобы его было удобно читать и распечатывать.
6. Идентификаторы — это имена, которые присваиваются переменным, константам, типам данных, функциям и т. д. Это последовательность символов произвольной длины, которая может содержать буквы, цифры, знак подчеркивания, но начинаться должна с буквы или знака подчеркивания. Правда, следует избегать использования знака подчеркивания в начале идентификатора, так как компилятор C++ может использовать похожие имена для собственных целей. Также не нужно создавать идентификаторы длиной более 31 символа, так как компилятор распознает только первый 31 символ.
7. Строки, начинающиеся, с символа #, — это директивы препроцессора (предварительной фазы компиляции, т. е. перевода программы с языков C/C++ на машинный язык). Компилятор получает указание присоединить в этом месте программный код, хранящийся, например, в библиотечном файле iostream.h. Файлы с расширением *.h называются файлами заголовков (header). Они обычно содержат объявления различных констант и идентификаторов, а также прототипы функций. В частности, библиотека iostream.h предоставляет различные возможности для операций ввода-вывода. Хранение такого рода информации в отдельном файле облегчает доступ к ней из различных программ и улучшает структурированность программы. Таким образом, при помощи слова include можно присоединять заголовочные файлы, которые позволяют выполнять ввод-вывод данных, работать с математическими данными, строками, преобразовывать данные, распределять память и т. д.
8. Русский алфавит, если нет особой необходимости, применяют только в комментариях.
3. ТИПЫ ДАННЫХ
3.1. Переменные
Программа оперирует информацией, представленной в виде различных объектов и величин. Переменная – это символическое обозначение величины в программе. Как ясно из названия, значение переменной (или величина, которую она обозначает) во время выполнения программы может изменяться.
С точки зрения архитектуры компьютера, переменная – это символическое обозначение ячейки оперативной памяти программы, в которой хранятся данные. Содержимое этой ячейки – это текущее значение переменной.
Каждая переменная имеет имя, тип, размер и значение.
Имя переменной (идентификатор) в прямом смысле является ее названием.
Тип переменной определяет, как числа или символы записаны в ячейку памяти под этим именем, какие возможные значения эта переменная может принимать и какие операции можно выполнять над данной переменной. Размер непосредственно связан с типом, который определяет объем памяти и, следовательно, максимальную величину или точность задания числа. Значение определяет конкретное содержимое ячейки памяти.
Язык С++ – это строго типизированный язык. Любая величина, используемая в программе, принадлежит к какому-либо типу (см. табл. 3.1). При любом использовании переменных в программе проверяется, применимо ли выражение или операция к типу переменной. Довольно часто смысл выражения зависит от типа участвующих в нем переменных.
В языке С++ прежде чем использовать переменную, ее необходимо объявить. Объявить переменную с именем x можно так:
int x;
В объявлении первым стоит название типа переменной int (целое число), а затем идентификатор x – имя переменной. У переменной x есть тип – в данном случае целое число. Тип переменной изменить нельзя, т.е. пока переменная x существует, она всегда будет целого типа.
Например, если мы запишем x+y, где x – объявленная выше переменная, то переменная y должна быть одного из числовых типов.
Соответствие типов проверяется во время компиляции программы. Если компилятор обнаруживает несоответствие типа переменной и ее использования, он выдаст ошибку (или предупреждение). Однако во время выполнения программы типы не проверяются. Такой подход, с одной стороны, позволяет обнаружить и исправить большое количество ошибок на стадии компиляции, а, с другой стороны, не замедляет выполнения программы.
Таблица 3.1.
Характеристики стандартных типов данных языков C/C++
|
Тип данных |
Байт |
Эквивалентные названия |
Диапазон значений |
|
int (целый) |
4(2) |
signed, signed int |
Зависит от системы |
|
unsigned int |
4(2) |
unsigned |
Зависит от системы |
|
int 8 |
1 |
char, signed char |
От-128 до 127 |
|
int l6 |
2 |
short, short int, signed short int |
От -32 768 до 32 767 |
|
int 32 |
4 |
signed, signed int |
От -2 147 483 648 до 2 147 483 647 |
|
int 64 |
8 |
Нет |
От -9 223 372 036 854 775 808 до 9 223 372 036 854 775 807 |
|
char (символьный) |
1 |
signed char |
От-128 до 127 |
|
unsigned char |
1 |
Нет |
От 0 до 255 |
|
short |
2 |
short int, signed short int |
От -32 768 до 32 767 |
|
unsigned short |
2 |
unsigned short int |
От 0 до 65 535 |
|
long |
4 |
long int, signed long int |
От -2 147 483 648 до 2 147 483 647 |
|
unsigned long |
4 |
unsigned long int |
От 0 до 4 294 967 295 |
|
float (вещественный) |
4 |
Нет |
Приблизительно +/-3. 4Е+/-38 (+/-3, 4- 10+/-38) |
|
double (вещественный с двойной точностью) |
8 |
Нет |
Приблизительно +/-1. 8Е+/-308 (+/-1, 8- 10+/-308) |
|
long double |
10 |
Нет |
Приблизительно +/-3. 4Е+/-4932 |
|
bool (логический) |
1 |
Нет |
true и false |
Переменной можно присвоить какое-либо значение с помощью операции присваивания. Присвоить – это значит установить текущее значение переменной. По-другому можно объяснить, что операция присваивания запоминает новое значение в ячейке памяти, которая обозначена переменной.
int x; //объявить целую переменную x
int y; // объявить целую переменную y
x = 0; // присвоить x значение 0
y = x + 1; // присвоить y значение x + 1, т.е. 1
x = 1; // присвоить x значение 1
y = x + 1; // присвоить y значение x + 1, теперь уже 2
3.2. Оператор
sizeof
Переменная одного и того же типа на разных платформах может занимать различное число байтов памяти. Язык С предоставляет программисту возможность получить размер элемента данного типа или размер переменной в байтах, для этого служит оператор sizeof. Аргумент sizeof указывается в круглых скобках, он может быть типом или переменной. Рассмотрим пример.
внимание:
Не следует набирать похожие части программы, используйте для этого буфер обмена.
Код программы:
#include <iostream.h>
void main()
{
char d = '5', dc = '&';
int i = -92, k;
short ii = 58;
long iss = -999;
unsigned char du = '$', is = '33', js = is;
unsigned iu = 667;
unsigned short jjs = 11;
unsigned long jss = 65;
float bl = -1.e+38;
double a = 8.24;
long double al =.1e+149;
// вычисление размера памяти
// осуществляется с помощью функции sizeof()
k = sizeof(d);
cout << "\n" << "Size of the memory for char: " << k << " bytes. ";
k = sizeof(i);
cout << "\n" << "Size of the memory for int: " << k <<" bytes. ";
k = sizeof(ii);
cout << "\n" << "Size of the memory for short: " << k << " bytes. ";
k = sizeof(iss);
cout << "\n" << "Size of the memory for long: " << k << " bytes. ";
cout << "\n" << "Size of the memory for unsigned char: "
<< sizeof(du) << " bytes. ";
cout << "\n" <<"Size of the memory for unsigned: "
<< sizeof(iu) << " bytes. ";
cout << "\n" << "Size of the memory for unsigned short: "
<< sizeof(jjs) << " bytes. ";
cout << "\n" << "Size of the memory for unsigned long: "
<< sizeof (jss) << " bytes. ";
cout << "\n" << "Size of the memory for float: "
<< sizeof (bl) << " bytes. ";
cout << "\n" << "Size of the memory for double: "
<< sizeof(a) << " bytes. ";
cout << "\n" << "Size of the memory for long double: "
<< sizeof(al) << " bytes. ";
cout << "\n" << "Size of the memory of character string: "
<< sizeof("symbol") << " bytes. ";
cout << "\n" << "Size of the memory of character string: "
<< sizeof("A character string ") << " bytes. ";
// действия с символьными переменными
if (d != dc) cout << "\n" << "d != dc";
if (js = = is) cout << "\n" << "js = = is\n";
}
/*
Результаты выполнения программы:
Size of the memory for char: 1 bytes.
Size of the memory for int: 4 bytes.
Size of the memory for short: 2 bytes.
Size of the memory for long: 4 bytes.
Size of the memory for unsigned char: 1 bytes.
Size of the memory for unsigned: 4 bytes.
Size of the memory for unsigned short: 2 bytes.
Size of the memory for unsigned long: 4 bytes.
Size of the memory for float: 4 bytes.
Size of the memory for double: 8 bytes.
Size of the memory for long double: 8 bytes.
Size of the memory of character string: 7 bytes.
Size of the memory of character string: 20 bytes.
d != dc
js = is
Press any key to continue
*/
Обратите внимание на то, что строка "symbol" из-за завершающего строку нулевого символа занимает семь байтов, а не шесть. То же самое касается и другой строки "A character string ". Ее длина не 19 (с учетом всех пробелов), а 20 байтов.
3.3. Базовые типы данных
При рассмотрении типов переменных в С и C++ следует различать понятия базового типа и конструкции (производные типы), позволяющей строить новые типы на основе уже построенных. Базовых типов совсем немного - это целые и вещественные числа, которые могут различаться по диапазону возможных значений (или по длине в байтах) и, в случае языка C++, логический тип. К конструкциям относятся массив, указатель и структура, а также класс в C++.
В языке С++ используются всего два базовых типа: целые и вещественные числа. Кроме того, имеется фиктивный тип void ("пустота"), который применяется либо для функции, не возвращающей никакого значения, либо для описания указателя общего типа (когда неизвестна информации о типе объекта, на который ссылается указатель).
В C++ добавлен логический тип.
3.3.1. Целочисленные типы
Целочисленные типы различаются по длине в байтах и по наличию знака. Их четыре - char, short, int и long. Кроме того, к описанию можно добавлять модификаторы unsigned или signed для беззнаковых (неотрицательных) или знаковых целых чисел.
Тип int
Самый естественный целочисленный тип - это тип int, от слова integer - целое число. Тип int всегда соответствует размеру машинного слова или адреса. Все действия с элементами типа int производятся максимально быстро. Всегда следует выбирать именно тип int, если использование других целочисленных типов не диктуется явно спецификой решаемой задачи. Параметры большинства стандартных функций, работающих с целыми числами или символами, имеют тип int. Примеры описаний переменных типа int:
int x; //объявить целую переменную x
int y=10; //объявить целую переменную y и присвоить значение 10
Целое число может быть непосредственно записано в программе в виде константы. Запись чисел соответствует общепринятой нотации. Примеры целых констант: 0, 125, -37. По умолчанию целые константы принадлежат к типу int. Если необходимо указать, что целое число — это константа типа long, можно добавить символ L или l после числа. Если константа беззнаковая, т.е. относится к типу unsigned long, unsigned short или unsigned int, после числа записывается символ U или u. Например:
34U, 700034L, 7654ul.
Кроме стандартной десятичной записи, числа можно записывать в восьмеричной или шестнадцатеричной системе счисления. Признаком восьмеричной системы счисления является цифра 0 в начале числа. Признаком шестнадцатеричной — 0x или 0X перед числом. Для шестнадцатеричных цифр используются латинские буквы от A до F (неважно, большие или маленькие).
Таким образом, фрагмент программы определяет три целые константы x, y и z с одинаковыми значениями.
Отрицательные числа предваряются знаком минус "-". Приведем еще несколько примеров:
const usigned long ll = 0678; // ошибка в записи восьмеричного числа
const short a = 0xa4; // правильная запись
const int x = 23F3; // ошибка в записи десятичного числа
Для целых чисел определены стандартные арифметические операции сложения (+), вычитания (-), умножения (*), деления (/); нахождение остатка от деления (%), изменение знака (-). Результатом этих операций также является целое число. При делении остаток отбрасывается. Примеры выражений с целыми величинами:
x + 4;
30 - x;
x * 2;
-x;
10 / x;
x % 3;
Кроме типа int, существуют еще три целочисленных типа: char, short и long.
Тип char
Слово "char" является сокращением от character, что в переводе означает "символ".
Для записи знаков в языке С++ служат типы char и unsigned char. Первый – это целое число со знаком, хранящееся в одном байте, второй – беззнаковое байтовое число. Эти типы чаще всего используются для манипулирования символами, поскольку коды символов как раз помещаются в байт. Стандарт С не устанавливает, трактуются ли элементы типа char как знаковые или беззнаковые числа, но большинство С-компиляторов считают char знаковым типом. Примеры описаний переменных типа char:
char c;
char letterA = 'A';
В последнем случае значение переменной "letterA" инициализируется кодом латинской буквы 'A', т.е. целым числом 65.
внимание:
Единственное, что может хранить компьютер, это числа. Поэтому для того чтобы можно было хранить символы и манипулировать ими, символам присвоены коды – целые числа. Существует несколько стандартов, определяющих, какие коды каким символам соответствуют.
Для английского алфавита и знаков препинания используется стандарт ASCII. Этот стандарт определяет коды от 0 до 127. Для представления русских букв используется стандарт КОИ-8 или CP-1251. В этих стандартах русские буквы кодируются числами от 128 до 255. Таким образом, все символы могут быть представлены в одном байте (максимальное число символов в одном байте – 255). В действительности, символы представляются их целочисленными кодами, а код символа занимает один байт. Тем не менее, подчеркнем, что элементы типа char - это именно целые числа, с ними можно выполнять все арифметические операции.
Следующий фрагмент программы выведет все печатные символы ASCII и их коды в порядке увеличения:
for (char c = 32; c < 127; c++)
cout << c << " ";
В С символьные константы записываются в одинарных кавычках (апострофах) и означают коды соответствующих символов в кодировке ASCII. Рассмотрим следующий пример:
char c = 0;char d = '0';
Здесь переменная c инициализируется нулевым значением, а переменная d - значением 48, поскольку символ '0' имеет код 48.
Типы short и long
Слова short и long означают в С короткое и длинное целое число со знаком. Стандарт С не устанавливает конкретных размеров для типов short и long. В самой распространенной в настоящее время 32-разрядной архитектуре переменная типа short занимает 2 байта (диапазон значений - от -32768 до 32767), а тип long совпадает с типом int, размер его равен четырем байтам. Примеры описаний:
short s = 30000;long x = 100000;int y = 100000;
В 32-разрядной архитектуре переменные x и y имеют один и тот же тип.
Модификатор unsigned
Типы int, short и long представляют целые числа со знаком. Для типа char стандарт С не устанавливает явно наличие знака, однако большинство компиляторов трактуют элементы типа char как целые числа со знаком в диапазоне от -128 до 127. Если необходимо трактовать целые числа как неотрицательные, или беззнаковые, следует добавить модификатор unsigned при описании переменных. Примеры:
unsigned char c = 255;unsigned short s = 65535;unsigned int i = 1000000000;unsigned j = 1;
При описании типа "unsigned int" слово "int" можно опускать, что и сделано в последнем примере.
Следует по возможности избегать беззнаковых типов, поскольку арифметика беззнаковых чисел не на всех компьютерах реализована одинаково и из-за этого при переносе программы с одной платформы на другую могут возникнуть проблемы. По этой причине в языке Java беззнаковые числа запрещены.
Имеется также модификатор signed (знаковый). Его имеет смысл использовать на тех платформах, в которых тип char является беззнаковым. Пример описания:
signed char d = (-1);
3.3.2. Вещественные типы
Вещественные числа в С++ могут быть одного из трех типов: с одинарной точностью — float, с двойной точностью – double, и с расширенной точностью – long double.
float x;
double e = 2.9, b = 1e+6, c = 1.5e-3;
long double s;
В большинстве реализаций языка представление и диапазоны значений соответствуют стандарту IEEE (Institute of Electrical and Electronics Engineers) для представления вещественных чисел. Точность представления чисел составляет 7 десятичных значащих цифр для типа float, 15 значащих цифр для double и 19 — для типа long double.
Вещественные числа записываются либо в виде десятичных дробей, например 1.3, 3.1415, 0.0005, либо в виде мантиссы и экспоненты:1.2E0, 0.12e1. Отметим, что обе предыдущие записи изображают одно и то же число 0,12.
По умолчанию вещественная константа принадлежит к типу double.
Чтобы обозначить, что константа на самом деле float, нужно добавить символ f или F после числа: 2.7f. Символ l или L означает, что записанное число относится к типу long double.
const
float pi_f =
const double pi_d = 3.1415;
const long double pi_l = 3.1415L;
Для вещественных чисел определены все стандартные арифметические операции сложения (+), вычитания (-), умножения (*), деления (/) и изменения знака (-).Примеры операций:
2 * pi;
(x – e) / 4.0
Вещественные числа можно сравнивать на равенство (==), неравенство (!=), больше (>), меньше (<), больше или равно (>=) и меньше или равно (<=). В результате операции сравнения получается логическое значение истина или ложь.
Если арифметическая операция применяется к двум вещественным числам разных типов, то менее точное число преобразуется в более точное, т.е. float преобразуется в double и double преобразуется в long double.
Очевидно, что такое преобразование всегда можно выполнить без потери точности.
Если вторым операндом в операции с вещественным числом является целое число, то целое число преобразуется в вещественное представление.
Хотя любую целую величину можно представить в виде вещественного числа, при таком преобразовании возможна потеря точности (для больших чисел).
внимание:
Тип double является основным для компьютера. Тип float - это, скорее, атавизм, оставшийся от ранних версий языка С. Компьютер умеет производить арифметические действия только с элементами типа double, элементы типа float приходится сначала преобразовывать к double. Точность, которую обеспечивает тип float, низка и не достаточна для большинства практических задач. Все стандартные функции математической библиотеки работают только с типом double. Рекомендуем вам никогда не использовать тип float!
3.3.3. Логический тип
В языке С специального логического типа нет, вместо него используются переменные целого типа.
Язык C++ вводит логический тип bool в явном виде. Переменные типа bool принимают два значения: false и true (истина и ложь). Слова false и true являются ключевыми словами языка C++.
Примеры описания логических переменных в C++:
bool a, b;bool c = false, d = true;
Для типа bool определены стандартные логические операции: логическое И (&&), ИЛИ (||) и НЕ (!).
cond1 && cond2; //истинно, если обе переменные, cond1 и cond2, истинны
cond1 || cond2; //истинно, если хотя бы одна из переменных истинна
!cond; //результат противоположен значению cond1
3.3.4. Тип void
Слово void означает "пустота". Тип void в С обозначает отсутствие чего-либо там, где обычно предполагается описание типа. Например, функция, не возвращающая никакого значения, в С описывается как возвращающая значение типа void:
void f(int x);
Другое применение ключевого слова void состоит в описании указателя общего типа, когда заранее не известен тип объекта, на который он будет ссылаться.
3.4. Преобразование типов
Операция приведения типа (type cast) является одной из самых важных в С. Без знакомства с синтаксисом этой операции (весьма непривычного для начинающих) и сознательного ее использования написать на С что-нибудь более или менее полезное невозможно.
Операция приведения типа используется, когда значение одного типа преобразуется к другому типу, в том случае, если существует некоторый разумный способ такого преобразования. Операция обозначается именем типа, заключенным в круглые скобки; она записывается перед ее единственным аргументом. Рассмотрим два примера. Пусть требуется преобразовать целое число к вещественному типу. Как известно, целые и вещественные числа по-разному представляются в компьютере. Тем не менее, существует однозначный способ преобразования целого числа типа int к вещественному типу double. В первом примере значение целой переменной n приводится к вещественному типу и присваивается вещественной переменной x:
double x;int n;. . .x = (double) n; // Операция приведения к типу double
В данном случае никакой потери информации не происходит, поэтому такое приведение допустимо и по умолчанию:
x = n; // Эквивалентно x = (double) n;
Во втором примере вещественное значение преобразуется к целому типу. При этом дробная часть вещественного числа отбрасывается, а знак числа сохраняется:
double x, y;int n, k;. . .x = 3.7;y = (-1.5);n = (int) x; // n присваивается значение 3
k = (int) y; // kприсваивается значение -1
В результате выполнения операции приведения вещественного числа к целому типу происходит отбрасывание дробной части числа, т.е. потеря информации. Поэтому, если использовать операцию приведения типа неявно (т.е. в результате простого присваивания целой переменной вещественного значения), например,
double x; int n;. . .n = x; // неявное приведение вещественного к целому
то компилятор обязательно выдаст предупреждение (или даже ошибку, если компилятор строгий). Поэтому так писать ни в коем случае нельзя! Когда используется явное приведение типа, компилятору сообщается, что это не случайная ошибка, а намеренное приведение вещественного значения к целому типу, при котором дробная часть отбрасывается. При этом компилятор никаких предупреждений не выдает.
Итак, преобразование более «длинного» типа (с большим размером резервируемой памяти) к более «короткому» (с меньшим размером резервируемой памяти) происходит с потерей «лишних» разрядов и, соответственно, с потерей информации (точности). При преобразовании более «короткого» типа к более «длинному» потери информации не происходит.
Преобразование от знакового типа к беззнаковому ведет к потере знака отрицательного числа.
Преобразование символьного типа к числовому заменяет символ на соответствующий ему код, а при обратном преобразовании — возвращает символ.
Код программы
#include <iostream.h>
int main( )
{
char d =' 5', ch;
int i =-92, k;
double a =8.24, b, c = 6.1;
// преобразование типов: "коротких" к "длинным"
b = d;
cout << "\n" << "char d = '5' to double: b = " << b;
k = d;
cout << "\n" << "char d = '5' to int: k = " << k;
b = i;
cout << "\n" << "int I = -92 to double: b = " << b;
// преобразование типов: "длинных" к "коротким"
k = a;
cout << "\n" << "double а = 8.24 to int: k = " << k;
ch = i;
cout << "\n"<< "int i = -92 to char: ch = " << ch;
// преобразование типов в арифметических выражениях
b = c + d + i;
cout << "\n "<<"float 6.1 + char '5' + int -92 = " << b << " (double) \n";
k =c + d + i;
cout << "\n"<< "float 6.1 + char '5' + int -92 = " << k << "(int)\n";
k = (int) c + d + i;
cout << "\n" << "int 6.1 + char '5' + int -92 = " << k << "(int)\n";
return 0;
}
/*
Результаты выполнения программы:
char d = '5' to double: b = 53
char d = '5' to int: k = 53
int I = -92 to double: b = -92
double a = 8. 24 to int: k = 8
int i = -92 to char: ch = д
float 6.1 + char '5' + int -92 = -32. 9(double)
float 6.1 + char '5' + int -92 = -32 (int)
int 6.1 + char '5' + int -92 = -33(int)
Press any key to continue
*/
4. ОПЕРАЦИИ И ВЫРАЖЕНИЯ
4.1. Выражения
Программа оперирует с данными. Числа можно складывать, вычитать, умножать, делить. Знаки можно сравнивать и т.д. То есть из разных величин можно составлять выражения, результат вычисления которых – новая величина. Приведем примеры выражений:
X * 12 + Y //значение X умножить на 12 и к результату прибавить значение Y
val < 3 // сравнить значение val с 3
-9 //константное выражение -9
Выражение, после которого стоит точка с запятой – это оператор-выражение. Его смысл состоит в том, что компьютер должен выполнить все действия, записанные в данном выражении, иначе говоря, вычислить выражение.
x + y – 12; //сложить значения x и y и затем вычесть 12
a = b + 1; //прибавить единицу к значению b
//и запомнить результат в переменной a
Выражения – это переменные, функции и константы, называемые операндами, объединенные знаками операций. Операции могут быть унарными – с одним операндом, например, минус; могут быть бинарные – с двумя операндами, например сложение или деление. В С++ есть даже одна операция с тремя операндами – условное выражение.
В типизированном языке, которым является С++, у переменных и констант есть определенный тип. Есть он и у результата выражения. Например, операции сложения (+), умножения (*), вычитания (-) и деления (/), примененные к целым числам, выполняются по общепринятым математическим правилам и дают в результате целое значение. Те же операции можно применить к вещественным числам и получить вещественное значение.
Операции сравнения: больше (>), меньше (<), равно (==), не равно (!=) сравнивают значения чисел и выдают логическое значение: истина (true) или ложь (false).
4.2. Все операции языка С++
Ниже приводятся все операции языка С++.
Арифметические операции
+ сложение
- вычитание
* умножение
/ деление
Операции сложения, вычитания, умножения и деления целых и вещественных чисел. Результат операции – число, по типу соответствующее большему по разрядности операнду. Например, сложение чисел типа short и long в результате дает число типа long.
% остаток
Операция нахождения остатка от деления одного целого числа на другое. Тип результата – целое число.
- минус
+ плюс
Операция "минус" – это унарная операция, при которой знак числа изменяется на противоположный. Она применима к любым числам со знаком. Операция "плюс" существует для симметрии. Она ничего не делает, т.е. примененная к целому числу, его же и выдает.
Операции инкремента и декремента
Очень часто в программе приходится значение переменной увеличивать или уменьшать на единицу. Для того чтобы сделать эти действия наиболее эффективными и удобными для использования, применяются предусмотренные в С++ операции инкремента ++ (увеличение на 1) и декремента -- (уменьшение на 1).
Существует две формы этих операций: ++j – это префиксная и i++ –постфиксная. В табл. 4. 1 описано использование инкремента и декремента.
Различия между постфиксной и префиксной формами показаны на примере:
к = а + (i++) - d * (--j);
Это равнозначно выполнению операций в следующей последовательности:
--j;
k=a+i-d*j;
i = i++;
Эти операции иногда называют "автоувеличением" и "автоуменьшением". Они увеличивают (или, соответственно, уменьшают) операнд на единицу. Разница между постфиксной (знак операции записывается после операнда, например x++) и префиксной (знак операции записывается перед операндом, например --y) операциями заключается в том, что в первом случае результатом является значение операнда до изменения на единицу, а во втором случае – после изменения на единицу.
Таблица 4.1.
Использование инкремента и декремента
|
Операция |
Название операции |
Пример выражения |
Пояснение |
|
++ |
Префиксная форма инкремента |
++а |
Величина а сначала увеличивается на 1, затем это новое значение а используется в выражении, в котором оно встретилось |
|
++ |
Постфиксная форма инкремента |
а++ |
В выражении используется текущее значение а, а затем величина а увеличивается на 1 |
|
|
Префиксная форма декремента |
--b |
Величина b сначала уменьшается на 1, затем это новое значение b используется в выражении, в котором оно встретилось |
|
— |
Постфиксная форма декремента |
b-- |
В выражении используется текущее значение b, а затем величина b уменьшается на 1 |
Мотивами оптимизации и сокращения записи руководствовались создатели языка С (а затем и С++), когда вводили новые знаки операций типа "выполнить операцию и присвоить". Довольно часто одна и та же переменная используется в левой и правой части операции присваивания, например:
x = x + 5;
y = y * 3;
z = z – (x + y);
В С++ эти выражения можно записать короче:
x += 5;
y *= 3;
z -= x + y;
Т.е. запись oper= означает, что левый операнд вначале используется как левый операнд операции oper, а затем как левый операнд операции присваивания результата операции oper. Кроме краткости выражения, такая запись облегчает оптимизацию программы компилятором.
Операции сравнения
== равно
!= не равно
> меньше
< больше
<= меньше или равно
>= больше или равно
Операции сравнения. Сравнивать можно операнды любого типа, но либо они должны быть оба одного и того же встроенного типа (сравнение на равенство и неравенство работает для двух величин любого типа), либо между ними должна быть определена соответствующая операция сравнения. Результат – логическое значение true или false. Примеры:
bool res;int x, y;res = (x == y); // true, если x равно y, иначе false
res = (x == x); // всегда true
res = (2 < 1); // всегда false
Логические операции
&& логическое «И» (логическое умножение)
|| логическое «ИЛИ» (логическое сложение)
! логическое «НЕ» (логическое отрицание)
Примеры логических выражений:
bool a, b, c, d;int x, y;a = b || c; // логическое "или"
d = b && c; //логическое "и"
a = !b; //логическое "не"
a = (x == y); // сравнение в правой части
a = false; // ложь
b = true; // истина
c = (x > 0 && y != 1); // c истинно, когда оба сравнения истинны
Самый высокий приоритет у операции логического отрицания, затем следует логическое умножение, самый низкий приоритет у логического сложения.
Логические операции конъюнкции, дизъюнкции и отрицания. В качестве операндов выступают логические значения, результат – тоже логическое значение true или false. Они возвращают значение true или false в зависимости от логического отношения между их операндами. Так, оператор && возвращает true, когда истинны (не равны нулю) оба его аргумента. Оператор || возвращает false только в том случае, если ложны (равны нулю) оба его аргумента. Оператор ! просто инвертирует значение своего операнда с false на true и наоборот.
Следующая программа на языке C++ демонстрирует применение операторов сравнения и логических операторов.
Код программы
#include <iostream.h>
int main ()
{
double foperand1, foperand2;
cout << "\n Input foperand1 and foperand2";
cin >> foperand1 >> foperand2;
cout << "foperand1> foperand2="<<(foperand1 > foperand2)<< endl;
cout << "foperand1< foperand2="<<(foperand1 < foperand2)<< endl;
cout << "foperand1>=foperand2="<<(foperand1>= foperand2)<< endl;
cout << "foperand1<=foperand2="<<(foperand1<= foperand2)<< endl;
cout << "foperand1==foperand2="<<(foperand1== foperand2)<< endl;
cout << "foperand1!=foperand2="<<(foperand1!= foperand2)<< endl;
cout<< "foperand1&&foperand2="<<(foperand1&& foperand2)<< endl;
cout << "foperand1 || foperand2="<<(foperand1|| foperand2) <<endl;
cout <<<< endl;
return 0;
}
/*Результаты выполнения программы:
Input foperand1 and foperand2 5. 2 6. 1
foperand1 > foperand2 = 0
foperand1 < foperand2 = 1
foperand1 >= foperand2 = 0
foperand1 <= foperand2 = 1
foperand1 = foperand2 = 0
foperand1 != foperand2 = 1
foperand1 && foperand2 = 1
foperand1 ||
foperand2 = 1
Press any key to continue*/
Условная операция
условие? выражение_1: выражение_2;
Если условие равно true, то выполняется выражение_1, в противном случае — выражение_2. Этот оператор называют тернарным, так как он требует наличия 3 операндов. Первый операнд должен быть логическим значением, второй и третий операнды могут быть любого, но одного и того же, типа, а результат будет того же типа, что и третий операнд. Пример:
(a>=b) ? x=10: x=15;
или, выражение, использующее конструкцию if... else:
if ( 'А' <= с && с <= 'Z' )
cout<<( 'а' + с - 'А' );
else cout<< с;
можно записать иначе:
cout<<( ('А'<=с && с <='Z') ? ('а' + с - 'А') : с);
С помощью этого фрагмента программы происходит преобразование любой прописной или строчной латинской буквы в строчную.
внимание:
обращайте внимание на регистр букв, т. е. большая это буква или маленькая.
В этом примере не рассматривается тот случай, когда вводится какой-либо другой символ, а не буква латинского алфавита.
Рассмотрим следующую программу.
Код программы
/* Эта программа переводит градусы в секунды или радианы. */
#include <iostream.h>
#include<math.h> //заголовочный файл математических
//функций (floor и fabs)
void main()
{
char mark; // метка для выбора радиан или секунд
int i = 1;
double х, z;
const double cc = 3. 1416 / 180. 000;
cout << " \n " << "Input the number in degrees (gradus): ";
cin >> z;
х = fabs(z) * cc; // перевод из градусов в радианы без знака
if (z < 0)
i = -1;
cout << "Input one of the labels r or c: ";
cin >> mark; //ввод метки для определения в радианах или секундах
// Вариант 1
cout << (mark=='r' ? "Output in radians": "Output in seconds") << "\n";
// Вариант 2
mark == 'r' ? cout << "Output in radians":
cout << "Output in seconds";
// Вариант 3
z = (mark == 'r') ? i * x: i * floor (z * 60 * 60 + 0. 5);
cout << "\n" << z << "\n"; // повторное использование переменной z
}
/* Результаты выполнения программы:
Input the number in degrees (gradus): 60
Input one of the labels r or с: с
Output in seconds
Output in seconds
216000
Press any key to continue
*/
Выполнив программу еще раз, получим:
/*Input the number in degrees (gradus): 60
Input one of the labels r or с: r
Output in radians
Output in radians
1. 0472
Press any key to continue*/
4.3. Порядок вычисления выражений
У каждой операции имеется приоритет. Если в выражении несколько операций, то первой будет выполнена операция с более высоким приоритетом. Если же операции одного и того же приоритета, они выполняются слева направо.
Например, в выражении
2 + 3 * 6
сначала будет выполнено умножение, а затем сложение, соответственно, значение этого выражения — число 20.
В выражении
2 * 3 + 4 * 5
сначала будет выполнено умножение, а затем сложение. В каком порядке будет производиться умножение – сначала 2 * 3, а затем 4 * 5 или наоборот, не определено. Т.е. для операции сложения порядок вычисления ее операндов не задан.
В выражении
x = y + 3
вначале выполняется сложение, а затем присваивание, поскольку приоритет операции присваивания ниже, чем приоритет операции сложения.
Для данного правила существует исключение: если в выражении несколько операций присваивания, то они выполняются справа налево.
Например, в выражении
x = y = 2
сначала будет выполнена операция присваивания значения 2 переменной y.Затем результат этой операции – значение 2 – присваивается переменной x.
Ниже приведен список всех операций в порядке понижения приоритета. Операции с одинаковым приоритетом выполняются слева направо (за исключением нескольких операций присваивания).
:: (разрешение области видимости имен)
. (обращение к элементу класса),
->(обращение к элементу класса по указателю),
[] (индексирование), вызов функции,
++ (постфиксное увеличение на единицу),
-- (постфиксное уменьшение на единицу),
typeid (нахождение типа),
dynamic_cast static_cast reinterpret_cast const_cast (преобразования типа)
sizeof (определение размера),
++ (префиксное увеличение на единицу),
-- (префиксное уменьшение на единицу),
~ (битовое НЕ),
! (логическое НЕ),
– (изменение знака),
+ (плюс),
& (взятие адреса),
* (обращение по адресу),
new (создание объекта),
delete (удаление объекта),
(type) (преобразование типа)
.* ->* (обращение по указателю на элемент класса)
* (умножение),
/ (деление),
% (остаток)
+ (сложение),
– (вычитание)
<< , >> (сдвиг)
< <= > >= (сравнения на больше или меньше)
== != (равно, неравно)
& (поразрядное И)
^ (поразрядное исключающее ИЛИ)
| (поразрядное ИЛИ)
&& (логическое И)
|| (логическое ИЛИ)
= (присваивание),
*= /= %= += -= <<= >>= &= |= ^= (выполнить операцию и присвоить)
?: (условная операция)
throw , (последовательность)
Для того чтобы изменить последовательность вычисления выражений, можно воспользоваться круглыми скобками. Часть выражения, заключенная в скобки, вычисляется в первую очередь. Значением
(2 + 3) * 6
будет 30.
Скобки могут быть вложенными, соответственно, самые внутренние выполняются первыми:
(2 + (3 * (4 + 5) ) – 2)
5. УПРАВЛЯЮЩИЕ КОНСТРУКЦИИ
Управляющие конструкции позволяют организовывать циклы и ветвления в программах. В С всего несколько конструкций, причем половину из них можно не использовать (они реализуются через остальные).
5.1. Фигурные скобки
Фигурные скобки позволяют объединить несколько элементарных операторов в один составной оператор, или блок. Во всех синтаксических конструкциях составной оператор можно использовать вместо простого.
В С в начало блока можно помещать описания локальных переменных. Локальные переменные, описанные внутри блока, создаются при входе в блок и уничтожаются при выходе из него.
В C++ локальные переменные можно описывать где угодно, а не только в начале блока. Тем не менее, они, так же как и в С, автоматически уничтожаются при выходе из блока.
Приведем фрагмент программы, обменивающий значения двух вещественных переменных:
double x, y;. . .{ double tmp = x;x = y;
y = tmp;}
Здесь, чтобы обменять значения двух переменных x и y, мы сначала запоминаем значение x во вспомогательной переменной tmp. Затем в x записывается значение y, а в y - сохраненное в tmp предыдущее значение x. Поскольку переменная tmp нужна только внутри этого фрагмента, мы заключили его в блок и описали переменную tmp внутри этого блока. По выходу из блока память, занятая переменной tmp, будет освобождена.
5.2.
Оператор if
Оператор if ("если") позволяет организовать ветвление в программе. Он имеет две формы: оператор "если" и оператор "если...иначе". Оператор "если" имеет вид
if (условие)
действие;
оператор "если...иначе" имеет вид
if (условие)
действие1;
elseдействие2;
В качестве условия можно использовать любое выражение логического или целого типа. Напомним, что при использовании целочисленного выражения значению "истина" соответствует любое ненулевое значение. При выполнении оператора "если" сначала вычисляется условное выражение после if. Если оно истинно, то выполняется действие, если ложно, то ничего не происходит. Например, в следующем фрагменте в переменную m записывается максимальное из значений переменных x и y:
double x, y, m;. . .m = x;if (y > x) m = y;пример:код программы: #include <iostream.h>
int main(){ int x, abs; cout << " Vvedite znachenie x = "; cin >> x; if (x<0) x=-x; abs = x; cout << endl << " Modul chisla = " << abs << endl;return 0;}
При выполнении оператора "если...иначе" в случае, когда условие истинно, выполняется действие, записанное после if; в противном случае выполняется действие после else. Например, предыдущий фрагмент переписывается следующим образом:
double x, y, m;. . .if (x > y) m = x;else m = y;пример:
код программы:
#include <iostream.h>
int main()
{
int x, y, a;
cout << " Vvedite znachenie x = "; cin >> x;
cout << " Vvedite znachenie y = "; cin >> y;
if (x>y)
a=x;
else
a=y;
cout << endl << " MAX znachenie a = " << a << endl;
// cout.flush();
return 0;
}
Когда надо выполнить несколько действий в зависимости от истинности условия, следует использовать фигурные скобки, объединяя несколько операторов в блок, например,
double x, y, d;. . .if (d > 1.0) {x /= d;
y /= d;}
Здесь переменные x и y делятся на d только в том случае, когда значение d больше единицы.
Фигурные скобки можно использовать даже, когда после if или else стоит только один оператор. Они улучшают структуру текста программы и облегчают ее возможную модификацию. Пример:
double x, y;. . .if (x != 0.0) { y = 1.0;}
Если нужно будет добавить еще одно действие, выполняемое при условии "x отлично от нуля", то мы просто добавим строку внутри фигурных скобок.
#include <iostream.h>
int main()
{
int x, y, a;
cout << " Vvedite znachenie x = "; cin >> x;
cout << " Vvedite znachenie y = "; cin >> y;
if (x>y)
a=x;
else
a=y;
cout << endl << " MAX znachenie a = " << a << endl;
// cout.flush();
return 0;
}
Пример: решение квадратного уравнения
Рассмотрим простой пример, в котором применяется конструкция "если...иначе": требуется решить квадратное уравнение
ax2+bx+c = 0
Программа должна ввести с клавиатуры терминала числа a, b, c и затем напечатать ответ. После ввода надо проверить корректность введенных чисел - коэффициент a должен быть отличен от нуля (иначе уравнение перестает быть квадратным, тогда формула решения квадратного уравнения неприменима). В зависимости от знака дискриминанта уравнение может не иметь решений. Программа должна напечатать либо сообщение об отсутствии решений, либо два корня уравнения (возможно, совпадающие в случае нулевого дискриминанта).
Для печати на экран терминала и ввода информации с клавиатуры используются функции ввода-вывода из стандартной библиотеки С. Отметим, что функции стандартного ввода-вывода не являются частью языка С: С(как и С++) не содержит средств ввода-вывода. Однако любой компилятор обычно предоставляет набор библиотек, в который входит стандартный ввод-вывод. Описания функций ввода-вывода содержатся в заголовочном файле stdio.h, который подключается с помощью строки
#include <stdio.h>
Мы используем две функции: функцию printf вывода по формату и функцию scanf ввода по формату. У обеих этих функций число аргументов переменное, первым аргументом всегда является форматная строка. В случае функции printf обычные символы форматной строки просто выводятся на экран терминала. Например, в рассмотренном ранее примере "Hello, World!" текст выводился на экран с помощью строки программы
printf("Hello, World!\n");
(Здесь '\n' - символ конца строки, т.е. перевода курсора в начало следующей строки.) Единственным аргументом функции printf в данном случае служит форматная строка.
Кроме обычных символов, форматная строка может включать символы формата, которые при выводе заменяются значениями остальных аргументов функции printf, начиная со второго аргумента. Для каждого типа данных С имеются свои форматы. Формат начинается с символа процента '%'. После процента идет необязательный числовой аргумент, управляющий представлением данных. Наконец, далее идет одна или несколько букв, задающих тип выводимых на печать данных. Для вывода чисел можно использовать следующие форматы:
%d вывод целого числа типа int (d - от decimal)
%lf вывод вещ. числа типа double (lf - от long float)
Например, для печати целого числа n можно использовать строку
printf("n = %d\n", n);
Здесь формат "%d" будет заменен на значение переменной n. Пусть, к примеру, n = 15. Тогда при выполнении функции printf будет напечатана строка
n = 15
При печати вещественного числа компьютер сам решает, сколько знаков после десятичной точки следует напечатать. Если нужно повлиять на представление числа, следует использовать необязательную часть формата. Например, формат
%.3lf
применяется для печати значения вещественного числа в форме с тремя цифрами после десятичной точки. Пусть значение вещественной переменной x равно единице. Тогда при выполнении функции
printf("ответ = %.3lf\n", x);
будет напечатана строка
ответ = 1.000
При вызове функции форматного ввода scanf форматная строка должна содержать только форматы. Этим функция scanf отличается от printf. Вместо значений печатаемых переменных или выражений, как в функции printf, функция scanf должна содержать указатели на вводимые переменные! Для начинающих это постоянный источник ошибок. Необходимо запомнить: функции scanf нужно передавать адреса переменных, в которые надо записать введенные значения. Если вместо адресов переменных передать их значения, то функция scanf все равно проинтерпретирует полученные значения как адреса, что при выполнении вызовет попытку записи по некорректным адресам памяти и, скорее всего, приведет к ошибке типа Segmentation fault. Пример: пусть нужно ввести значения трех вещественных переменных a, b, c. Тогда следует использовать фрагмент
scanf("%lf%lf%lf", &a, &b, &c);
Ошибка, которую часто совершают начинающие: передача функции scanf значений переменных вместо адресов:
scanf("%lf%lf%lf", a, b, c); // Ошибка! Передаются
// значения вместо указателей
Помимо стандартной библиотеки ввода-вывода, в С-программах широко используется стандартная библиотека математических функций. Ее описания содержатся в стандартном заголовочном файле math.h, который подключается строкой
#include <math.h>
Стандартная математическая библиотека содержит математические функции sin, cos, exp, log (натуральный логарифм), fabs (абсолютная величина вещественного числа) и многие другие. Нам необходима функция sqrt, вычисляющая квадратный корень вещественного числа.
Кроме того, в программу включена функция Rus, использование которой позволяет преодолеть проблемы, вызванные различными стандартами кодировки символов кириллицы в операционных системах MS DOS и Windows.
Итак, приведем полный текст программы, решающей квадратное уравнение:
#include <stdio.h> // Описания стандартного ввода-вывода
#include <math.h> // Описания математической библиотеки
#include <windows.h>// Описания API функций Windows
char BufRus [256]; // Буфер для хранения строки
char* Rus(const char* text) // Функция русификатор, преобразующая
//кодировку кириллицы из ANSI в ASCII
{CharToOem(text,BufRus);return BufRus;} int main() {double a, b, c; // Коэффициенты уравнения
double d; // Дискриминант
double x1, x2; // Корни уравнения
printf(Rus("Введите коэффициенты a, b, c:\n"));
scanf("%lf%lf%lf", &a, &b, &c);
if (a == 0.0) {
printf(Rus("Коэффициент a должен быть ненулевым.\n"));
return 1; // Возвращаем код некорректного завершения
}
d = b*b - 4.0*a*c; // Вычисляем дискриминант
if (d < 0.0) {
printf("Решений нет.\n");
}
else {
d = sqrt(d); // Квадр. корень из дискриминанта
x1 = (-b + d) / (2.0 * a); // Первый корень ур-я
x2 = (-b - d) / (2.0 * a); // Второй корень ур-я
// Печатаем ответ
printf(Rus("Решения уравнения: x1 = %lf, x2 = %lf\n",x1, x2)); }return 0; // Возвращаем код успешного завершения
}
Приведем пример выполнения программы:
Введите коэффициенты a, b, c:1 2 -3Решения уравнения: x1 = 1.000000, x2 = -3.000000
Здесь первая и третья строчки напечатаны компьютером, вторая строчка напечатана человеком (ввод чисел заканчивается клавишей перевода строки Enter).
Вложенные операторы (конструкция if...else if...)
Несколько условных операторов типа "если...иначе" можно записывать последовательно (т.е. действие после else может снова представлять собой условный оператор). В результате реализуется выбор из нескольких возможностей. Конструкция выбора используется в программировании очень часто. Пример: дана вещественная переменная x, требуется записать в вещественную переменную y значение функции sign(x):
sign(x) = -1, при x < 0sign(x) = 1, при x > 0sign(x) = 0, при x = 0
Это делается с использованием конструкции выбора:
double x, s;. . .if (x < 0.0) { s = (-1.0);}else if (x > 0.0) { s = 1.0;}else {s = 0.0;
}
При выполнении этого фрагмента сначала проверяется условие x < 0.0. Если оно истинно, то выполняется оператор s = (-1.0); иначе проверяется второе условие x < 0.0. В случае его истинности выполняется оператор s = 1.0, иначе выполняется оператор s = 0.0. Фигурные скобки здесь добавлены для улучшения структурности текста программы.
В любом случае, в результате выполнения конструкции выбора исполняется лишь один из операторов (возможно, составных). Условия проверяются последовательно сверху вниз. Как только находится истинное условие, то производится соответствующее действие и выбор заканчивается.
Рассмотрим, как написать программу для вычисления значений у и z по формулам:
при известном значении х. Ввод х необходимо предусмотреть с клавиатуры.
Код программы
/* программа, использующая разветвляющийся алгоритм. */
#include <iostream.h> // заголовочный файл для организации ввода-вывода в C++
#include <math.h> // заголовочный файл для работы с математическими функциями
int main()
{
double x, y, z;
cout << "\n Input x: \n";
cin >> x;
if (x <= 9)
y = pow(x, 3) - 6.5;
else
y = sqrt(x +8.7) + 5.2;
cout << "y = "<< y << "\n";
if (y < 8)
z = y;
else if(y ==8)
z= pow(y, 2);
else
z = pow (y, 3);
cout<<"z = "<<z<<"\n";
return 0;
}
/*
Результаты выполнения программы:
Input x: 2
у = 1. 5.
z = 1. 5
Press any key to continue
*/
При повторном выполнении программы:
Input x: 10
у = 9. 52435 z = 863. 985
Press any key to continue
Обратите внимание на то, что очень распространенной ошибкой при написании программ, имеющих тройное условие, является использование подобного фрагмента для вычисления z; if (у < 8) z = у; if (у ==8) z =pow(y, 2); else z = pow(y, 3);
Что здесь не так? Проследите, какое значение получит z, если у<8. В этом случае используют либо три if с сокращенной формой записи, либо один if с вложенным в него if, но не два независимых if.
5.3. Инструкция switch
Если необходимо применить несколько операторов if, то удобнее использовать инструкцию множественного выбора switch:
switch (выражение)
{
case Constant_l:[операторы_1;] [break;]
case Constant_2:[операторы_2;] [break;]
case Constant_3:[операторы_3;] [break;]
case Constant_N:[операторы_N;] [break;]
[default: действия по умолчанию;]
Эта инструкция используется для выбора одного из многих путей. Она проверяет, совпадает ли значение выражения с одним из значений констант, и выполняет соответствующую значению ветвь инструкции. Каждая ветвь case может быть помечена одной или несколькими целочисленными константами или выражениями. Константы всех ветвей должны отличаться друг от друга. Если ни одна из ветвей не подходит, то выполняется ветвь default, если такая имеется, в противном случае ничего не делается. Ветви case и default можно располагать в любом порядке.
Рассмотрим описанную структуру:
· квадратные скобки означают, что указанное выражение может присутствовать, а может и не присутствовать в данной структуре;
· выражение — это выражение, результатом выполнения которого должно быть значение целого типа или символ;
· Constant_N — это константное выражение, в том числе целая или символьная константа;
· break — прерывание, необязательный оператор завершения выполнения оператора switch;
· default — ключевое слово, после которого стоят операторы, выполняющиеся, если результат выражения не совпал ни с одной константой после ключевого слова case.
Рассмотрим пример.
Код программы
/*Даны два числа а и b. Вычислите сумму, разность, произведение или частное этих чисел. Выбор действия организовать с помощью оператора switch. Программа написана на C++. */
#include <iostream.h>
void main ()
{
float a, b, c; char znak;
cout << "Input a, b: " << "\n";
cin >> a >> b;
cout << "Input znak: " << "\n";
cin >> znak;
switch (znak)
{
case ' + ' : с = a + b; cout << c; break;
case '-' : с = a - b; cout << c; break;
case '*' : с = a * b; cout << c; break;
case '/' : с = a / b; cout << c; break;
default: cout << "There is a mistake!!! "; break;
}
cout << "\n";,
}
/* Результаты выполнения программы: Input a, b:
5 6
Input znak:
+
11
Press any key to continue
*/
Выполним программу еще раз:
Input a, b: -8 7
Input znak:
*
-56
Press any key to continue
Выполним программу еще раз:
Input a, b:
5 8
Input znak:
d
There is a mistake!!!
Press any key to continue
5.4. Цикл while
Конструкция цикла "пока" соответствует циклу while в С:
while (условие) действие;
Цикл while называют циклом с предусловием, поскольку условие проверяется перед выполнением тела цикла.
Цикл while выполняется следующим образом: сначала проверяется условие. Если оно истинно, то выполняется действие. Затем снова проверяется условие; если оно истинно, то снова повторяется действие, и так до бесконечности. Цикл завершается, когда условие становится ложным. Пример:
int n, p;. . .p = 1;while (2*p <= n) p *= 2;
В результате выполнения этого фрагмента в переменной p будет вычислена максимальная степень двойки, не превосходящая целого положительного числа n.
Если условие ложно с самого начала, то действие не выполняется ни разу. Это очень облегчает программирование и делает программу более надежной, поскольку исключительные ситуации автоматически правильно обрабатываются. Так, приведенный выше фрагмент работает корректно при n = 1 (цикл не выполняется ни разу).
При ошибке программирования цикл может никогда не кончиться. Чтобы избежать этого, следует составлять программу таким образом, чтобы некоторая ограниченная величина, от которой прямо или косвенно зависит условие в заголовке цикла, монотонно убывала или возрастала после каждого выполнения тела цикла. Это обеспечивает завершение цикла. В приведенном выше фрагменте такой величиной является значение p, которое возрастает вдвое после каждого выполнения тела цикла.
Тело цикла может состоять из одного или нескольких операторов. В последнем случае их надо заключить в фигурные скобки. Советуем заключать тело цикла в фигурные скобки даже в том случае, когда оно состоит всего из одного оператора, - это делает текст программы более наглядным и облегчает его возможную модификацию. Например, приведенный выше фрагмент лучше было бы записать так:
int n, p;. . .p = 1;while (2*p <= n) { p *= 2;}Пример: программа выводит на экран числа от 1 до 10
Код программы
#include <iostream.h>
void main()
{
int i = 1;
while (i <= 10)
{
cout << i << " ";
i++; } }
/*
Результаты выполнения программы:
1 2 3 4 5 6 7 8 9 10
Press any key to continue
*/
5.5.
Выход из цикла – break, переход на конец цикла – continue
Если необходимо прервать выполнение цикла, следует использовать оператор
break;
Оператор break применяется внутри тела цикла, заключенного в фигурные скобки. Пример: требуется найти корень целочисленной функции f(x), определенной для целочисленных аргументов.
int f(int x); // Описание прототипа функции
. . .int x;. . .// Ищем корень функции f(x)x = 0;while (true) { if (f(x) == 0) {break; // Нашли корень
}// Переходим к следующему целому значению x
// в порядке 0, -1, 1, -2, 2, -3, 3, ...
if (x >= 0) { x = (-x - 1);}
else { x = (-x); }}// Утверждение: f(x) == 0
Здесь используется бесконечный цикл "while (true)". Выход из цикла осуществляется с помощью оператора "break".
Иногда требуется пропустить выполнение тела цикла при каких-либо значениях изменяющихся в цикле переменных, переходя к следующему набору значений и очередной итерации. Для этого используется оператор
continue;
Оператор continue, так же, как и break, используется лишь в том случае, когда тело цикла состоит более чем из одного оператора и заключено в фигурные скобки. Его следует понимать как переход на фигурную скобку, закрывающую тело цикла.
5.6. Цикл
for
Популярный в других языках программирования арифметический цикл (см. с. 41) в языке С реализуется с помощью цикла for. Он выглядит следующим образом:
for (инициализация; условие продолжения; итератор) тело цикла;
Инициализация выполняется один раз перед первой проверкой условия продолжения и первым выполнением тела цикла. Условие продолжения проверяется перед каждым выполнением тела цикла. Если условие истинно, то выполняется тело цикла, иначе цикл завершается. Итератор выполняется после каждого выполнения тела цикла (перед следующей проверкой условия продолжения).
Поскольку условие продолжения проверяется перед выполнением тела цикла, цикл for является, подобно циклу while, циклом с предусловием. Если условие продолжения не выполняется изначально, то тело цикла не выполняется ни разу, а это хорошо как с точки зрения надежности программы, так и с точки зрения простоты и эстетики (поскольку не нужно отдельно рассматривать исключительные случаи).
Рассмотрим пример суммирования массива с использованием цикла for:
double a[100]; // Массив a содержит не более 100 эл-тов
int n; // Реальная длина массива a (n <= 100)
double sum; // Переменная для суммы эл-тов массива
int i; // Переменная цикла
. . .sum = 0.0;for (i = 0; i < n; ++i) {sum += a[i]; // Увеличиваем сумму на a[i]
}
Здесь целочисленная переменная i используется в качестве переменной цикла. В операторе инициализации переменной i присваивается значение 0. Условием продолжения цикла является условие i<n. Итератор ++i увеличивает переменную i на единицу. Таким образом, переменная i последовательно принимает значения 0, 1, 2,..., n-1. Для каждого значения i выполняется тело цикла.
В большинстве других языков программирования арифметический цикл жестко связан с использованием переменной цикла, которая должна принимать значения из арифметической прогрессии. В С это не так, здесь инициализация, условие продолжения и итератор могут быть произвольными выражениями, что обеспечивает гораздо большую гибкость программы. Конструкцию цикла for можно реализовать с помощью цикла while.
Например, фрагмент с суммированием массива реализуется с использованием цикла while следующим образом:
for (i=0; i < n; ++i) { sum += a[i]; } |
i = 0;while (i < n) {… sum += a[i];++i; } |
В принципе, конструкция цикла for не нужна: она реализуется с помощью цикла while, он проще и понятнее. Однако большинство программистов продолжают использовать цикл for. Связано это, скорее всего, с традицией и привычками, поскольку в более ранних языках программирования, например, в первых версиях Фортрана, арифметический цикл был основным, а цикл while приходилось реализовывать с помощью операторов if и goto.
Рассмотрим следующий пример. Необходимо вычислить
Код программы
#include <iostream.h>
void main()
{
int x = 0; // описание и инициализация
for (int i = 1; i <= 10; i++)
{
x = x + i;
cout << x << " ";
}
}
/*
Результаты выполнения программы:
1 3 6 10 15 21 28 36 45 55
Press any key to continue
*/
5.7.
Операция "запятая" и цикл for
В цикле for
for (инициализация; условие продолжения; итератор) тело цикла;
в качестве инициализации и итератора можно использовать любые выражения, в частности, операцию присваивания = и операцию увеличения значения переменной на единицу ++. Как быть, если необходимо выполнить несколько действий при инициализации или в итераторе? Можно, конечно, использовать цикл while, но любители цикла for поступают другим образом. Для этого язык С предоставляет операцию "запятая", которая позволяет объединить несколько выражений в одно. У операции "запятая" два аргумента, которые вычисляются последовательно слева направо. Результатом операции является последнее вычисленное, т.е. правое, значение. Пример:
int x, y, z;x = 5;z = (y = x + 10, ++x); // y = 15, x = 6, z = 6
Здесь при вычислении выражения в скобках сначала вычисляется первое подвыражение y = x+10, в результате которого в y записывается значение 15, значение первого подвыражения также равно 15. Затем вычисляется стоящее после запятой второе подвыражение ++x, в результате чего значение x увеличивается и становится равным 6, значение второго подвыражения также равно 6. Значением операции "запятая" является значение второго подвыражения, т.е. 6. В результате значение 6 присваивается переменной z.
Наличие
операции "запятая" отражает эстетскую
сторону первоначального варианта языка C 70-х годов XX века: в нем почти любая
запись имела какой-то смысл. Позже программисты пришли к пониманию того, что
надежность программы важнее краткости и изящества, и приняли более строгий ANSI-стандарт языка С
Тем не менее, операцию "запятая" по-прежнему можно использовать в заголовке цикла for, когда нужно выполнить несколько действий при инициализации или в итераторе. Например, фрагмент суммирования массива
sum = 0.0;for (i = 0; i < n; ++i) { sum += a[i];}
можно переписать следующим "эстетским" образом:
for (sum = 0.0, i = 0; i < n; sum += a[i], ++i);
Здесь тело цикла вообще пустое, все действия вынесены в заголовок цикла! Лучше избегать такого стиля программирования: он ничего не добавляет в смысле эффективности готовой программы, но делает текст менее понятным и, таким образом, увеличивает вероятность ошибок.
5.8.
Оператор перехода на метку goto
Оператор перехода goto позволяет изменить естественный порядок выполнения программы и осуществить переход на другой участок программы, обозначенный меткой. Переход может осуществляться только внутри функции, т.е. оператор goto не может ни выйти из функции, ни войти внутрь другой функции. Оператор goto выглядит следующим образом:
L: ...;. . .goto L;
В качестве метки можно использовать любое имя, допустимое в С (т.е. последовательность букв, цифр и знаков подчеркивания "_", начинающуюся не с цифры). Метка может стоять до или после оператора goto. Метка выделяется символом двоеточия ":". Лучше после него сразу ставить точку с запятой ";", помечая таким образом пустой оператор - это общепринятая программистская практика, согласно которой метки ставятся между операторами, а не на операторах.
Не следует увлекаться использованием оператора goto - это всегда запутывает программу. Большинство программистов считают применение оператора goto дурным стилем программирования. Вместо goto при необходимости можно использовать операторы выхода из цикла break и пропуска итерации цикла continue. Единственная ситуация, в которой использование goto оправдано, - это выход из нескольких вложенных друг в друга циклов:
while (...) { . . . while (...) { . . . if (...) {goto LExit; // Выход из двух
// вложенных циклов
} . . . }}LExit: ;
5.9. Оператор возврата return
Оператор return завершает выполнение функции и возвращает управление в ту точку, откуда она была вызвана. Его форма:
return выражение;
Где выражение – это результат функции. Если функция не возвращает никакого значения, то оператор возврата имеет форму return.
6. ФУНКЦИИ
Функции – это основные единицы построения программ при процедурном программировании на языке С++. По сути, функция – это подпрограмма, которая может оперировать данными и возвращать значение (например – результат каких либо вычислений). Программа на языке С++ состоит, по крайней мере, из одной функции – функции main. С нее всегда начинается выполнение программы. К функции можно обратиться по имени, передать ей значения и получить из нее результат. Функции нужны для упрощения структуры программы, т.е. можно разбить сложную задачу на более мелкие и простые подзадачи и оформить каждую из них в виде функции. Передача в функцию различных аргументов позволяет, записав ее один раз, использовать многократно для разных данных.
Пример: вычисление наибольшего общего делителя
Программа вводит с клавиатуры два целых числа, затем вычисляет и печатает их наибольший общий делитель. Непосредственно вычисление наибольшего общего делителя реализовано в виде отдельной функции
int gcd(int x, int y);
(gcd - от слов greatest common divizor). Основная функция main лишь вводит исходные данные, вызывает функцию gcd и печатает ответ. Описание прототипа функции gcd располагается в начале текста программы, затем следует функция main, из которой производится вызов функции gcd и в конце - реализация (определение) функции gcd.
Код программы:
#include <iostream.h> // Описания стандартного ввода-вывода
int gcd(int x, int y); // Описание прототипа функции
int main() {
int x, y, d;
cout<<"Enter two value:\n";cin>> x>>y;
d = gcd(x, y); // Вызов функции
cout<<" GCD = "<< d<<endl;
return 0;} int gcd(int x, int y) { // Реализация функции gcd
while (y != 0) {
// Инвариант: НОД(x, y) не меняется
int r = x % y; // Заменяем пару (x, y) на
x = y; // пару (y, r), где r --
y = r; // остаток от деления x на y
}// Утверждение: y == 0
return x; // НОД(x, 0) = x
}
Стоит отметить, что реализация функции gcd располагается в конце текста программы. Можно было бы расположить реализацию функции в начале текста и при этом сэкономить на описании прототипа. Это, однако, дурной стиль! Лучше всегда, не задумываясь, описывать прототипы всех функций в начале текста, ведь функции могут вызывать друг друга, и правильно упорядочить их (чтобы вызываемая функция была реализована раньше вызывающей) во многих случаях невозможно. К тому же предпочтительнее, чтобы основная функция main, с которой начинается выполнение программы, была бы реализована раньше функций, которые из нее вызываются.
6.1. Прототипы функций
Объявление функции называют прототипом функции. Перед использованием или реализацией функции необходимо описать ее прототип. Прототип функции сообщает информацию об имени функции, типе возвращаемого значения, количестве и типах ее аргументов (параметров). Например:
double sqrt(double x); // функция sqrt с одним аргументом –
//вещественным числом двойной точности х,
//возвращает результат типа double
int sum(int a, int b, int c); // функция sum от трех целых
//аргументов возвращает целое число
Если в функции не предусмотрен возврат значения, то перед именем функции должно указываться void. После имени функции в скобках указываются ее параметры. Параметр — это информация, передаваемая функции для обработки. Если функция не имеет параметров, то внутри круглых скобок указывается или void, или ничего.
Описание прототипа функции располагается обычно в начале текста программы.
6.2. Вызов функций
Использование функции часто называют вызовом функции. Функция вызывается при «вычислении» выражений. Например:
double x = sqrt(3); // переменной х присваивается значение,
//полученное в результате вычисления
// квадратного корня из трех
cout<<sum( k, l, m) / 15; // на монитор будет выведен результат
//вычислений функции sum, деленный на 15
Если функция не возвращает никакого результата, т.е. она объявлена как void, ее вызов не может быть использован как операнд более сложного выражения, а должен быть записан сам по себе:
func(a,b,c);
Встретив имя функции в функции main, программа вызовет эту функцию, т.е. передаст управление на ее начало (в определении функции) и начнет выполнять операторы. Достигнув конца функции или оператора return – выхода из функции, управление вернется в ту точку, откуда функция была вызвана, подставив вместо нее вычисленный результат (если функция возвращает значение).
6.3. Определение функции
Определение функции описывает, как она работает, т.е. какие действия надо выполнить, чтобы получить искомый результат. Для функции sum, объявленной выше, определение может выглядеть следующим образом:
int sum( int a, int b, int c)
{
int result;
result = a + b + c;
return result;
}
Первая строка – это заголовок функции, он совпадает с объявлением функции, за исключением того, что объявление заканчивается точкой с запятой. Далее в фигурных скобках заключено тело функции – действия, которые данная функция выполняет.
Аргументы a, b и c называются формальными параметрами. Это переменные, которые определены в теле функции (т.е. к ним можно обращаться только внутри фигурных скобок). При написании определения функции программа не знает их значения. При вызове функции вместо них подставляются фактические параметры – значения, с которыми функция вызывается. Выше, в примере вызова функции sum, фактическими параметрами (или фактическими аргументами) являлись значения переменных k, l и m.
Формальные параметры принимают значения фактических аргументов, заданных при вызове, и функция выполняется.
Первое, что мы делаем в теле функции — объявляем внутреннюю переменную result типа целое. Переменные, объявленные в теле функции, также называют локальными. Это связано с тем, что переменная result существует только во время выполнения тела функции sum. После завершения выполнения функции она уничтожается – ее имя становится неизвестным, и память, занимаемая этой переменной, освобождается.
Вторая строка определения тела функции – вычисление результата. Сумма всех аргументов присваивается переменной result. Отметим, что до присваивания значение result было неопределенным (то есть значение переменной было неким произвольным числом, которое нельзя определить заранее).
Последняя строчка функции возвращает в качестве результата вычисленное значение. Оператор return завершает выполнение функции и возвращает выражение, записанное после ключевого слова return, в качестве выходного значения. Приведем полный текст программы вычисляющей сумму трех целых чисел в отдельной функции:
#include <iostream.h> // Описания стандартного ввода-вывода
int sum( int a, int b, int c); // Описание прототипа функции
int main() { int x, y, d, res;cout<<"Enter 3 value:\n";cin>> x>>y>>d;res=sum(x,y,d); // Вызов функции
cout<<" Summa = "<< res <<endl;return 0;} int sum( int a, int b, int c) // Реализация (определение) функции
{
int result;
result = a + b + c;
return result;
}
6.4. Функция main
В языках C/C++ стандартное имя main (с англ., основной, главный) используется для определения первого выполняемого оператора программы. В действительности main является функцией, так что если имеются сомнения относительно типов операций, которые могут быть выполнены внутри функций, то применяется достаточно простое правило: все, что допустимо в main, допустимо и в любой другой функции. Точно так же, как переменные объявляются в main, они могут быть объявлены и в создаваемых функциях. Кроме того, в функциях могут также использоваться такие конструкции языка, как if, while, for. Наконец, одна функция может вызывать другие функции. Например, в следующей программе используются две функции. Сначала main вызывает функцию three_hellos, в которой трижды вызывается функция hello_world.
Код программы
#include <stdio.h>
void hello_world()
{
printf("Hello world! !!\n");
void three_hellos ()
{
int counter;
for (counter = 1; counter <= 3; counter++)
hello_world();
}
void main ()
{
three_hellos ();
}
/* .
Результат выполнения программы:
Hello world!!!
Hello world!!!
Hello world!!!
Press any key to continue
*/
7. ПРОИЗВОДНЫЕ (ПОЛЬЗОВАТЕЛЬСКИЕ) ТИПЫ
Для создания новых типов в С можно использовать конструкции массива, указателя и структуры.
7.1. Массивы
Массив – это совокупность нескольких величин одного и того же типа, объединенных под одним именем.
Описание массива в С состоит из имени базового типа, названия массива и его размера, который указывается в квадратных скобках. Размер массива обязательно должен быть целочисленной константой или константным выражением. Примеры:
int a[10];char c[256];double d[1000];
В первой строке описан массив целых чисел из 10 элементов. Подчеркнем, что нумерация в С всегда начинается с нуля, так что индексы элементов массива изменяются в пределах от 0 до 9. Во второй строке описан массив символов из 256 элементов (индексы в пределах 0...255), в третьей - массив вещественных чисел из 1000 элементов (индексы в пределах 0...999).
Оператор sizeof возвращает размер всего массива в байтах, а не в элементах массива. В данном примере:
sizeof(a) = 10*sizeof(int) = 40, sizeof(c) = 256*sizeof(char) = 256, sizeof(d) = 1000*sizeof(double) = 8000.
Рассмотрим пример массива, состоящий из двенадцати целых чисел, соответствующих числу дней в каждом календарном месяце:
int days[12];
days[0] = 31; // январь
days[1] = 28; // февраль
days[2] = 31; // март
days[3] = 30; // апрель
days[4] = 31; // май
days[5] = 30; // июнь
days[6] = 31; // июль
days[7] = 31; // август
days[8] = 30; // сентябрь
days[9] = 31; // октябрь
days[10] = 30; // ноябрь
days[11] = 31; // декабрь
В первой строчке мы объявили массив из 12 элементов типа int и дали ему имя days. Остальные строки примера – присваивания значений элементам массива. Для того, чтобы обратиться к определенному элементу массива, используют операцию индексации []. Как видно из примера, первый элемент массива имеет индекс 0, соответственно, последний – 11.
При объявлении массива его размер должен быть известен в момент компиляции, поэтому в качестве размера можно указывать только целую константу. При обращении же к элементу массива в роли значения индекса может выступать любая переменная или выражение, которое вычисляется во время выполнения программы и преобразуется к целому значению.
Предположим, мы хотим распечатать все элементы массива days. Для этого удобно воспользоваться циклом for.
for (int i = 0; i < 12; i++) {
cout << days[i];
}
Следует отметить, что при выполнении программы границы массива не контролируются. Если мы ошиблись и вместо 12 в приведенном выше цикле написали 13, то компилятор не выдаст ошибку. При выполнении программа попытается напечатать 13-е число. Что при этом случится, вообще говоря, не определено. Быть может, произойдет сбой программы. Более вероятно, что будет напечатано какое-то случайное 13-е число. Выход индексов за границы массива – довольно распространенная ошибка, которую иногда очень трудно обнаружить. В дальнейшем при изучении классов мы рассмотрим, как можно переопределить операцию [] и добавить контроль за индексами.
Отсутствие контроля индексов налагает на программиста большую ответственность. С другой стороны, индексация – настолько часто используемая операция, что наличие контроля, несомненно, повлияло бы на производительность программ.
В приведенных примерах у массивов имеется только один индекс. Такие одномерные массивы часто называются векторами. Имеется возможность определить массивы с несколькими индексами или размерностями.
Например, объявление
int m[10][5];
представляет матрицу целых чисел размером 10 на 5. По-другому интерпретировать приведенное выше объявление можно как массив из 10 элементов, каждый из которых – вектор целых чисел длиной 5. Общее количество целых чисел в массиве m равно 50.
Обращение к элементам многомерных массивов аналогично обращению к элементам векторов: m[1][2] обращается к третьему элементу второй строки матрицы m.
Количество размерностей в массиве может быть произвольным. Как и в случае с вектором, при объявлении многомерного массива все его размеры должны быть заданы константами.
При объявлении массива можно присвоить начальные значения его элементам (инициализировать массив). Для вектора это будет выглядеть следующим образом:
int days[12] = { 31, 28, 31, 30, 31, 31, 30, 31, 30, 31 };
При инициализации многомерных массивов каждая размерность должна быть заключена в фигурные скобки:
double temp[2][3] = {{ 3.2, 3.3, 3.4 },
{ 4.1, 3.9, 3.9 } };
Интересной особенностью инициализации многомерных массивов является возможность не задавать размеры всех измерений массива, кроме самого последнего. Приведенный выше пример можно переписать так:
double temp[][3] = {{ 3.2, 3.3, 3.4 },
{ 4.1, 3.9, 3.9 } };
7.2. Структуры
Структуры – это совокупность нескольких величин любого типа, разрешенного в языке С/С++, объединенных под одним именем. В них могут храниться данные различных типов. Этим они отличаются от массивов.
Традиционным примером структуры является учетная карточка работающего: "служащий" описывается набором атрибутов таких, как фамилия, имя, отчество (ф.и.о.), адрес, код социального обеспечения, зарплата и т.д. Некоторые из этих атрибутов сами могут оказаться структурами: ф.и.о. имеет несколько компонент, как и адрес, и даже зарплата.
Структуры оказываются полезными при организации сложных данных особенно в больших программах, поскольку во многих ситуациях они позволяют сгруппировать связанные данные таким образом, что с ними можно обращаться, как с одним целым, а не как с отдельными объектами.Структуры могут быть вложенными.
Описание структуры выглядит следующим образом:
struct имя_структуры {
описание полей структуры};
Ключевое слово struct указывает на начало определения структуры. Здесь имя_структуры — это любое имя, соответствующее синтаксису языка С, описания полей структуры — любая последовательность описаний переменных, имена и типы этих переменных могут быть произвольными. Эти переменные называются полями структуры. Заканчивается описание структуры закрывающей фигурной скобкой. За закрывающей фигурной скобкой в описании структуры обязательно следует точка с запятой, в отличие от конструкции составного оператора, не следует забывать об этом!
Пример структуры: учетная карточка служащего может фактически выглядеть так:
struct Person
{
char name[namesize]; //символьный массив для ввода имени служащего
char address[adrsize];
long zipcode; /* почтовый индекс */
long ss_number; /* код соц. обеспечения */
double salary; /* зарплата */
struct date birthdate; /* дата рождения */
struct date hiredate; /* дата поступления на работу */
};
За ключевым словом struct следует имя структуры – Person. Имя структуры называют также меткой (tag). В фигурных скобках находится описания переменных – полей структуры (char name[namesize]; long zipcode; и т.д.).
В приведенном примере описан новый тип данных – структурный тип Person. Чтобы использовать структуру в программе необходимо объявить переменную структурного типа, называемого экземпляром структурного типа – например Worker.
struct Person Worker;
Отдельные поля структуры могут использоваться как простые переменные. Для обращения к полям структуры применяется операция « . » . Пример:
Worker.name[namesize]=”Max”;
Экземпляр структуры может быть массивом – например:
struct Rect{
double x;
double y;
};
….
struct Rect coord[10];
Обратиться к атрибутам переменной coord[] можно coord[0].x – обращение к полю х первого элемента массива coord[] и coord [2] .y – обращение к полю у первого элемента массива coord[].
При объявлении структуры можно присвоить начальные значения ее полям (инициализировать структуру). Это будет выглядеть следующим образом:
struct Rect{
double x;
double y;
} coord ={8.3, 4.3};
Затем в программе полям можно присвоить новые значения:
coord.x=3.4;
coord.у=5.4;
Возможны и более сложные комбинации, например, структура A содержит указатель на структуру B, а структура B — указатель на структуру A (указатели описаны в следующем пункте). В этом случае можно использовать предварительное описание структуры, например, строка
struct A;
просто сообщает компилятору, что имя A является именем структуры, полное определение которой будет дано ниже. Тогда упомянутое описание двух структур A и B, ссылающихся друг на друга, может выглядеть следующим образом:
struct A; // Предварительное описание структуры A
struct B; // Предварительное описание структуры B
struct A { // Определение структуры A
. . .struct B *p; // Указатель на структуру B
. . . }; struct B { // Определение структуры B
. . .struct A *q; // Указатель на структуру A
. . . };
Для доступа к полям структуры через указатель на структуру служит операция стрелочка, которая обозначается двумя символами −> (минус и знак больше), их нужно рассматривать как одну неразрывную лексему (т.е. единый знак, единое слово). Пусть S — имя структуры, f — некоторое поле структуры S, p — указатель на структуру S. Тогда выражение
p−>f
обозначает поле f структуры S (само поле, а не указатель не него!). Это выражение можно записать, используя операцию звездочка (доступ к объекту через указатель), т.е. запись
p−>f эквивалентна (*p).f
но, конечно, первый способ гораздо нагляднее. (Во втором случае круглые скобки вокруг выражения *p обязательны, поскольку приоритет операции точка выше, чем операции звездочка.)
7.3. Указатели
Указатель - это переменная, содержащая адрес другой переменной. Указатели - фамильная принадлежность языка С. В неявном виде указатели присутствовали и в других языках программирования, но в С они используются гораздо чаще, а работа с указателями организована максимально просто.
При описании указателя надо задать тип объектов, адреса которых будут содержаться в нем. Перед именем указателя при описании ставится звездочка, чтобы отличить его от обычной переменной. Примеры описаний указателей:
int *a, *b, c, d;char *e;void *f;
В первой строке описаны указатели a и b на тип int и простые переменные c и d типа int (c и d - не указатели!).
С указателями возможны следующие два действия:
1. присвоить указателю адрес некоторой переменной. Для этого используется операция взятия адреса, которая обозначается амперсандом &. Например, строка
a = &c;
присваивает указателю a значение адреса переменной c;
2. получить значение переменной, адрес которой содержится в указателе; для этого используется операция звездочка '*' (называемая операцией разадресации), которая записывается перед указателем. (Заметим, что звездочкой обозначается также операция умножения.) Например, строка
d = *a;
присваивает переменной d значение целочисленной переменной, адрес которой содержится в a. Так как ранее указателю a был присвоен адрес переменной c, то в результате переменной d присваивается значение c, т.е. данная строка эквивалентна следующей:
d = c;
Указатели могут входить в выражения. Например, если a указывает на целое c, то *a может появляться в любом контексте, где может встретиться c. Так оператор
d = *a + 1
присваивает d значение, на 1 большее значения c;
cout<< *a;
печатает текущее значение c.
И наконец, так как указатели являются переменными, то с ними можно обращаться, как и с остальными переменными. Если b - другой указатель на переменную типа INT, то
b= a;
копирует содержимое a в b, в результате чего b указывает на то же, что и a т.е на с.
В языке "C" существует сильная взаимосвязь между указателями и массивами, настолько сильная, что указатели и массивы действительно следует рассматривать одновременно. Любую операцию, которую можно выполнить с помощью индексов массива, можно сделать и с помощью указателей. Вариант с указателями обычно оказывается более быстрым, но и несколько более трудным для непосредственного понимания, по крайней мере для начинающего. Описание
int A[10];
определяет массив из 10 целочисленных элементов, т.е. набор из 10 последовательных объектов, называемых A[0], A[1], ..., A[9]. Запись A[i] соответствует элементу массива через i позиций от начала. Если pA - указатель на целое, описанный как
int *pA;
то присваивание
pA = &A[0];
приводит к тому, что pA указывает на первый элемент массива A; это означает, что pA содержит адрес элемента A[0]. Теперь присваивание
d = *pA;
будет копировать содержимое A[0] в d.
Если pA указывает на некоторый определенный элемент массива A, то по определению pA+1 указывает на следующий элемент, и вообще pA-i указывает на элемент, стоящий на i позиций до элемента, указываемого pA, а pA+i на элемент, стоящий на i позиций после. Таким образом, если pA указывает на A[0], то
*(pA+1)
ссылается на содержимое A[1], pA+i – адрес A[i], а *( pA+i) – содержимое A[i].
Эти замечания справедливы независимо от типа переменных в массиве A. Суть определения "добавления 1 к указателю", а также его распространения на всю арифметику указателей, состоит в том, что приращение масштабируется размером памяти, занимаемой объектом, на который указывает указатель. Таким образом, i в pA+i перед прибавлением умножается на размер объектов, на которые указывает pA.
Очевидно существует очень тесное соответствие между индексацией и арифметикой указателей. в действительности компилятор преобразует ссылку на массив в указатель на начало массива. В результате этого имя массива является указательным выражением. Отсюда вытекает несколько весьма полезных следствий. Так как имя массива является синонимом местоположения его нулевого элемента, то присваивание pA=&A[0] можно записать как
pA = A;
Еще более удивительным, по крайней мере на первый взгляд, кажется тот факт, что ссылку на A[i] можно записать в виде *(A+i).
С другой стороны, если pA является указателем, то в выражениях его можно использовать с индексом: pA[i] идентично *(pA+i). Короче, любое выражение, включающее массивы и индексы, может быть записано через указатели и смещения и наоборот, причем даже в одном и том же утверждении.
Арифметика указателей
С указателями можно выполнять следующие операции:
· сложение указателя и целого числа, результат - указатель;
· автоувеличение или автоуменьшение переменной типа указатель, что эквивалентно прибавлению или вычитанию единицы;
· вычитание двух указателей, результат - целое число.
Прибавление к указателю p целого числа n означает увеличение адреса, который содержится в переменной p, на суммарный размер n элементов того типа, на который ссылается указатель. Указатель как бы сдвигается на n элементов вправо, если считать, что индексы элементов массива возрастают слева направо. Аналогично вычитание целого числа n из указателя означает сдвиг указателя влево на n элементов. Пример:
int *p, *q;int a[100];p = &(a[5]); // записываем в p адрес 5-го
// элемента массива a
p += 7; // p будет содержать адрес 12-го эл-та
q = &(a[10]);--q; // q содержит адрес элемента a[9]
Значение указателя при прибавлении к нему целого числа n увеличивается на произведение n на количество байтов, занимаемое одним элементом того типа, на который ссылается указатель. В программировании это называют масштабированием.
Разность двух указателей - это количество элементов данного типа, которое умещается между двумя адресами. Результатом вычитания указателей является целое число. Физически оно вычисляется как разность значений двух адресов, деленная на размер одного элемента заданного типа. Операции сложения указателя с целым числом и разности двух указателей взаимнообратны:
int *p, *q;int a[100];int n;p = &(a[5]);q = &(a[12]);n = q - p; // n == 7
q = p + n; // q == &(a[12])
Подчеркнем, что указатели нельзя складывать! В отличие от разности указателей, операция сложения указателей (т.е. сложения адресов памяти) абсолютно бессмысленна.
int *p, *q, *r;int a[100];p = &(a[5]);q = &(a[12]);r = p + q; // Ошибка! Указатели нельзя складывать.
7.4. Сложные описания
Конструкции массива и указателя при описании типа можно применять многократно в произвольном порядке. Кроме того, можно описывать прототип функции. Таким образом можно строить сложные описания вроде "массив указателей", "указатель на указатель", "указатель на массив", "функция, возвращающая значение типа указатель", "указатель на функцию" и т.д. Правила здесь таковы:
· для группировки можно использовать круглые скобки, например, описание
int *(x[10]);
означает "массив из 10 элементов типа указатель на int";
· при отсутствии скобок приоритеты конструкций описания распределены следующим образом: операция * определения указателя имеет самый низкий приоритет. Например, описание
int *x[10];
означает "массив из 10 элементов типа указатель на int". Здесь к имени переменной x сначала применяется операция определения массива [] (квадратные скобки), поскольку она имеет более высокий приоритет, чем звездочка. Затем к полученному массиву применяется операция определения указателя. В результате получается "массив указателей", а не указатель на массив! Если нам нужно определить указатель на массив, то следует использовать круглые скобки при описании:
int (*x)[10];
Здесь к имени x сначала применяется операция * определения указателя;
· операции определения массива [] (квадратные скобки после имени) и определения функции (круглые скобки после имени) имеют одинаковый приоритет, более высокий, чем звездочка. Примеры:
int f();
описан прототип функции f без аргументов, возвращающей значение типа int.
int (*f())[10];
описан прототип функции f без аргументов, возвращающей значение типа указатель на массив из 10 элементов типа int;
Последний пример уже не является очевидным. Общий алгоритм разбора сложного описания можно охарактеризовать как чтение изнутри. Сначала находим описываемое имя. Затем определяем, какая операция применяется к имени первой. Если нет круглых скобок для группировки, то это либо определение указателя (звездочка слева от имени), либо определение массива (квадратные скобки справа от имени), либо определение функции (круглые скобки справа от имени). Таким образом получается первый шаг сложного описания. Затем находим следующую операцию описания, которая применяется к уже выделенной части сложного описания, и повторяем это до тех пор, пока не исчерпаем все описание. Проиллюстрируем этот алгоритм на примере:
void (*a[100])(int x);
описывается переменная a. К ней сначала применяется операция описания массива из 100 элементов, далее - определение указателя, далее - функция от одного целочисленного аргумента x типа int, наконец - определение возвращаемого типа int. Описание читается следующим образом:
1. a - это
2. массив из 100 элементов типа
3. указатель на
4. функцию с одним аргументом x типа int, возвращающую значение типа
5. void.
Ниже расставлены номера операций в порядке их применения в описании переменной a:
void (* a [100])(int x);5) 3) 1) 2) 4)
7.5. Строки
Специального типа данных строка в С нет. Строки представляются массивами символов (а символы - их числовыми кодами). Последним символом массива, представляющего строку, должен быть символ с нулевым кодом. Пример:
char str[10];str[0] = 'e'; str[1] = '2';str[2] = 'e'; str[3] = '4';str[4] = 0;
Описан массив str из 10 символов, который может представлять строку длиной не более 9, поскольку один элемент должен быть зарезервирован для терминирующего нуля. Далее в массив str записывается строка "e2e4". Строка терминируется нулевым символом. Всего запись строки использует 5 первых элементов массива str с индексами 0...4. Последние 5 элементов массива не используются. Массив можно инициализировать непосредственно при описании, например
char t[] = "abc";
Здесь мы не указываем в квадратных скобках размер массива t, компилятор его вычисляет сам. После операции присваивания записана строковая константа "abc", которая заносится в массив t. В результате компилятор создает массив t из четырех элементов, поскольку на строку отводится 4 байта, включая терминирующий ноль.
Строковые константы заключаются в С в двойные апострофы, в отличие от символьных, которые заключаются в одинарные. Значением строковой константы является адрес ее первого символа. Когда компилятор встречает строковую константу в программе, он записывает ее текст в область статической памяти, обычно защищенную от изменения, и использует этот адрес. Например, в результате следующего описания
const char *s = "abcd";
создается указатель s, а также строка символов "abcd", строка помещается в область статической памяти, защищенную от изменения, а в указатель s помещается адрес начала строки. Строка содержит 5 элементов: коды символов abcd и терминирующий нулевой байт.
7.6. Модификатор
const
Константы в С/++ можно задавать двумя способами:
· с помощью директивы #define препроцессора. Например, строка
#define MILLENIUM 1000
задает символическое имя MILLENIUM для константы 1000. Препроцессор всюду в тексте заменяет это имя на константу 1000, используя текстовую подстановку. Это не очень хороший способ, поскольку при таком задании отсутствует контроль типов;
· с помощью модификатора const. При описании любой переменной можно добавить модификатор типа const. Например, вместо #define можно использовать следующее описание:
const int MILLENIUM = 1000;
Модификатор const означает, что переменная MILLENIUM является константой, т.е. менять ее значение нельзя. Попытка присвоить новое значение константе приведет к ошибке компиляции:
MILLENIUM = 100; // Ошибка: константу нельзя изменять
При описании указателя модификатор const, записанный до звездочки, означает, что описан указатель на константный объект, т.е. на объект, менять который нельзя или запрещено. Например, в строке
const char *p;
описан указатель на константную строку (массив символов, менять который запрещено).
Указатели на константные объекты используются в С чрезвычайно часто. Причина состоит в том, что константный указатель позволяет прочесть объект и при этом гарантирует, что объект не будет испорчен в результате ошибки программирования, т.к. константный указатель не дает возможности изменить объект.
Константный указатель ссылается на константный объект, однако, содержимое самого указателя может изменяться. Например, следующий фрагмент вполне корректен:
const char *str = "e2e4";. . .str = "c7c5";
Здесь константный указатель str сначала содержит адрес константной строки "e2e4". Затем в него записывается адрес другой константной строки "c7c5".
В С можно также описать указатель, значение которого не может быть изменено; для этого модификатор const указывается после звездочки. Например, фрагмент кода
int i;int * const p = &i;
навечно записывает в указатель p адрес переменной i, перенаправить указатель p на другую переменную уже нельзя. Строка
p = &n;
является ошибкой, т.к. указатель p - константа, а константе нельзя присвоить новое значение. Указатели, значения которых изменять нельзя, используются в С значительно реже, в основном при заполнении константных таблиц.
7.7. Оператор
typedef
В языке С можно задать имя типа, если его описание достаточно громоздко и его не хочется повторять много раз. В дальнейшем можно использовать имя типа при описании переменных. Для определения типа применяется оператор typedef. Синтаксически оператор typedef аналогичен обычному описанию переменной, к которому в самом начале добавлено слово typedef. При этом вместо переменной определяется имя нового типа. Сравните следующее описание переменной "real" и определение нового типа "Real":
double real; // Описание переменной real
typedef double Real; // Определение нового типа Real,
// эквивалентного типу double.
Мы как бы описываем переменную, добавляя к описанию слово typedef. При этом описываемое имя становится именем нового типа. Его можно использовать затем для задания переменных:
Real x, y, z;
Чаще всего определение типов с помощью typedef используют, когда описание типа достаточно громоздко. Оператор typedef позволяет задать его только один раз, что облегчает исправление программы при необходимости. Например, следующая строка определяет тип callback как указатель на функцию с одним целым параметром, возвращающую значение логического типа:
typedef bool (*callback)(int);
Строка, описывающая три переменные p, g, r,
callback p, q, r;
эквивалентна строке
bool (*p)(int), (*q)(int), (*r)(int);
но первая строка, конечно, понятнее и нагляднее.
Еще одна цель использования оператора typedef состоит в том, чтобы сделать текст программы менее зависимым от особенностей конкретной архитектуры (разрядности процессора, конкретного С-компилятора и т.п.). Например, в старых С-компиляторах, которые использовались для 16-разрядных процессоров Intel 80286, существовали так называемые близкие (near) и далекие (far) указатели. В эталонном языке С ключевых слов near и far нет, они использовались лишь в С-компиляторах для Intel 80286 как расширение языка. Поэтому, чтобы тексты программ не зависели от компилятора, в системных h-файлах с помощью оператора typedef определялись имена для типов указателей, а в текстах программ использовались не типы эталонного языка С, а введенные имена типов. Например, тип "далекий указатель на константную строку" в соответствии с соглашениями фирмы Microsoft называется LPCTSTR (Long Pointer to Constant Text STRing). При использовании 16-разрядного компилятора он определяется в системных h-файлах как
typedef const char far *LPCTSTR;
в 32-разрядной архитектуре он определяется без ключевого слова far (поскольку в ней все указатели "далекие"):
typedef const char *LPCTSTR;
Во всех программах указатели на константные строки описываются как имеющие тип LPCTSTR:
LPCTSTR s;
благодаря
этому программы Microsoft можно использовать как в 16-разрядной, так и в
32-разрядной архитектуре.
8. РАБОТА С ПАМЯТЬЮ
В традиционных языках программирования существуют три вида памяти: статическая, стековая и динамическая. Конечно, с физической точки зрения никаких различных видов памяти нет: оперативная память - это массив байтов, каждый байт имеет адрес, начиная с нуля. Когда говорится о видах памяти, имеются в виду способы организации работы с ней, включая выделение и освобождение памяти, а также методы доступа.
8.1. Статическая память
Статическая память выделяется еще до начала работы программы, на стадии компиляции и сборки. Статические переменные имеют фиксированный адрес, известный до запуска программы и не изменяющийся в процессе ее работы. Статические переменные создаются и инициализируются до входа в функцию main, с которой начинается выполнение программы.
Существует два типа статических переменных:
· глобальные переменные - это переменные, определенные вне функций, в описании которых отсутствует слово static. Обычно описания глобальных переменных, включающие слово extern, выносятся в заголовочные файлы (h-файлы). Слово extern означает, что переменная описывается, но не создается в данной точке программы. Определения глобальных переменных, т.е. описания без слова extern, помещаются в файлы реализации (c-файлы или cpp-файлы). Пример: глобальная переменная maxind описывается дважды:
в h-файле с помощью строки:
extern int maxind;
это описание сообщает о наличии такой переменной, но не создает эту переменную!
В cpp-файле с помощью строки:
int maxind = 1000;
это описание создает переменную maxind и присваивает ей начальное значение 1000. Заметим, что стандарт языка не требует обязательного присвоения начальных значений глобальным переменным, но, тем не менее, это лучше делать всегда, иначе в переменной будет содержаться непредсказуемое значение (мусор, как говорят программисты). Инициализация всех глобальных переменных при их определении - это правило хорошего стиля.
Глобальные переменные называются так потому, что они доступны в любой точке программы во всех ее файлах. Поэтому имена глобальных переменных должны быть достаточно длинными, чтобы избежать случайного совпадения имен двух разных переменных. Например, имена x или n для глобальной переменной не подходят;
· статические переменные - это переменные, в описании которых присутствует слово static. Как правило, статические переменные описываются вне функций. Такие статические переменные во всем подобны глобальным, с одним исключением: область видимости статической переменной ограничена одним файлом, внутри которого она определена, - и, более того, ее можно использовать только после ее описания, т.е. ниже по тексту. По этой причине описания статических переменных обычно выносятся в начало файла. В отличие от глобальных переменных, статические переменные никогда не описываются в h-файлах (модификаторы extern и static конфликтуют между собой). Совет: используйте статические переменные, если нужно, чтобы они были доступны только для функций, описанных внутри одного и того же файла. По возможности не применяйте в таких ситуациях глобальные переменные, это позволит избежать конфликтов имен при реализации больших проектов, состоящих из сотен файлов.
Статическую переменную можно описать и внутри функции, хотя обычно так никто не делает. Переменная размещается не в стеке, а в статической памяти, т.е. ее нельзя использовать при рекурсии, а ее значение сохраняется между различными входами в функцию. Область видимости такой переменной ограничена телом функции, в которой она определена. В остальном она подобна статической или глобальной переменной. Заметим, что ключевое слово static в языке С используется для двух различных целей:
· как указание типа памяти: переменная располагается в статической памяти, а не в стеке;
· как способ ограничить область видимости переменной рамками одного файла (в случае описания переменной вне функции).
Слово static может присутствовать и в заголовке функции. При этом оно используется только для того, чтобы ограничить область видимости имени функции рамками одного файла. Пример:
static int gcd(int x, int y); // Прототип ф-ции
. . .static int gcd(int x, int y) // Реализация(определение ф-ции)
{
. . .
}
Совет: используйте модификатор static в заголовке функции, если известно, что функция будет вызываться лишь внутри одного файла. Слово static должно присутствовать как в описании прототипа функции, так и в заголовке функции при ее реализации.
8.2. Стековая, или локальная, память
Локальные, или стековые, переменные - это переменные, описанные внутри функции. Память для таких переменных выделяется в аппаратном стеке. Память выделяется в момент входа в функцию или блок и освобождается в момент выхода из функции или блока. При этом захват и освобождение памяти происходят практически мгновенно, т.к. компьютер только изменяет регистр, содержащий адрес вершины стека.
Локальные переменные можно использовать при рекурсии (рекурсия – вызов функцией самой себя), поскольку при повторном входе в функцию в стеке создается новый набор локальных переменных, а предыдущий набор не разрушается. Программисты называют такое свойство функции реентерабельностью, от англ. re-enter able - возможность повторного входа. Это очень важное качество с точки зрения надежности и безопасности программы! Программа, работающая со статическими переменными, этим свойством не обладает, поэтому для защиты статических переменных приходится использовать механизмы синхронизации, а логика программы резко усложняется. Всегда следует избегать использования глобальных и статических переменных, если можно обойтись локальными.
Недостатки локальных переменных являются продолжением их достоинств. Локальные переменные создаются при входе в функцию и исчезают после выхода из нее, поэтому их нельзя использовать в качестве данных, разделяемых между несколькими функциями. К тому же, размер аппаратного стека не бесконечен, стек может в один прекрасный момент переполниться (например, при глубокой рекурсии), что приведет к катастрофическому завершению программы. Поэтому локальные переменные не должны иметь большого размера. В частности, нельзя использовать большие массивы в качестве локальных переменных.
8.3. Динамическая память, или куча
Помимо статической и стековой памяти, существует еще практически неограниченный ресурс памяти, которая называется динамическая, или куча (heap). Программа может захватывать участки динамической памяти нужного размера. После использования ранее захваченный участок динамической памяти следует освободить.
Под динамическую память отводится пространство виртуальной памяти процесса между статической памятью и стеком.
Структура динамической памяти автоматически поддерживается исполняющей системой языка С или C++. Динамическая память состоит из захваченных и свободных сегментов, каждому из которых предшествует описатель сегмента. При выполнении запроса на захват памяти исполняющая система производит поиск свободного сегмента достаточного размера и захватывает в нем отрезок требуемой длины. При освобождении сегмента памяти он помечается как свободный, при необходимости несколько подряд идущих свободных сегментов объединяются.
В языке С для захвата и освобождения динамической памяти применяются стандартные функции malloc и free, описания их прототипов содержатся в стандартном заголовочном файле "stdlib.h". (Имя malloc является сокращением от memory allocate - "захват памяти".) Прототипы этих функций выглядят следующим образом:
void *malloc(size_t n); // Захватить участок памяти
// размером в n байт
void free(void *p); // Освободить участок памяти с адресом p
Здесь n - это размер захватываемого участка в байтах, size_t - имя одного из целочисленных типов, определяющих максимальный размер захватываемого участка. Тип size_t задается в стандартном заголовочном файле "stdlib.h" с помощью оператора typedef. Это обеспечивает независимость текста С-программы от используемой архитектуры. В 32-разрядной архитектуре тип size_t определяется как беззнаковое целое число:
typedef unsigned int size_t;
Функция malloc возвращает адрес захваченного участка памяти или ноль в случае неудачи (когда нет свободного участка достаточно большого размера). Функция free освобождает участок памяти с заданным адресом. Для задания адреса используется указатель общего типа void *. После вызова функции malloc его необходимо привести к указателю на конкретный тип, используя операцию приведения типа. Например, в следующем примере захватывается участок динамической памяти размером в 4000 байтов, его адрес присваивается указателю на массив из 1000 целых чисел:
int *a; // Указатель на массив целых чисел
. . .a = (int *) malloc(1000 * sizeof(int));…free(a); // Освобождение выделенной памяти
Выражение в аргументе функции malloc равно 4000, поскольку размер целого числа sizeof(int) равен четырем байтам. Для преобразования указателя используется операция приведения типа (int *) от указателя обобщенного типа к указателю на целое число.
Операторы new и delete языка C++
В языке C++ для захвата и освобождения динамической памяти используются операторы new и delete. Они являются частью языка C++, в отличие от функций malloc и free, входящих в библиотеку стандартных функций С.
Пусть T - некоторый тип языка С или C++, p - указатель на объект типа T. Тогда для захвата памяти размером в один элемент типа T используется оператор new:
T *p;p = new T;
Например, для захвата восьми байтов под вещественное число типа double используется фрагмент
double *p;p = new double;
При использовании new, в отличие от malloc, не нужно приводить указатель от типа void* к нужному типу: оператор new возвращает указатель на тип, записанный после слова new. Сравните два эквивалентных фрагмента на С и C++:
double *p;p = (double*) mallos(sizeof(double)); |
double *p;p = new double; |
Конечно, второй фрагмент гораздо короче и нагляднее.
Оператор new удобен еще и тем, что можно присвоить начальное значение объекту, созданному в динамической памяти (т.е. выполнить инициализацию объекта). Для этого начальное значение записывается в круглых скобках после имени типа, следующего за словом new. Например, в приведенной ниже строке захватывается память под вещественное число, которому присваивается начальное значение 1.5:
double *p = new double(1.5);
Этот фрагмент эквивалентен фрагменту
double *p = new double;*p = 1.5;
С помощью оператора new можно захватывать память под массив элементов заданного типа. Для этого в квадратных скобках указывается длина захватываемого массива, которая может представляться любым целочисленным выражением. Например, в следующем фрагменте в динамической памяти создается массив размера m для хранения вещественных чисел:
double *a;int m = 100;a = new double[m];
Оператор delete освобождает память, захваченную ранее с помощью оператора new, например,
double *p = new double(1.5); // Захват и инициализация
. . .delete p; // Освобождение памяти
Если память под массив была захвачена с помощью векторной формы оператора new, то для ее освобождения следует использовать векторную форму оператора delete, в которой после слова delete записываются пустые квадратные скобки:
double *a = new double[100]; // Захватываем массив
. . .delete[] a; // Освобождаем массив.